Understanding the Reactive Thread Model (Part 2)
Join the DZone community and get the full member experience.
Join For FreeIn part one of this series, we covered a reactive web and simple blocking and non-blocking call. In this article, we will be going in-depth on thread execution and business flow.
Non-blocking Call With Thread Execution.
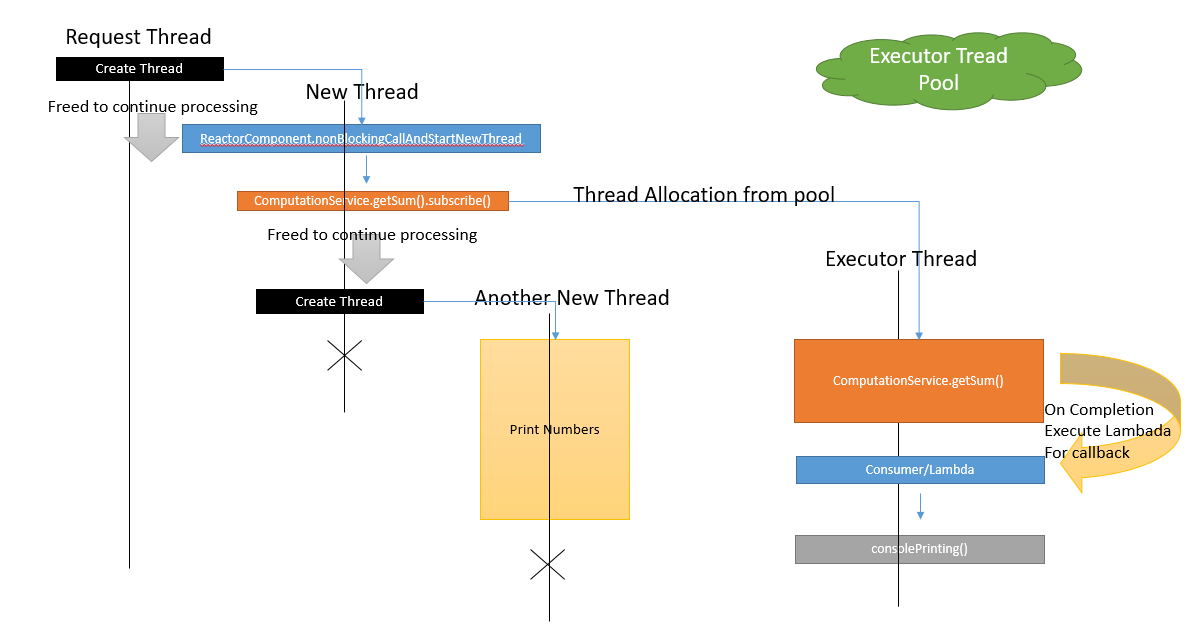
The diagram looks complex, but what we are doing is that we are starting a new thread from request thread and then calling the reactive function. Again, we're creating the new thread from the previous thread to do some console printing. What we want to test or achieve here is that both reactive the sum() function and console printing happen in parallel. The execution of sum() is not blocking the start and print of the new thread.
xxxxxxxxxx
public static void nonBlockingCallAndStartNewThread(ApplicationContext ctx) throws InterruptedException {
Runnable r = new Runnable() {
public void run() {
System.out.println("In New Thread Run method:
"+Thread.currentThread());
try {
Consumer<Integer> consumer = C -> print(C);
ctx.getBean(ReactorComponent.class).nonBlockingSum(
new Integer[]
{400000,780,40,6760,30,3456450}).subscribe(consumer);
Runnable r1 = new Runnable() {
public void run() {
System.out.println("Started Another Thread:
"+Thread.currentThread());
for(int i =0; i <5; i++){
i++;
}
System.out.println("End of Another Thread:
"+Thread.currentThread());
}
};
new Thread(r1).start();
System.out.println("End of New Thread: "+Thread.currentThread());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
new Thread(r).start();
}
When we execute the above code, we get the following printed in our console:
xxxxxxxxxx
In ReactiveApplication.nonBlockingCallAndStartNewThread: Thread[main,5,main]
...
In New Thread Run method: Thread[Thread-3,5,main]
...
End of New Thread: Thread[Thread-3,5,main]
Started Another Thread: Thread[Thread-10,5,main]
End of Another Thread: Thread[Thread-10,5,main]
...
In Consumer/Lambada Result= 3864060 Thread: Thread[ReactiveScheduler-2,5,main]
The above console output clearly shows that consumer/lambada were executed at the last. Both threads (Thread-3 and Thread-10) didn't wait for the computation of the sum() method.
In a very high-performance PC, you will not able to get the same console output. Put some sleep in the sum() method so that you can co-relate exactly what is happening.
Serial Business Flow Processing
Until now, we have discussed the thread and its execution patterns. I hope you have a clear understanding about reactive callbacks and how they are executed differently than the request/main thread. Without any delay, we will discuss how a reactive framework can be useful in the context of a business flow processing.
Let's continue with our sum() method and create a dummy business case of calculating the sum by removing the first and bottom elements after sorting. The simple way to do is to get the max and min and deduct them from the sum. The formula will look like this: result = sum - max - min. Note, we are uninterested in boundary conditions here. Let's see the thread model first:
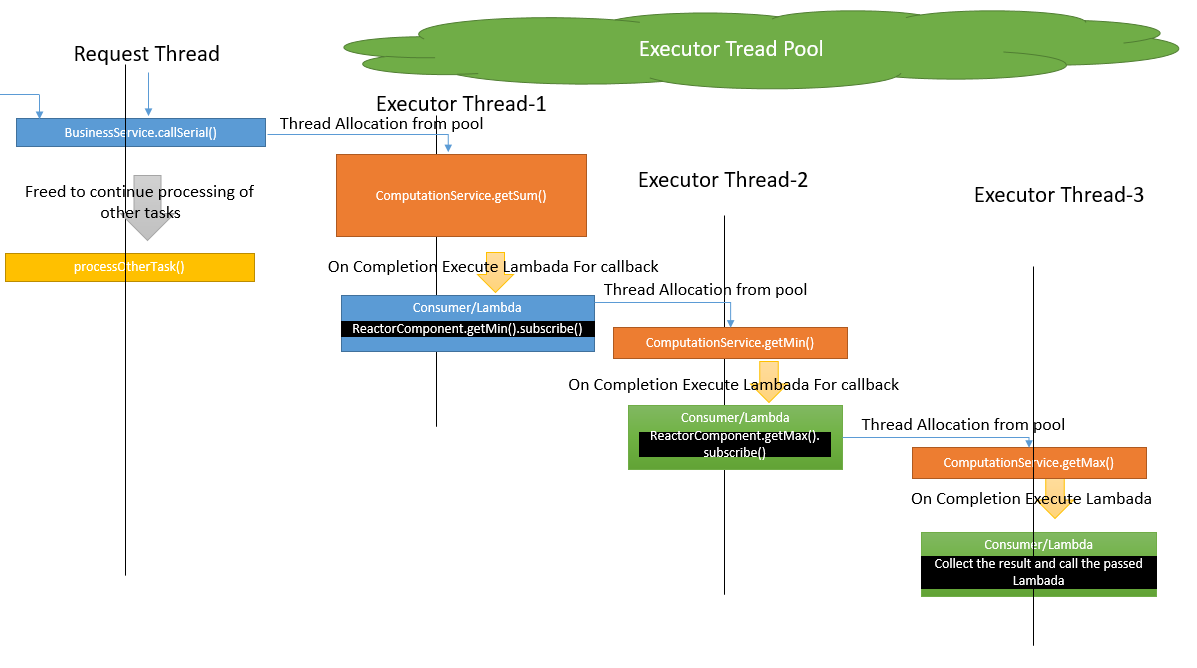
Definitely, it looks complex. In this example, we are calling the subsequent business method from the consumer/lambada function and collecting the result in an atomic way. The following is the respective code snippet.
xxxxxxxxxx
public void businessService(Integer arr[], TestLambada <Temp> testLambada) throws InterruptedException {
System.out.println("In BusinessService.businessService:
"+Thread.currentThread());
// Start the execution in sequence.
Consumer<Integer> consumerForSum = sum -> {
AtomicInteger result = new AtomicInteger();
System.out.println("In consumerForSum: "+Thread.currentThread());
result.addAndGet(sum);
Consumer<Integer> consumerForMin = min -> {
System.out.println("In consumerForMin: "+Thread.currentThread());
result.set(result.intValue()-min);
Consumer <Integer> consumerForMax = max -> {
System.out.println("In consumerForMax: "+Thread.currentThread());
result.set(result.intValue()-max);
testLambada.get(new Temp(result.get()));
System.out.println("End of consumerForMax:
"+Thread.currentThread());
};
legacyComponent.getMax(arr).subscribe(consumerForMax);
System.out.println("End of consumerForMin: "+Thread.currentThread());
};
legacyComponent.getMin(arr).subscribe(consumerForMin);
System.out.println("End of consumerForSum: "+Thread.currentThread());
};
legacyComponent.nonBlockingSum(arr).subscribe(consumerForSum);
System.out.println("Returning from BusinessService.businessService:
"+Thread.currentThread());
}
When you execute the above code, you will get the following response:
xxxxxxxxxx
In ReactiveApplication.callBusinessWorkflowSerial: Thread[main,5,main]
…
In consumerForSum: Thread[ReactiveScheduler-2,5,main]
…
In consumerForMin: Thread[ReactiveScheduler-3,5,main]
…
In consumerForMax: Thread[ReactiveScheduler-2,5,main]
Printing result in tempTestLambada= 131
…
If you see that all callbacks were called in separate threads, there is a thread reuse too, as it is coming from the executor pool.
Code it is incredibly complex; there are many asynchronous executions, and it is very much the classic anti-pattern of callback hell. Therefore, you need to be extra careful about which part of your code should be processed as callback and which part should be in the same thread block. I will suggest that you create a balance between reactive and non-reactive components.
Parallel Business Flow Processing
If you see the previous business case, there was a sequential execution of the business flow. In doing so, the total response time will represent a sum of each execution time. So, during the sequential execution, threads were idle in the pool and eventually, the CPU will be unused to a sufficient extent.
Let's try to make our business flow to execute in parallel. Here, we can perform the computation of a sum, min, and max to execute in parallel and then apply our formula. We are going to use the completable future wrapped in the Mono.zip method of the reactor framework. Note, it is not always possible to execute business flow in parallel, as there can be dependencies between the flows. The following is a thread model:
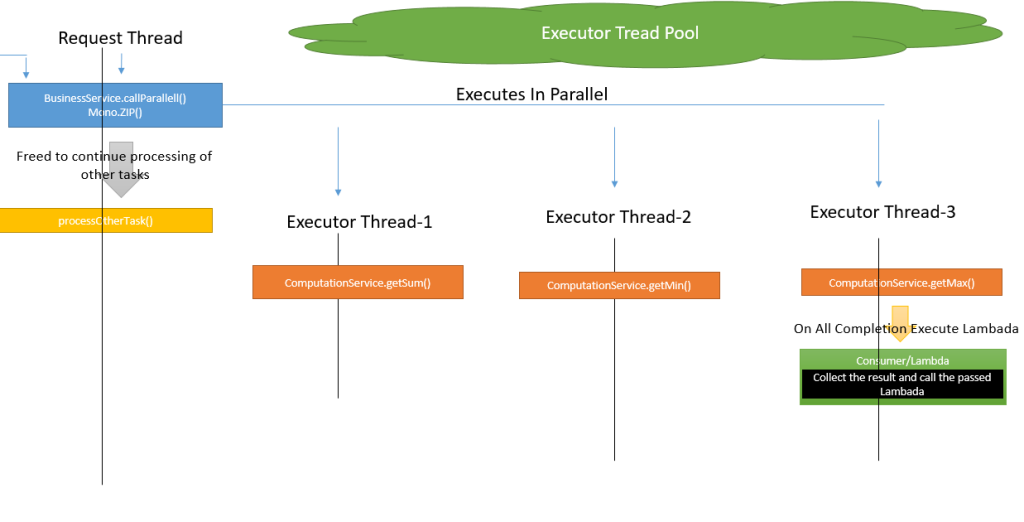
Code snippet:
xxxxxxxxxx
public void busServiceInParallel(Integer arr[], TestLambada <Temp> testLambada) throws InterruptedException {
System.out.println("In BusinessService.busServiceInParallel:
"+Thread.currentThread());
Consumer<Tuple3<Integer,Integer,Integer>> consumer= a -> {
System.out.println("In consumer For Parallel: "+Thread.currentThread());
testLambada.get(new Temp(((Integer)a.get(0)-(Integer)a.get(1)-
(Integer)a.get(2))));
};
Mono.zip(legacyComponent.nonBlockingSum(arr),
legacyComponent.getMin(arr),
legacyComponent.getMax(arr)).subscribe(consumer);
System.out.println("Returning from BusinessService.busServiceInParallel:
"+Thread.currentThread());
}
The execution of the above code will print the following:
xxxxxxxxxx
In ReactiveApplication.callBusinessWorkflowParallel: Thread[main,5,main]
…
In ComputationService.getSum: Thread[ReactiveScheduler-2,5,main]
In ComputationService.getMin: Thread[ReactiveScheduler-3,5,main]
In ComputationService.getMax: Thread[ReactiveScheduler-4,5,main]
…
In consumer For Parallel: Thread[ReactiveScheduler-2,5,main]
In Parallel Business Workflow Lambada Result: 131 and Thread: Thread[ReactiveScheduler-2,5,main]
If you observe sum, min, and max were executed in separate threads. Consumer/lambada who is doing aggregation is also executed in separate threads.
Points to Note
- In the case of a blocking call, there can be resource waste, as your current thread will wait for the i/o operation. In a reactive call, this can be avoided. Therefore, from a scaling perspective, it will be advantageous to shift to reactive considering the load factor.
- Myth that synchronous code is slow and reactive code is fast. Synchronous code will run in one process and one thread, while in reactive, one thread will be performing multiple things probably looping across possible tasks it can perform. In fact, synchronous code can be fast, as there is not much thread switching, as in the case of reactive where thread context will get switch often. Remember, thread context switching is expensive. But reactive can speed up if you execute in parallel.
- The balance between synchronous and reactive processing needs to be maintained. Recall reactive works on the worker threads of the executor, and there is a limit for each type of executor. If you formulate your code too much, reactive then executor threads might run short on availability. Therefore, maintaining a balance between synchronous and reactive threads is critical.
- With more threads, more memory will be required in the case of reactive processing, as there will be lots of processing in parallel. Even thread context switching will equally take up some kilobytes of RAM memory. More memory more Garbage Collection (GC) cycles, which can hamper the performance of your application.
My Experience With Reactive Programming
- As the code will be not in sequential order, it will be difficult in terms of readability. It will look complex until you conquer it.
- Lots of thinking about your approach are needed before you start writing reactive code; even simple back-to-back calls will require some deep thinking.
- Lots of new challenges will be created for unit testing, which you need to get prepared.
- As your business flow expands across multiple threads, there will need to rethink the logging strategy to add correlation id as many threads will log the same request flow.
- Debugging will be challenging, as there will be a need to add multiple breakpoints and follow the flow better. Merely doing a step-over is not going to work.
Conclusion
In spite of the previous points and facts, reactive programming is great to learn, and I will suggest that you should start. There's definitely a learning curve, and you might feel lost. As you master it, you will observe tremendous advantages from a resource perspective. Welcome to the new way of looking at programming.
You can get the complete code in github.
Happy coding.
Published at DZone with permission of Milind Deobhankar. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments