Understanding how Parquet Integrates with Avro, Thrift and Protocol Buffers
Join the DZone community and get the full member experience.
Join For Freeparquet is a new columnar storage format that come out of a collaboration between twitter and cloudera. parquet’s generating a lot of excitement in the community for good reason - it’s shaping up to be the next big thing for data storage in hadoop for a number of reasons:
- it’s a sophisticated columnar file format, which means that it’s well-suited to olap workloads, or really any workload where projection is a normal part of working with the data.
- it has a high level of integration with hadoop and the ecosystem - you can work with parquet in mapreduce, pig, hive and impala.
- it supports avro, thrift and protocol buffers.
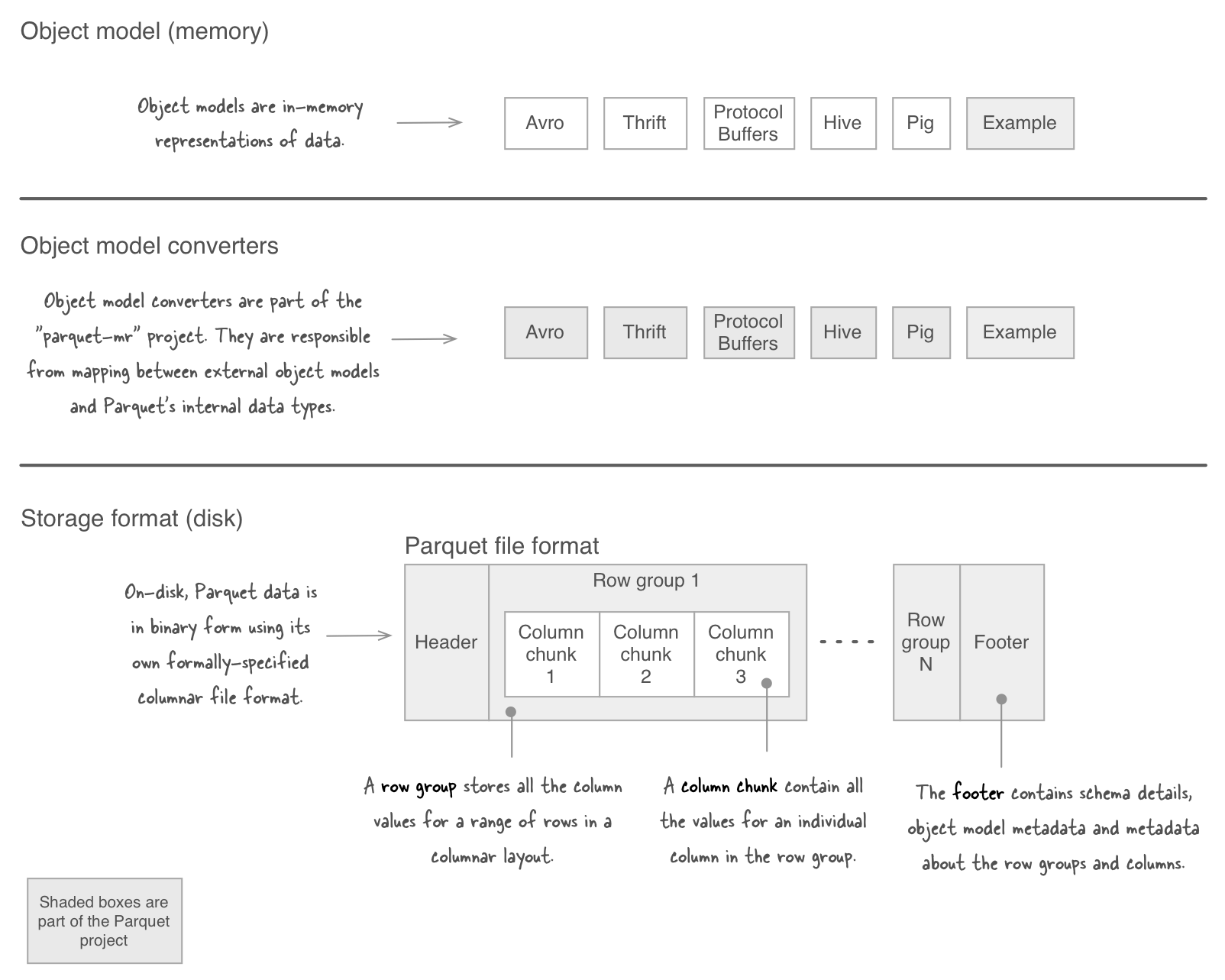
the last item raises a question - how does parquet work with avro and friends? to understand this you’ll need to understand three concepts:
- storage formats , which are binary representations of data. for parquet this is contained within the parquet-format github project.
- object model converters , whose job it is to map between an external object model and parquet’s internal data types. these converters exist in the parquet-mr github project.
- object models , which are in-memory representations of data. avro , thrift , protocol buffers , hive and pig are all examples of object models. parquet does actually supply an example object model (with mapreduce support ) , but the intention is that you’d use one of the other richer object models such as avro.
the figure below shows a visual representation of these concepts ( view a larger image ).
{kind=link}
avro, thrift and protocol buffers all have have their own storage formats, but parquet doesn’t utilize them in any way. instead their objects are mapped to the parquet data model. parquet data is always serialized using its own file format. this is why parquet can’t read files serialized using avro’s storage format, and vice-versa.
let’s examine what happens when you write an avro object to parquet:
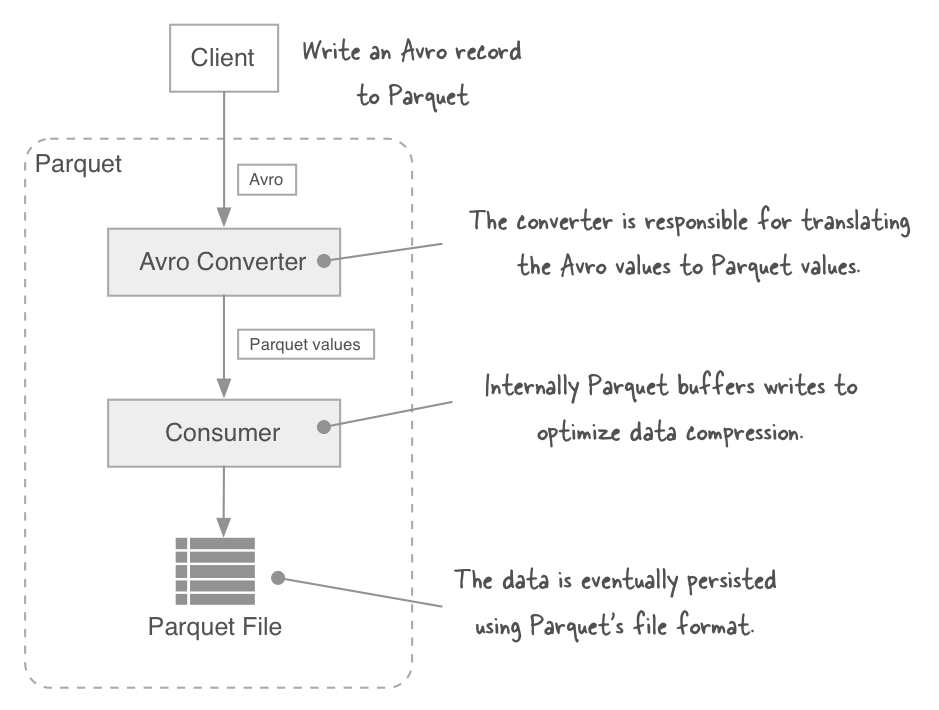
the avro converter stores within the parquet file’s metadata the schema for the objects being written. you can see this by using a parquet cli to dumps out the parquet metadata contained within a parquet file.
$ export hadoop_classpath=parquet-avro-1.4.3.jar:parquet-column-1.4.3.jar:parquet-common-1.4.3.jar:parquet-encoding-1.4.3.jar:parquet-format-2.0.0.jar:parquet-generator-1.4.3.jar:parquet-hadoop-1.4.3.jar:parquet-hive-bundle-1.4.3.jar:parquet-jackson-1.4.3.jar:parquet-tools-1.4.3.jar
$ hadoop parquet.tools.main meta stocks.parquet
creator: parquet-mr (build 3f25ad97f209e7653e9f816508252f850abd635f)
extra: avro.schema = {"type":"record","name":"stock","namespace" [more]...
file schema: hip.ch5.avro.gen.stock
--------------------------------------------------------------------------------
symbol: required binary o:utf8 r:0 d:0
date: required binary o:utf8 r:0 d:0
open: required double r:0 d:0
high: required double r:0 d:0
low: required double r:0 d:0
close: required double r:0 d:0
volume: required int32 r:0 d:0
adjclose: required double r:0 d:0
row group 1: rc:45 ts:2376
--------------------------------------------------------------------------------
symbol: binary uncompressed do:0 fpo:4 sz:84/84/1.00 vc:45 enc:b [more]...
date: binary uncompressed do:0 fpo:88 sz:198/198/1.00 vc:45 en [more]...
open: double uncompressed do:0 fpo:286 sz:379/379/1.00 vc:45 e [more]...
high: double uncompressed do:0 fpo:665 sz:379/379/1.00 vc:45 e [more]...
low: double uncompressed do:0 fpo:1044 sz:379/379/1.00 vc:45 [more]...
close: double uncompressed do:0 fpo:1423 sz:379/379/1.00 vc:45 [more]...
volume: int32 uncompressed do:0 fpo:1802 sz:199/199/1.00 vc:45 e [more]...
adjclose: double uncompressed do:0 fpo:2001 sz:379/379/1.00 vc:45 [more]...
the “avro.schema” is where the avro schema information is stored. this allows the avro parquet reader the ability to marshall avro objects without the client having to supply the schema.
you can also use the “schema” command to view the parquet schema.
$ hadoop parquet.tools.main schema stocks.parquet
message hip.ch4.avro.gen.stock {
required binary symbol (utf8);
required binary date (utf8);
required double open;
required double high;
required double low;
required double close;
required int32 volume;
required double adjclose;
}
this tool is useful when loading a parquet file into hive, as you’ll need to use the field names defined in the parquet schema when defining the hive table (note that the syntax below only works with hive 0.13 and newer).
hive> create external table parquet_stocks(
symbol string,
date string,
open double,
high double,
low double,
close double,
volume int,
adjclose double
) stored as parquet
location '...';
Published at DZone with permission of Alex Holmes, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments