Type Variance in Java and Kotlin
Explaining how type variance works with Java and Kotlin by using simple and complex examples and how it can be used to create good APIs for developers.
Join the DZone community and get the full member experience.
Join For Free“There are three kinds of variance: invariance, covariance, and contravariance…”
It looks pretty scary already, doesn’t it? If we search Wikipedia, we will find covariance and contravariance in category theory and linear algebra. Some of you who learned these subjects in university might be having dreadful flashbacks because it can be complex stuff.
Because these terms look so scary, people avoid learning this topic regarding programming languages. From my experience, many middle-level and sometimes senior-level Java and Kotlin developers fail to understand type variance. This leads to a poor design of internal APIs because to create convenient APIs using generics, you need to understand type variance, otherwise, you either don’t use generics at all or use them incorrectly. It is all about creating better APIs.
If we compare a program to a building, then its internal API is the foundation of the building. If your internal API is convenient, then your code is more robust and maintainable. So let’s fill this gap in our knowledge.
The best way to explain this topic is with a historical and evolutionary perspective. I will start by considering examples from ancient and primitive concepts such as arrays that appeared in early Java versions, through Java Collections API, and finally, Kotlin, which has an advanced type variance. Going from simple to more complex examples, you’ll see how language features have evolved and what problems were solved by introducing these language features.
After reading this article no mysteries will remain about Java’s “? extends,” “? super,” or Kotlin’s “in” and “out.”
For illustration purposes, I’ll be using the same example of type hierarchy everywhere:

We have a base class called Person, a subclass called Employee, and another subclass called Manager. Each Employee is a Person, each Manager is a Person, and each Manager is an Employee, but not necessarily vice versa: some of the Persons are not Employees.
In Java and Kotlin, this means you can assign an expression of type Manager to a variable of type Employee and so on, but not vice versa.
We will also consider a lot of code examples and for all of them, we’re interested in only four kinds of possible outcomes. We will use emojis to identify them:
|
The code won’t compile. |
|
The code will compile and run, but there will be a runtime exception. |
|
The code will compile and run normally. |
|
The heap pollution will occur. |




Heap pollution is a situation where a variable of a certain type contains an object of the wrong type. For example, a variable declared as a String refers to an instance of a Manager or Employee. Yes, it is what it looks like: a flaw in the language’s type system. In general, this should not happen, but this sometimes happens both in Java and in Kotlin, and I’ll show you an example of heap pollution as well.
Covariance of Reified Java Arrays
Arrays have been present in Java for more than twenty-five years, starting from Java 1.0, and in a way, we can consider arrays as a prototype for generics. For example, when we have a Manager type, we can build an array Manager[] and by getting elements of this array, we are getting values of the Manager type.
It is trivial about the types of variables that we get from the array, but what about assigning the values to the array’s elements? Can we assign a Manager as an element of Employee[]? And what about the Person?
All of the possible combinations are represented in the table below. Have a look and try to figure out what is going on:
 The result of assigning a value to an element of a Java array
The result of assigning a value to an element of a Java array
The rightmost column is green because in Java null can be assigned (and returned) everywhere.
In the lower-left corner, we have cases that won’t compile, which also makes sense: you cannot assign a Person to an Employee or Manager without an explicit type cast, and thus, you cannot set a Person as an element of an array of employees or managers. That’s the main idea of type checking!
Everything was understandable so far, but what about the rest of the combinations? We would expect that assigning an Employee to an element of Employee[], Person[], or Object[] will cause no problems, just as assigning it to a variable of type Employee, Person, or Object. What do these exclamation marks mean? A runtime exception? Why? What is this exception and what can go wrong?
I will explain this soon.
Meanwhile, let’s consider another question: Can we assign a Java array of a given type to an array of another type? That is, can we assign Employee[] to Person[]? And vice versa?
All the possible combinations are given in the following table:

Can we assign a Java array of a given type to an array of another type?
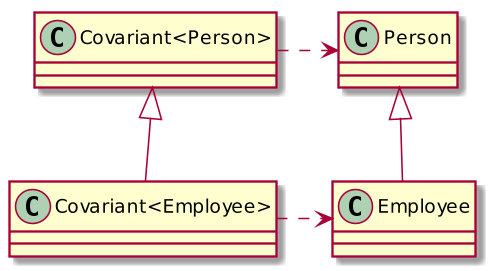
We could remove square brackets and this would give us a table of possible assignments of simple objects: Employee is assignable to Person, but Person is not assignable to Employee. Since each Manager is an Employee, then an array of managers is an array of employees, right? At this point, we can already say that arrays in Java are covariant against the types of their elements, but we will go back to strict terms soon. The following UML diagram is valid:

Now have a look at the code below to see how it behaves:
Manager[] managers = new Manager[10];
Person[] persons = managers; //this should compile and run
persons[0] = new Person(); //line 1 ??
Manager m = managers[0]; //line 2 ?!Nothing special happens in the beginning. Since the Manager is a Person, the assignment is possible. But since arrays, just like any objects, are reference types in Java, both manager and person variables keep the reference to the same object. On line 1, we are trying to insert a Person into this array.
Note: the compiler type-checking cannot prevent us from doing this. But if this line is allowed to be executed, then, on line 2, we should expect a catastrophic error: an array of Managers will contain someone who is not a Manager—in other words, heap pollution.
But Java won’t let you do it here. Experienced Java developers might know that an ArrayStoreException will occur on line 1. To prevent heap pollution, an array object “knows” the type of its elements in runtime, and each time we assign a value, a runtime check is performed. This explains the exclamation marks in one of the previous tables: writing a non-null value to any Java array, generally speaking, may lead to an ArrayStoreException if the actual type of the array is the subtype of the array variable.
The ability of a container to “know” the type of its elements is called “reification.” So now we know that arrays in Java are covariant and reified.
To sum up, we may say that:
- The need for arrays reification and runtime check (and possible runtime exceptions) comes from the covariance of arrays (the fact that the
Manager[]array can be assigned toPerson[]). - Covariance is safe when we read values, but can lead to problems when we write values. Note: the problem is so huge that Java even abandoned the main static language objective here, that is to have all the type checking in compile time, and behaves more like a dynamically-typed language (e.g., Python) in this scenario.
You might ask:
- “Was covariance the right choice for Java arrays?”
- “What if we just prohibit the assignment of arrays of different types?”
In this case, it would have been impossible to assign Manager[] to Person[], we would have known the array elements type at compile time, and there would have been no need to resort to run-time checking.
The ability of the type to be assignable only to the variables of the same type strictly is called invariance, and we will discover it in Java and Kotlin generics very soon. But imagine the problems that the invariance of arrays would have led to in Java.
Imagine we have a method that accepts a Person[] as its argument and calculates, for example, the average age of the given people:
Double calculateAverageAge(Person[] people)Now we have a variable of type Manager[]. Managers are people, but can we pass this variable as an argument for calculateAverageAge?
In Java we can because of the covariance of arrays. If arrays were invariant, we would have to create a new array of type Person[], copy all the values from Manager[] to this array, and only then call the method. The memory and CPU overhead would have been enormous.
This is why invariance is impractical in APIs, and this is the real reason why Java arrays are covariant (although covariance implies difficulties with value assignments). The example of Java arrays shows the full range of problems associated with type variance. Java and Kotlin generics tried to address these problems.
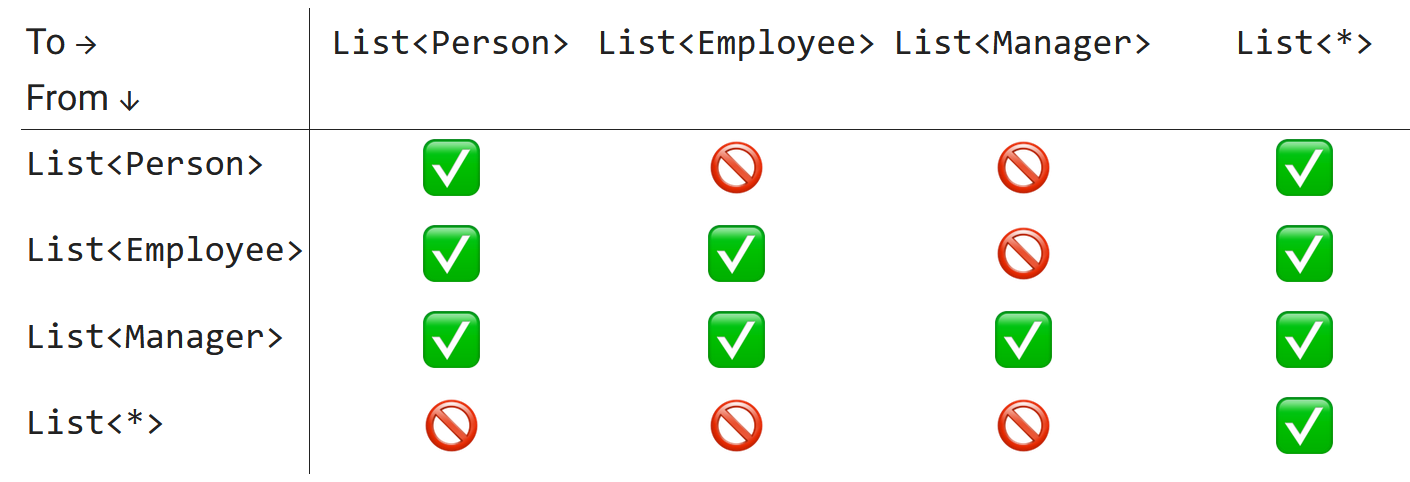
Invariance of Java and Kotlin Mutable Lists
I believe you are familiar with the concept of generics. In Java and Kotlin, given that list is not empty, we will have the following return types of list.get(0):
type of list |
type of list.get(0) |
List<Person> |
Person |
List<?> |
Object |
List<*> |
Any? |
The difference between Java and Kotlin is in the last two lines. Both Java and Kotlin have a notion of an “unknown” type parameter: both List<?> in Java and List<*> in Kotlin denote “a List of elements of some type, and we don’t know/don’t care what the type is.” In Java, everything is nullable, thus the Object type returned by list.get(...) can be null. In Kotlin, we have to care about nullability, thus get the method for List<*> returns Any?
Now, let’s build the same tables we have previously built for Java arrays. First, let’s consider the assignment of elements. Here we will find a huge difference between Java and Kotlin Collections API (and as we will discover very soon, this difference is tightly related to the difference between type variance in Java and Kotlin). In Java, every List has methods for its modification (add, remove, and so on).
The difference between mutable and immutable collections in Java is visible only in runtime. We may have UnsupportedModificationException if we try to change an immutable list. In Kotlin, mutability is visible at compile time. The List interface itself does not have any modification methods, and if we want mutability, we need to use MutableList.
In other respects, List<..> in Java and MutableList<..> in Kotlin are nearly the same. Here are the results of the list.add(…) method in Java and Kotlin:

What is the result of list.add(…) method in Java and Kotlin?
Why we cannot add a null to MutableList<*> is understandable: “star” may mean any type, both nullable and non-nullable. Since we don’t know anything about the actual type and its nullability, we cannot allow adding nullable values to MutableList<*>.
Note: we don’t have anything similar to ArrayStoreException, although the table looks similar to the one we have built for arrays so far. Now, let’s try to figure out when we can assign Java and Kotlin lists to each other. All the possible combinations are presented here:

Can we assign these lists to each other?
The rightmost green column means that List<?>/MutableList<*> are universally assignable: since we “don’t care” about the actual type parameter, we can assign anything. In the rest of the diagram, we see the green diagonal, which means that MutableList<...> can be assigned only to a MutableList parameterized with the same type. In other words, List<T> in Java and MutableList<T> in Kotlin are invariant against the type parameters.
This cuts off the possibility of insertion of elements of the wrong type already in compilation time:
List<Manager> managers = new ArrayList<>();
List<Person> persons = managers; //won't compile
persons.add(new Person()); //no runtime check is possibleTwo concerns may arise at this point:
- As we know from the Java arrays example, invariance is bad for building APIs. What if we need a method that processes
List<Person>, but can be called withList<Manager>without having to copy the whole list element by element? - Why not implement everything the same way as for arrays?
The answer for the first concern is the declaration site and use site variance that we are going to consider soon. The answer to the second question is that, unlike arrays, which are reified, generics in Java and Kotlin are type erased, which means they have no information about their type parameters in run time, and run-time type checking is impossible. Let’s dive deeper into type erasure now.
Type Erasure, Generics/Arrays Incompatibility, and Heap Pollution
One of the reasons why the Java platform implements generics via type erasure is purely historical. Generics appeared in Java version 5 when the Java platform already was quite mature. Java keeps backward compatibility at the source code and bytecode level, which means that very old source code can be compiled in modern Java versions, and very old compiled libraries can be used in modern applications by placing them on the classpath. To facilitate an upgrade to Java 5, the decision had been made to implement Generics as a language feature, not a platform feature.
This means that in run time JVM doesn’t know anything about generics and their type parameters. For example, a simple Pair<T> class is compiled to byte code in the following way (type parameter T is “erased” and replaced with Object):
| Generic Type (Source) | Raw Type (compiled) |
|
Java
|
Java
|
Or, if we use bounded types in the generic type definition, the type parameter is replaced with boundary type:
| Generic Type (source) | Raw Type (compiled) |
|
Java
|
Java
|
This implies many strict and sometimes counterintuitive limitations on how we can use generics in Java and Kotlin. If you want to know more details (e.g. if you want to know more about bounded types, and know what “bridge methods” are), you can refer to my lecture on Java Generics titled Mainor 2022: Java Generics. But the most important restriction is the following: neither in Java nor Kotlin can we determine the type parameter in the runtime.
In the following situation,
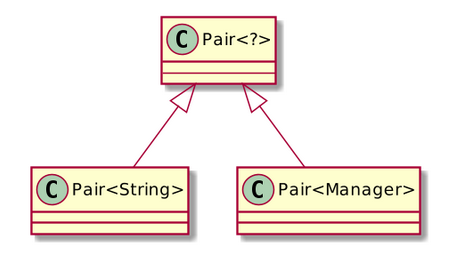
These code snippets won’t compile:
| Java | Kotlin |
|
Java
|
Kotlin
|
But these will compile and run successfully, although probably we would like to know more about a:
| Java | Kotlin |
|
Java
|
Kotlin
|
An important implication of this is Java arrays and generic incompatibility. For example, the following line wont compile in Java with the error “generic array creation:”
List<String>[] a = new ArrayList<String>[10];As we know, Java arrays need to keep the full type information in runtime, while all the information that will be available in this case is that it is an array of ArrayList of something unknown (“String” type parameter will be erased).
Interestingly, we can overcome this protection and create an array of generics in Java (either via type cast or varargs (variable arguments) parameter), and then easily make heap pollution with it.
But let’s consider another example. It doesn’t involve Java arrays and thus it is possible both in Java and Kotlin:
| Java | Kotlin |
|
Java
|
Kotlin
|
| An example of heap pollution. A chimera appears!
|
|

First, we create a pair of integers. Then we “forget” its type in compile time and through explicit typecast we are casting it to a pair of Strings.
Note: we cannot cast intPair to stringPair straightforwardly: Integer cannot be cast to String, and the compiler will warn us about it. But we can do this via Pair<?> / Pair <*>: although there will be a warning about unsafe typecast, the compiler won’t prohibit the typecast in this scenario (we can imagine a Pair<String> casted to Pair<?> and then explicitly casted back to Pair<String>).
Then something weird happens: we assign a String to the second component of our object, and this code is going to compile and run. It compiles because the compiler “thinks” that b has a type of String. It runs because in runtime there are no checks, and the type of b is Object. After the execution of this line, we have a “chimera” object: its first variable is Integer, its second variable is String, and it’s neither Pair<String> nor Pair<Integer>. We’ve broken the type safety of Java and Kotlin and made heap pollution.
To sum up:
- Because of type erasure, it’s impossible to perform type checking of objects passed to generics in run time.
- It’s unsafe to store type-erased generics in Java native reified arrays.
- Both Java and Kotlin languages permit heap pollution: a situation where a variable of some type refers to an object that is not of that type.
Use Site Covariance
Imagine we are facing the following practical task: we are implementing a class MyList<E>, and we want it to have the ability to add elements from other lists via the addAllFrom method and the ability to add its elements to another list via addAllTo.
Since we have the usual Manager – Employee – Person inheritance chain, these must be the valid and invalid options:
MyList<Manager> managers = ...
MyList<Employee> employees = ...
//Valid options, we want these to be compilable!
employees.addAllFrom(managers);
managers.addAllTo(employees);
//Invalid options, we don't want these to be compilable!
managers.addAllFrom(employees);
employees.addAllTo(managers);A naive approach (the one that, unfortunately, I’ve seen many times in real life projects) is to use type parameters straightforwardly:
class MyList<E> implements Iterable<E> {
void add(E item) { ... }
//Don't do this :-(
void addAllFrom(MyList<E> list) {
for (E item : list) this.add(item);
}
void addAllTo(MyList<E> list) {
for (E item : this) list.add(item);
}
...}Now, when we try to write the following code, it will not compile.
MyList<Manager> managers = ...; MyList<Employee> employees = ...;
employees.addAllFrom(managers); managers.addAllTo(employees);I often see people struggling with this: they tried to introduce generic classes in their code, but these classes were unusable. Now we know why this happens: it is due to the invariance of MyList. We have figured out that due to the lack of runtime type-checking, type invariance is the best that can be done for type safety of Java’s List/ Kotlin’s MutableList.
Both Java and Kotlin offer a solution for this problem: to create convenient APIs, we need to use wildcard types in Java or type projections in Kotlin.
Let’s look at Java first:
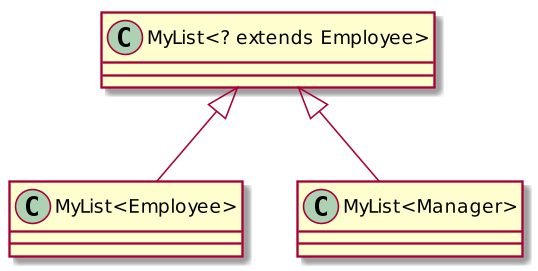
class MyList<E> implements Iterable<E> {
void addAllFrom (List<? extends E> list){
for (Е item: list) add(item); }
}
MyList<Manager> managers = ...; MyList<Employee> employees = ...
employees.addAllFrom(managers);List<? extends E> means: “a list of any type will do as soon as this type is a subtype of E.” When we iterate over this list, the items can be safely cast to “E.” And since our list is a list of “E,” then we can safely add these elements to our list. The program will compile and run.
In Kotlin, this looks very similar, but instead of “? extends E,” we are using “out E:”
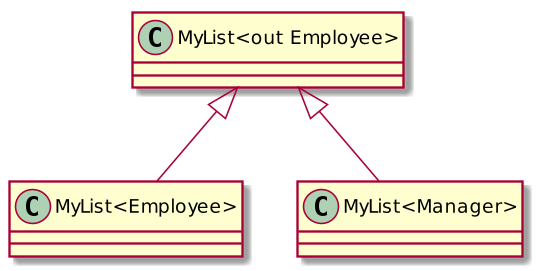
class MyList<E> : Iterable<E> {
fun addAllFrom(list: MyList<out E>) {
for (item in list) add(item) }
}
val managers: MyList<Manager> = ... ; val employees: MyList<Employee> = ...
employees.addAllFrom(managers)By declaring <? extends E> or <out E> are making the type of the argument covariant. But to avoid heap pollution, this implies certain limitations to what can be done with the variable declared with wildcard types/type projections.
One of my favourite questions for a Java technical interview is: given a variable declared as
List<? extends E> listin Java, what can be done with this variable?
- Of course, we can use
list.get(...), and the return type will beE. - On the other hand, if we have a variable
Eelement, we cannot uselist.add(element): such code won’t compile. Why? We know that the list is a list of elements of some type which is a subtype ofE. But we don’t know what subtype. For example, ifEisPerson, then? extends Emight beEmployeeorManager. We cannot blindly append aPersonto such a list then. - An interesting exception:
list.add(null)will compile and run. This happens becausenullin Java is assignable to a variable of any type, and thus it is safe to add it to any list.
We can also use an “unbounded wildcard” in Java, which is just a question mark in triangular braces, like in Foo<?>. The rules for it are as follows:
- If
Foo<T extends Bound>, thenFoo<?>is the same asFoo<? extends Bound>. - We can read elements, but only as
Bound(orObject, if noBoundis given). - If we’re using intersection types
Foo<T extends Bound1 & Bound2>, any of the bound types will do. - We can put only
nullvalues.
What about covariant types in Kotlin? Unlike Java, nullability now plays a role. If we have a function parameter with a type MyList<out E?>:
- We can read values typed
E?. - We cannot add anything.
- Even
nullwon’t do because, although we have nullableE?,outmeans any subtype. In Kotlin, a non-nullable type is a subtype of a nullable type. So the actual type of the list element might be non-nullable, and this is why Kotlin won’t let you add an even null to such a list.
Use Site Contravariance
We’ve been talking about covariance so far. Covariant types are good for reading values and bad for writing. What about contravariance? Before figuring out where it might be needed, let’s have a look at the following diagram:

Unlike in covariant types, subtyping works the other way around in contravariant ones, and this makes them good for writing values, but bad for reading.
The classical example of a use case for contravariance is Predicate<E>, which is a functional type that takes E as an argument and returns a boolean value.
The wider the type of E in a predicate, the more “powerful” it is. For example, Predicate<Person> can substitute Predicate<Employee> (because Employee is a Person), and thus it can be considered as its subtype. Of course, everything is invariant in Java and Kotlin by default, and this is why we need to use another kind of wildcard type and type projections.
The addAllTo method of our MyList class can be implemented the following way:
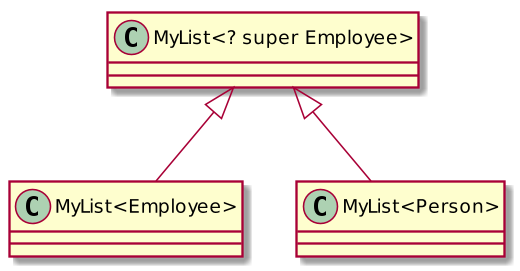
class MyList<E> implements Iterable<E> {
void addAllTo (List<? super E> list) {
for (Е item: this) list.add(item); }
}
MyList<Employee> employees = ...; MyList<Person> people = ...;
employees.addAllTo(people);List<? super E> means “a list of any type will do as soon as this type is E or a supertype of E, up to Object.” When we iterate over our list, our items, which have type E, can be safely cast to this unknown type and can be safely added to another list. The program will compile and run.
In Kotlin it looks the same, but we use MyList<in E> instead of MyList<? super E>:

class MyList<E> : Iterable<E> {
fun addAllTo(list: MyList<in E>) {
for (item in this) list.add(item) }
}
val employees: MyList<Employee> = ... ; val people: MyList<Person> = ...
employees.addAllTo(people)What Can Be Done With an Object Typed List<? super E> in Java?
- When we have an element of type
E, we can successfully add it to this list. - The same works for
null.nullcan be added everywhere in Java. - We can call
get(..)method for such a list, but we read its values only asObjects. Indeed,<? super E>means that the actual type parameter is unknown and can be anything up toObject, soObjectis the only safe assumption about the type oflist.get(..).
And what about Kotlin? Again, nullability plays a role. If we have a parameter list: MyList<in E>, then:
- We can add elements of type
Eto the list. - We cannot add nulls (but we can add nulls if the variable is declared like
MyList<in E?>).
The type of its elements (e. g. the type of list.first()) is Any? – mind the question mark. In Kotlin, “Any?” is a universal supertype, while “Any” is a subtype of “Any?”. If a type is contravariant, it can always potentially hold nulls.
PECS
The Mnemonic Rule for Java
Now we know that covariance is for reading (and writing is generally prohibited to a covariantly-typed object), and contravariance is for writing (and although we can read values for contravariant-typed objects, all the type information is lost).
Joshua Bloch in his famous “Effective Java” book proposes the following mnemonic rule for Java programmers:
PECS: Producer — Extends, Consumer — Super
This rule makes it simple to reason about the correct wildcard types in your API. If, for example, an argument for our method is a Function, we should always (no exceptions here) declare it this way:
void myMethod(Function<? super T, ? extends R> arg)The T parameter in Function is a type of the input, i.e. something that is being consumed, and thus we use ? super for it. The R parameter is the result, something that is produced, and thus we use ? extends. This trick will allow us to use any compatible Function as an argument. Any Function that can process T or its supertype will do, as well as any Function that yields R or any of its subtypes.
In the standard Java library API, we can see a lot of examples of wildcard types, all of them following the PECS rule. For example, a method that finds a maximum number in a Collection given a Comparator is defined like this:
public static <T> T max (Collection<? extends T> coll,
Comparator<? super T> comp)This allows us to conveniently use the following parameters: Collections.max(List<Integer>, Comparator<Number>) (if we can compare any Numbers, then we can compare Integers), Collections.max(List<String>, Comparator<Object>) (if we can compare Objects, then we can compare Strings).
In Kotlin, it is easy to memorize that producers always use the “out” keyword and consumers use “in.” Although Kotlin syntax is more concise and “in/out” keywords make it clearer which type is used for producer and which for consumer, it is still very useful to understand that “out” actually means a subtype, while “in” means a supertype.
Declaration Site Variance in Kotlin
Now we’re going to consider a feature that Kotlin has and Java doesn’t have: declaration site variance.
Let’s have a look at Kotlin’s immutable List. When we check the assignability of Kotlin’s List, we find that it looks similar to Java arrays. In other words, Kotlin’s List is covariant itself:
 Can we assign these immutable lists to each other?
Can we assign these immutable lists to each other?
Сovariance for Kotlin’s List doesn’t imply any problems related to Java covariant arrays, since you cannot add or modify anything. When just reading the values, we can safely cast Manager to Employee. That’s why a Kotlin function that requires List<Person> as its parameter will happily accept, say, List<Manager> even if that parameter does not use type projections.
There is no similar functionality in Java. When we compare the declaration of the List interface in Java and Kotlin, we’ll see the difference:
| Java | Kotlin |
|
Java
|
Kotlin
|
The keyword “out” in type declaration makes the List interface in Kotlin a covariant type everywhere.
Of course, you cannot make any type covariant in Kotlin: only those that are not using type parameters as an argument of a public method (while return type for E is OK). So it’s a good idea to declare all your immutable classes as covariant in Kotlin.
In our ‘MyList’ example we might also want to introduce an immutable pair like this:
class MyImmutablePair<out E>(val a: E, val b: E)In this class, we can only declare methods that return something of type E, but not public methods that will have E-typed arguments.
Note: constructor parameters and private methods with E-typed arguments are OK.
Now, if we want to add a method that takes values from MyImmutablePair, we don’t need to bother about use-site variance.
class MyList<E> : Iterable<E> {
//Don't bother about use-site type variance!
fun addAllFrom(pair: MyImmutablePair<E>){
add(pair.a); add(pair.b) }
...
}
val twoManagers: MyImmutablePair<Manager> = ...
employees.addAllFrom(twoManagers)The same applies to contravariance, of course. We might want to define a contravariant class MyConsumer in this way:
class MyConsumer<in E> {
fun consume(p: E){
...
}
}As soon as we defined a type as contravariant, the following limitations emerge:
- We can define methods that have
E-typed arguments, but we cannot expose anything of typeE. - We can have private class variables of type
E, and even private methods that returnE.
The addAllTo method, which dumps all the values to the given consumer, now doesn’t need to use type projections. The following code will compile and run:
class MyList<E> : Iterable<E> {
//Don't bother about use-site type variance!
fun addAllTo(consumer: MyConsumer<E>){
for (item in this) consumer.consume(item)
}
...
}
val employees: MyList<Employee> = ...
val personConsumer: MyConsumer<Person> = ...
employees.addAllTo(personConsumer)The one thing that’s worth mentioning is how declaration-site variance influences star projection Foo<*>. If we have an object typed Foo<*>, does it matter if Foo class is defined as invariant, covariant, or contravariant if we want to do something with this object?
- If the original type declaration is
Foo<T : TUpper>(invariant), then, of course, you can read values asTUpper, and you cannot write anything (evennull), because we don’t know the exact type. - If
Foo<out T : TUpper>is covariant, you can still read values asTUpper, and you cannot write anything just because there are no public methods for writing in this class. - If
Foo<in T : TUpper>is contravariant, then you cannot read anything (because there are no such public methods) and you still cannot write anything (because you “forgot” the exact type). So the contravariantFoo<*>variable is the most useless thing in Kotlin.
Kotlin Is Better for the Creation of Fluent APIs
When we consider switching between languages, the most important question is: what can a new language provide that cannot be achieved with the old one? The more concise syntax is good, but if everything that a new language offers is just syntactic sugar, then maybe it is not worth switching from familiar tools and ecosystems.
In regards to type variance in Kotlin vs. Java, the question is: does declaration site variance provide the options that are impossible in Java with wildcard types?
In my opinion, the answer is definitely yes, as use site variance is not just about getting rid of “? extends” and “? super” everywhere.
Here’s a real-life example of the problems that arise when we design APIs for data streaming processing frameworks (in particular, this example relates to Apache Kafka Streams API).
The key classes of such frameworks are abstractions of data streams, like KStream<K>, which are semantically covariant: stream of Employee can be safely considered as a stream of Person if all that we are interested in are Person’s properties.
Now imagine that in library code we have a class which accepts a funciton capable of transforming into a stream.
class Processor<E> {
void withFunction(Function<? super KStream<E>,
? extends KStream<E>> chain) {...}
}In the user’s code these functions may look like this:
KStream<Employee> transformA(KStream<Employee> s) {...}
KStream<Manager> transformB(KStream<Person> s) {...}As you can see, both of these functions can work as a transformer from KStream<Employee> to KStream<Employee>. But if we try to use them as method references passed to the withFunction method, only the first one will do:
Processor<Employee> processor = ...
//Compiles
processor.withFunction(this::transformA);
//Won't compile with "KStream<Employee> is not convertible to KStream<Person>"
processor.withFunction(this::transformB);The problem cannot be fixed by just adding more “? extends.” If we define the class in this way:
class Processor<E> {
//A mind-blowing number of question marks
void withFunction(Function<? super KStream<? super E>,
? extends KStream<? extends E>> chain) {...}
}then both lines
processor.withFunction(this::transformA);
processor.withFunction(this::transformB);will fail to compile with something like “KStream<capture of ? super Employee> is not convertible to KStream<Employee>.” Type calculation in Java is not too “wise” to support complex recursive definitions.
Meanwhile in Kotlin, if we declare class KStream<out E> as covariant, this is easily possible:
/* LIBRARY CODE */
class KStream<out E>
class Processor<E> {
fun withFunction(chain: (KStream<E>) -> KStream<E>) {}
}
/* USER'S CODE */
fun transformA(s: KStream<Employee>): KStream<Employee> { ... }
fun transformB(s: KStream<Person>): KStream<Manager> { ... }
val processor: Processor<Employee> = Processor()
processor.withFunction(this::transformA)
processor.withFunction(this::transformB)All the lines will compile and run as intended (besides the fact that we have more concise syntax).
Kotlin has a clear win in this scenario.
Conclusion
To sum up, here are some properties of different kinds of type variance.
Covariance is:
? extendsin Javaoutin Kotlin- safe reading, unsafe or impossible writing
- described by the following diagram:
When
Ais a supertype ofB, then the matrix of possible assignments fills the lower left corner:

Contravariance is:
? superin Javainin Kotlin- safe writing, type information lost or impossible reading
- described by the following diagram:

- When
Ais a supertype ofB, then the matrix of possible assignments fills the upper right corner:

Invariance is:
- assumed in Java and Kotlin by default
- safe writing and reading
- when
Ais a supertype ofB, then the matrix of possible assignments fills only the diagonal:

To create good APIs, understanding type variance is necessary. Kotlin offers great enhancements for Java Generics, making usage of ready-made generic types even more straightforward. But to create your generic types in Kotlin, it’s even more important to understand the principles of type variance.
I hope that it’s now clear how type variance works and how it can be used in your APIs. Thanks for reading.
Opinions expressed by DZone contributors are their own.
Comments