Understanding Information Retrieval by Using Apache Lucene and Tika - Part 1
Join the DZone community and get the full member experience.
Join For Freeintroduction
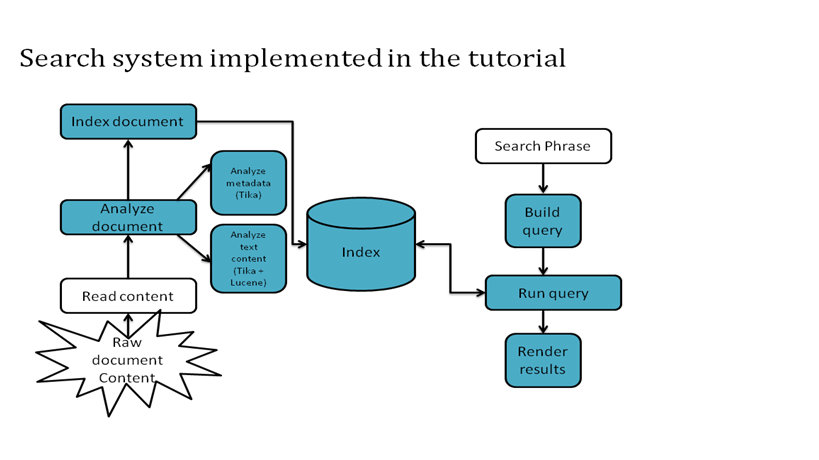
in this tutorial, the apache lucene and apache tika frameworks will be explained through their core concepts (e.g. parsing, mime detection, content analysis, indexing, scoring, boosting) via illustrative examples that should be applicable to not only seasoned software developers but to beginners to content analysis and programming as well. we assume you have a working knowledge of the java™ programming language and plenty of content to analyze.
throughout this tutorial, you will learn:
- how to use apache tika's api and its most relevant functions
- how to develop code with apache lucene api and its most important modules
- how to integrate apache lucene and apache tika in order to build your own piece of software that stores and retrieves information efficiently. (project code is available for download)
what are lucene and tika?
according to apache lucene's site, apache lucene represents an open source java library for indexing and searching from within large collections of documents. the index size represents roughly 20-30% the size of text indexed and the search algorithms provide features like:
- ranked searching - best results returned first
- many powerful query types: phrase queries, wildcard queries, proximity queries, range queries and more. in this tutorial we will demonstrate only phrase queries.
- fielded search (e.g. title, author, contents)
- sorting by any field
- flexible faceting, highlighting, joins and result grouping
- pluggable ranking models, including the vector space model and okapi bm25
but lucene's main purpose is to deal directly with text and we want to manipulate documents, who have various formats and encoding. for parsing document content and their properties the apache tika library it is necessary.
apache tika is a library that provides a flexible and robust set of interfaces that can be used in any context where metadata analyzis and structured text extraction is needed. the key component of apache tika is the parser (org.apache.tika.parser.parser ) interface because it hides the complexity of different file formats while providing a simple and powerful mechanism to extract structured text content and metadata from all sorts of documents.
criterias for tika parsing design
|
streamed parsing |
the interface should require neither the client application nor the parser implementation to keep the full document content in memory or spooled to disk. this allows even huge documents to be parsed without excessive resource requirements. |
|
structured content |
a parser implementation should be able to include structural information (headings, links, etc.) in the extracted content. a client application can use this information for example to better judge the relevance of different parts of the parsed document. |
|
input metadata |
a client application should be able to include metadata like the file name or declared content type with the document to be parsed. the parser implementation can use this information to better guide the parsing process. |
|
output metadata |
a parser implementation should be able to return document metadata in addition to document content. many document formats contain metadata like the name of the author that may be useful to client applications. |
|
context sensitivity |
while the default settings and behaviour of tika parsers should work well for most use cases, there are still situations where more fine-grained control over the parsing process is desirable. it should be easy to inject such context-specific information to the parsing process without breaking the layers of abstraction. |
requirements
- maven 2.0 or higher
- java 1.6 se or higher
lesson
1: automate metadata extraction from any file type
our premisses are the following: we have a collection of documents stored on disk/database and we would like to index them; these documents can be word documents, pdfs, htmls, plain text files etc. as we are developers, we would like to write reusable code that extracts file properties regarding format (metadata) and file content. apache tika has a mimetype repository and a set of schemes (any combination of mime magic, url patterns, xml root characters, or file extensions) to determine if a particular file, url, or piece of content matches one of its known types. if the content does match, tika has detected its mimetype and can proceed to select the appropriate parser.
in the sample code, the file type detection and its parsing is being covered inside the class com.retriever.lucene.index.indexcreator , method indexfile.
listing 1.1 analyzing a file
with tika
public static documentwithabstract indexfile(analyzer analyzer, file file) throws ioexception {
metadata metadata = new metadata();
contenthandler handler = new bodycontenthandler(10 * 1024 * 1024);
parsecontext context = new parsecontext();
parser parser = new autodetectparser();
inputstream stream = new fileinputstream(file); //open stream
try {
parser.parse(stream, handler, metadata, context); //parse the stream
} catch (tikaexception e) {
e.printstacktrace();
} catch (saxexception e) {
e.printstacktrace();
} finally {
stream.close(); //close the stream
}
//more code here
}
the
above code displays how a file it is being parsed using
org.apache.tika.parser.autodetectparser;
this kind of implementation was chosen
because we would like to achieve parsing documents disregarding their format. also, for handling the content the
org.apache.tika.sax.bodycontenthandler
wasconstructed with a writelimit given as
parameter ( 10*1024*1024); this type of constructor creates a content handler
that writes xhtml body character events to an internal string buffer and in
case of documents with large content is less likely to throw a saxexception
(thrown when the default write limit is reached).
as a result of our parsing we have obtained a metadata object that we can now use to detect file properties (title or any other header specific to a document format). metadata processing can be done as described below ( com.retriever.lucene.index.indexcreator , method indexfiledescriptors) :
listing 1.2 processing metadata
private static document indexfiledescriptors(string filename, metadata metadata) {
document doc = new document();
//store file name in a separate textfield
doc.add(new textfield(isearchconstants.field_file, filename, store.yes));
for (string key : metadata.names()) {
string name = key.tolowercase();
string value = metadata.get(key);
if (stringutils.isblank(value)) {
continue;
}
if ("keywords".equalsignorecase(key)) {
for (string keyword : value.split(",?(\\s+)")) {
doc.add(new textfield(name, keyword, store.yes));
}
} else if (isearchconstants.field_title.equalsignorecase(key)) {
doc.add(new textfield(name, value, store.yes));
} else {
doc.add(new textfield(name, filename, store.no));
}
}
in the method presented above we store the file name in a separate field and also the document's title ( a document can have a title different from its file name); we are not interested in storing other informations.
Opinions expressed by DZone contributors are their own.
Comments