Troubleshooting Java Applications on OpenShift
In this article, we go over how to check for performance issues by checking various processes such as garbage collection, resource consumption, and more.
Join the DZone community and get the full member experience.
Join For FreeOpenShift has seen a lot of traction with the release of its third version based on Kubernetes a couple of years ago. More and more companies after a thorough evaluation of OpenShift Container Platform (OCP) have built an on-premise or in the cloud PaaS. With the next step, they have started to run their applications on OCP. One of the important aspects of running applications in production is the capacity to quickly restore services to the normal service level after an incident followed by the identification and the resolution of the underlying problem. In this respect, I want to present, in this post, a few approaches for troubleshooting Java applications running on OpenShift. Similar approaches can be taken with other languages.
Debugging applications during development phase can be done thanks to features like:
- Debug mode for resolving issues during startup.
- Port forwarding for connecting an IDE like JBDS to an application running in a remote container and debugging it with breakpoints and object inspection.
This has been presented in blogs like here and here.
In this post, on the contrary, I want to focus on troubleshooting applications in production and cover things like capturing heap and thread dumps, and resource consumption per thread. These are techniques that have more than once been helpful in the past for resolving deadlocks, memory leaks, or performance degradation due to excessive garbage collection for instance.
Let’s get into the heart of the matter!
Is There Something Going On?
It all begins by noticing that there is something fishy. OpenShift provides several mechanisms for scrutinizing the health of your application.
Health and Readiness
Built-in health and readiness checks that support custom probes are the first defense mechanism. OpenShift reacts to a negative answer to the former by stopping the faulty container and starting a fresh one. The later the answer to the latter is to take the pod out of the work rotation. No request is being forwarded to the service and router layer to the faulty container.
Logs
Container logs can be accessed in several ways:
- $ oc logs <pod-name>
- the web console
- Kibana for the aggregated logs
Metrics
CPU and memory consumption is visible in the web console or accessible through Hawkular, Prometheus, or a monitoring system integrated with one of these or directly to Heapster or the kubelet API. Custom metrics can also be gathered through JMX or Prometheus-endpoints. Trends depending on the time range can be visualized on Prometheus, Hawkular, or CloudForms
JMX
Besides custom metrics, JMX also gives access to information on the JVM or on the application itself if specific MBeans have been implemented, which is the case for EAP, for instance.
Events
When a pod is killed and restarted due to out of memory or due to the health check not giving a positive answer, an event gets created, which is visible in the web console, through the CLI: “oc get events” or a monitoring system watching events.
What next?
Let’s Find the Root
Before the rise of containers when one wanted to investigate memory leaks, deadlocks, or garbage collections impacting performance, a few well-known techniques allowed us to capture the information required for improving the situation, like:
- thread dumps
- heap dumps
- capture of thread resource consumption (RAM, CPU)
- analysis of garbage collection cycles (duration and frequency)
Techniques for capturing static states through snapshots at critical points in time or a series of snapshots for getting the evolution have been described in articles like this or this.
The good news is that all this can be done with containers running on OpenShift with little difference. Let’s look at that in more detail.
MBeans: The Java Console
The xPaaS images deploy the Jolokia library providing a REST API fronting JMX. This can also be used with other Java applications. If the container has a port named “Jolokia,” a link to the Java Console is displayed in the pod page of the OpenShift Web Console.
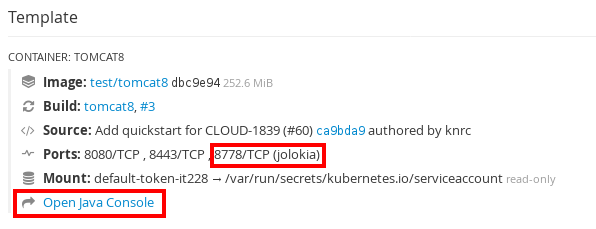 Figure 1: Link to the Java Console
Figure 1: Link to the Java Console
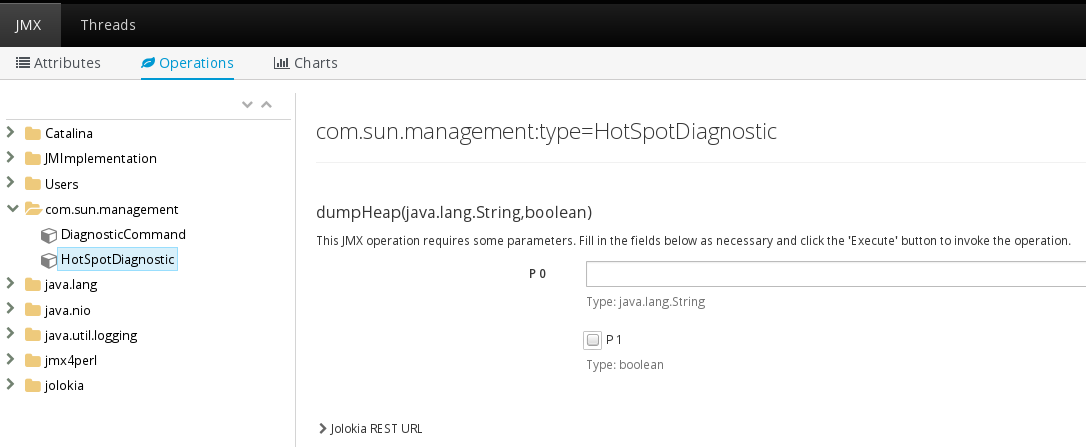 Figure 2: Java Console
Figure 2: Java Console
Here are a few MBean operations that are useful for our purpose.
- HotSpotDiagnostic.dumpHeapcom.sun.management.HotSpotDiagnostic MBean allows you to take heap dumps through the method dumpHeap (the page also provides the URL for it). The method takes two arguments:
- outputFile – the system-dependent file name
- live – if true, dump only live objects, i.e. objects that are reachable from others.
- DiagnosticCommand.gcClassHistogrammcom.sun.management.DiagnosticCommand.gcClassHistogramm provides the heap histogram, which is useful to see the classes and the number of their instances that have been loaded in memory.
- DiagnosticCommand.threadPrintcom.sun.management.DiagnosticCommand.threadPrint is a convenient way of getting a thread dump.
- GarbageCollector.LastGcInfocom.sum.management.LastGcInfo provides information on garbage collection. Especially interesting is how often they happen and how long they last.
Other MBeans may provide valuable information depending on the investigation.
Command Line
It is possible to gather information similar to what has been described in the previous chapter through the command line. Therefore, the name of the pod and possibly the name of the containers need first to be retrieved:
$ oc get pods -n test
NAME READY STATUS RESTARTS AGE
tomcat8-4-37683 1/1 Running 2 4d
$ oc describe pod tomcat8-4-37683
Name:tomcat8-4-37683
Namespace:test
Security Policy:restricted
Node:osenode3.sandbox.com/192.168.122.143
Start Time:Wed, 02 Aug 2017 22:07:15 +0200
Labels:app=tomcat8
deployment=tomcat8-4
deploymentconfig=tomcat8
Status:Running
IP:10.128.1.3
Controllers:ReplicationController/tomcat8-4
Containers:
tomcat8:The examples below will be given for the pod tomcat8-4-37683 with IP address 10.128.1.3 and container name tomcat8. This needs to be changed to the values specific to the pod and container the application is running on.
Memory Dump
If the JDK is available inside the container, jcmd (previously jmap) can be used. In many companies, for security reasons (reducing the attack surface) only JREs are installed on production machines. In that case, though it is a bit trickier, gdb may not be available in your container to take a core dump, from which a memory dump can be extracted with jmap. The only approach I am aware of is using the JMX API through Jolokia. In most of the cases, your Java process will be the only process running inside the container and will have the id 1.
Note: It is important to be aware that taking a heap dump will freeze the JVM and impact the application performance. An option to limit the impact is to only take a histogram.
Here is how this can be done with jcmd.
jcmd
$ oc exec tomcat8-4-37683 -c tomcat8 -- jcmd 1 GC.heap_dump /tmp/heap.hprof \
oc rsync tomcat8-4-37683:/tmp/heap.hprof . \
oc exec tomcat8-4-37683 -- rm /tmp/heap.hprof
$ oc exec tomcat8-4-37683 -c tomcat8 -- jcmd 1 GC.class_histogramWith Jolokia, it is a bit more involved from the command line. The following examples that connect directly to the pods are to be run from the master where the required certificates and the connectivity are available. Alternatively, the master can be used as a reverse proxy, only for GET requests as far as I have seen. As part of a monitoring solution, one should also be careful not to put unnecessary load on the master.
Jolokia
Direct connection
$ curl -k -H "Authorization: Bearer $(oc sa get-token management-admin -n management-infra)" \
-H "Content-Type: application/json" \
--cert /etc/origin/master/master.proxy-client.crt \
--key /etc/origin/master/master.proxy-client.key \
'https://10.128.1.3:8778/jolokia/' \
-d '{"mbean":"com.sun.management:type=HotSpotDiagnostic", "operation":"dumpHeap", "arguments":["/tmp/heap.hprof","true"], "type":"exec"}' \
oc rsync tomcat8-4-37683:/tmp/heap.hprof . \
oc exec tomcat8-4-37683 -- rm /tmp/heap.hprof
$ curl -k -H "Authorization: Bearer $(oc sa get-token management-admin -n management-infra)" \
-H "Content-Type: application/json" \
--cert /etc/origin/master/master.proxy-client.crt \
--key /etc/origin/master/master.proxy-client.key \
'https://10.128.1.3:8778/jolokia/' \
-d '{"mbean":"com.sun.management:type=DiagnosticCommand", "operation":"gcClassHistogram", "arguments":["-all"], "type":"exec"}' \
| sed 's/\n/\n/g' > histogram.hprof
Using the master as reverse proxy
$ curl -H "Authorization: Bearer $(oc whoami -t)" \
-H "Content-Type: application/json" \
'https://osemaster.sandbox.com:8443/api/v1/namespaces/test/pods/https:tomcat8-4-37683:8778/proxy/jolokia/exec/com.sun.management:type=HotSpotDiagnostic/dumpHeap/!/tmp!/heap.hprof/true' \
oc rsync tomcat8-4-37683:/tmp/heap.hprof . \
oc exec tomcat8-4-37683 -- rm /tmp/heap.hprof
$ curl -H "Authorization: Bearer $(oc whoami -t)" \
-H "Content-Type: application/json" \
https://osemaster.sandbox.com:8443/api/v1/namespaces/test/pods/https:tomcat8-4-37683:8778/proxy/jolokia/exec/com.sun.management:type=DiagnosticCommand/gcClassHistogram/-all | sed 's/\n/\n/g' > histogram.hprofThe analysis of the memory dump can be performed with Eclipse Memory Analyzer Tool (MAT):
http://www.eclipse.org/mat/
Thread Dump
Apart from jcmd (previously jstack), it is also possible to take a thread dump by sending the SIGQUIT(3) signal to the Java process.
jcmd
$ oc exec tomcat8-4-37683 -c tomcat8 -- jcmd 1 Thread.printKill signal
$ oc exec tomcat8-4-37683 -c tomcat8 -- kill -3 1Note: This won’t terminate the Java process unless it was started with -Xrs, which disables signal handling in the JVM. The thread dump is written to the standard output, which is redirected to the container logs. The result can be seen with:
$ oc logs tomcat8-4-37683
[...]
Full thread dump OpenJDK 64-Bit Server VM (25.131-b12 mixed mode):
"Attach Listener" #24 daemon prio=9 os_prio=0 tid=0x00007ff2f4001000 nid=0x36 runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"Thread-6" #23 daemon prio=5 os_prio=0 tid=0x00007ff2e8003800 nid=0x26 waiting on condition [0x00007ff2ec3fa000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000d3b4e070> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
[...]Jolokia
Direct connection
$ curl -k -H "Authorization: Bearer $(oc sa get-token management-admin -n management-infra)" \
-H "Content-Type: application/json" \
--cert /etc/origin/master/master.proxy-client.crt \
--key /etc/origin/master/master.proxy-client.key \
'https://10.128.1.3:8778/jolokia/' \
-d '{"mbean":"com.sun.management:type=DiagnosticCommand", "operation":"threadPrint", "arguments":["-l"], "type":"exec"}' \
| sed 's/\n/\n/g' | sed 's/\t/\t/g' > thread.out
Using the master as reverse proxy
$ curl -H "Authorization: Bearer $(oc whoami -t)" \
-H "Content-Type: application/json" \
'https://osemaster.sandbox.com:8443/api/v1/namespaces/test/pods/https:tomcat8-4-37683:8778/proxy/jolokia/exec/com.sun.management:type=DiagnosticCommand/threadPrint/-l' \
| sed 's/\n/\n/g' | sed 's/\t/\t/g' > thread.outResource Consumption
It is often convenient to see how many resources are being consumed by each of the threads listed by the previous command. This can easily be done with the top command:
$ oc exec tomcat8-4-37683 -c tomcat8 -- top -b -n 1 -H -p 1 > top.out
$ cat top.out
top - 07:16:34 up 19:50, 0 users, load average: 0.00, 0.08, 0.12
Threads: 23 total, 0 running, 23 sleeping, 0 stopped, 0 zombie
%Cpu(s): 2.4 us, 0.7 sy, 0.0 ni, 96.7 id, 0.1 wa, 0.0 hi, 0.1 si, 0.0 st
KiB Mem : 2915764 total, 611444 free, 1074032 used, 1230288 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 1622968 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 1000060+ 20 0 3272048 272060 16084 S 0.0 9.3 0:00.03 java
15 1000060+ 20 0 3272048 272060 16084 S 0.0 9.3 0:09.97 java
16 1000060+ 20 0 3272048 272060 16084 S 0.0 9.3 0:00.14 javaThe 9th column shows the CPU consumption and the 10th column shows the memory, one per thread.
Using the thread dump analyzer, it is possible to map resource consumption with thread information through the thread id (native-id in TDA).
Additional information on TDA can be found here.
If you don’t want to use a tool, you will need to convert the thread id to hexadecimal to match the nid field in the thread dump. Something like this should do the job:
$ echo "obase=16; <thread-id>" | bcGarbage Collections
Frequent and long lasting garbage collections may be a symptom of an issue with the application. Full garbage collection may also add unacceptable latency to request processing as it “stops the world.” Information gathering on garbage collection is another frequent activity related to troubleshooting performance issues and optimization.
Jstat
Jstat is often used to capture information on garbage collection. Unfortunately, it does not work out of the box with lots of images on OpenShift. The reason for that is that Java stores relevant information in the file /tmp/hsperfdata_. Containers on OpenShift run per default with a high number user id, something like 1000060000 and containers in different projects use different user ids. This is for security reasons: this user id won’t match any real user on the host system. It adds an additional protection layer. A consequence of this dynamic allocation of user ids is that there is no match for them in /etc/passwd inside the container, hence the data cannot be stored by the Java process into /tmp/hsperfdata_. There are workarounds. One is to have a writable /etc/passwd, which is updated at startup. A finer approach is to use an nss wrapper. Jstat will work, for instance, out of the box with the Jenkins image here.
jstat
$ oc exec tomcat8-4-37683 -- jstat -gcutil 1 10000 5 > jstat.outJolokia
Direct connection
$ curl -k -H "Authorization: Bearer $(oc sa get-token management-admin -n management-infra)" \
-H "Content-Type: application/json" \
--cert /etc/origin/master/master.proxy-client.crt \
--key /etc/origin/master/master.proxy-client.key \
'https://10.129.0.2:8778/jolokia/' \
-d '{"mbean":"java.lang:type=GarbageCollector,name=PS MarkSweep", "attribute":"LastGcInfo", "type":"read"}'
$ curl -k -H "Authorization: Bearer $(oc sa get-token management-admin -n management-infra)" \
-H "Content-Type: application/json" \
--cert /etc/origin/master/master.proxy-client.crt \
--key /etc/origin/master/master.proxy-client.key \
'https://10.129.0.2:8778/jolokia/' \
-d '{"mbean":"java.lang:type=GarbageCollector,name=PS Scavenge", "attribute":"LastGcInfo", "type":"read"}'
Using the master as reverse proxy
$ curl -H "Authorization: Bearer $(oc whoami -t)" \
-H "Content-Type: application/json" \
'https://osemaster.sandbox.com:8443/api/v1/namespaces/test/pods/https:tomcat8-4-37683:8778/proxy/jolokia/read/java.lang:type=GarbageCollector,name=PS%20MarkSweep/LastGcInfo
$ curl -H "Authorization: Bearer $(oc whoami -t)" \
-H "Content-Type: application/json" \
'https://osemaster.sandbox.com:8443/api/v1/namespaces/test/pods/https:tomcat8-4-37683:8778/proxy/jolokia/read/java.lang:type=GarbageCollector,name=PS%20Scavenge/LastGcInfoEvolution in Time
If no monitoring solution is in place to gather information required for troubleshooting, the commands above can easily be grouped into a script that gets launched at regular intervals to see the dynamic aspects: objects, thread creation, the evolution of memory and CPU consumption, etc. As the creation of a complete heap dump is intrusive, it is recommended to limit the memory capture to histograms.
Shooting Oneself in the Foot
One issue that operation teams often face is that the resolution of an incident has consequences such that the data, which could have been used for identifying the root cause and fixing the underlying problem, is lost. ITIL theory says:
- The objective of the Incident Management Lifecycle is to restore the service as quickly as possible to meet SLA.
- The objective of the Problem Management function is to identify the underlying causal factor, which may relate to multiple incidents.
In the case of a dead lock or performance degradation due to a memory leak, the response is often to restart the application to restore it to a sane state as quickly as possible. Unfortunately, by doing that, you have just deleted the application state that could have provided you critical information for the resolution of the underlying problem.
Ideally, your application would run with more than a single instance for high availability, but even if it were not the case, the following approach would help. The rationale is pretty simple: instead of killing the faulty container you would just take it out of the request serving pool, and the service and route layers in OpenShift. This, unfortunately, would not help if the application was, for instance, consuming from a messaging system. Services and Routes know the pods the requests are to be sent to based on a label/selector mechanism. You just need to change the label on the faulty pod for taking it out of the pods backing the service and processing requests. Let’s look at how it can be done with a quick start.
- Create an application.
$ oc new-app --name=myapp jboss-webserver30-tomcat8-openshift~https://github.com/openshiftdemos/os-sample-java-web.git - Scale the deployment to two instances (optional)
$ oc scale dc myapp --replicas=2 - Change the label on the “faulty” pod
$ oc get pods
NAME READY STATUS RESTARTS AGE
myapp-1-build 0/1 Completed 0 3m
myapp-1-gd2fn 1/1 Running 0 1m
myapp-1-q1k3n 1/1 Running 0 2m
$ oc describe service myapp
Name:myapp
Namespace:test
Labels:app=myapp
Selector:app=myapp,deploymentconfig=myapp
Type:ClusterIP
IP:172.30.225.169
Port:8080-tcp8080/TCP
Endpoints:10.128.1.6:8080,10.129.0.250:8080
Port:8443-tcp8443/TCP
Endpoints:10.128.1.6:8443,10.129.0.250:8443
Port:8778-tcp8778/TCP
Endpoints:10.128.1.6:8778,10.129.0.250:8778
$ oc label pod myapp-1-gd2fn --overwrite deploymentconfig=mydebug
pod "myapp-1-gd2fn" labeled
$ oc get pods
NAME READY STATUS RESTARTS AGE
myapp-1-build 0/1 Completed 0 8m
myapp-1-gd2fn 1/1 Running 0 5m
myapp-1-gtstj 1/1 Running 0 5s
myapp-1-q1k3n 1/1 Running 0 7m
$oc describe service myapp
Name:myapp
Namespace:test
Labels:app=myapp
Selector:app=myapp,deploymentconfig=myapp
Type:ClusterIP
IP:172.30.225.169
Port:8080-tcp8080/TCP
Endpoints:10.128.1.7:8080,10.129.0.250:8080
Port:8443-tcp8443/TCP
Endpoints:10.128.1.7:8443,10.129.0.250:8443
Port:8778-tcp8778/TCP
Endpoints:10.128.1.7:8778,10.129.0.250:8778Immediately after changing the label, OpenShift starts a new pod to satisfy the deployment configuration requirement: to have two running instances → incident resolved. The faulty container is, however, still running, isolated. You can see in the output above that the new one with the IP 10.128.1.7 in the list of endpoints in the service component has replaced the container with the IP 10.128.1.6.
The service layer is per default implemented through iptables. It is easy to see that the faulty pod is taken out of the service forwarding:
$ iptables -L -n -t nat | grep test/myapp:8080
KUBE-MARK-MASQ all -- 10.129.0.250 0.0.0.0/0 /* test/myapp:8080-tcp */
DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 /* test/myapp:8080-tcp */ tcp to:10.129.0.250:8080
KUBE-MARK-MASQ all -- 10.128.1.7 0.0.0.0/0 /* test/myapp:8080-tcp */
DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 /* test/myapp:8080-tcp */ tcp to:10.128.1.7:8080In a similar way, it is possible in OpenShift to look at the HAProxy configuration and see that it has been actualized. You would need to log into the router (“oc rsh “) for that. Here is the relevant part in the configuration file:
/var/lib/haproxy/conf/ haproxy.config
# Plain http backend
backend be_http_test_myapp
[...]
server 625c4787bdcee4668557b3d7edb1c168 10.128.1.7:8080 check inter 5000ms cookie 625c4787bdcee4668557b3d7edb1c168 weight 100
server 4c8bc31e32a06e7a7905c04aa02eb97b 10.129.0.250:8080 check inter 5000ms cookie 4c8bc31e32a06e7a7905c04aa02eb97b weight 100Now that the incident has been resolved, we can use some of the techniques described previously to troubleshoot the application and resolve the problem. When you are finished, the pod can just be killed.
$ oc delete pod myapp-1-gd2fnIf you decided to label it back to the previous value instead, the replication controller would notice that there is one pod more than the desired number and would kill one of them to come back to the desired state.
That’s it!
Published at DZone with permission of Frederic Giloux. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments