Understanding Time Series Databases
Time series databases (TSDBs) are specialized database systems optimized for storing, retrieving, and analyzing chronological data.
Join the DZone community and get the full member experience.
Join For FreeOrganizations now generate extensive amounts of time-stamped data through IoT devices as well as financial markets and application logs in the present data-driven world. Time series databases function as dedicated solutions that optimize the storage, analysis, and processing of temporal data. This article examines the essential principles of time series databases while examining their distinctive traits and evaluating their performance against standard database management systems.
What Is Time Series Data?
Time series data represents tracked and monitored data points that get downscaled and aggregated throughout a chronological period. A time series contains data points where each entry has its corresponding timestamp, which determines the sequence of events. Such data exists extensively throughout our digital world and manifests as:
- Server and application metrics
- IoT sensor readings
- Financial market data
- User activity logs
- Network performance statistics
Time series data is characterized by its continuous temporal nature, which produces an expanding dataset because new data points emerge with each time period.
What Is a Time Series Database?
Time series databases (TSDB) function as database systems that specialize in managing and delivering time-stamped and time-series data. TSDBs differ from general-purpose databases since they organize data through time as their main dimension, which allows efficient storage, retrieval, and analysis of time-ordered data.
Specialized databases contain features that address the distinct nature of time series data through their implementation of:
- High-speed data ingestion
- Efficient time-based queries
- Specialized compression algorithms
- Time-based data lifecycle management
- Purpose-built analytical functions
Time Series Databases vs. Relational Databases
Knowledge of fundamental differences between time series databases and relational databases will lead to better tool selection for data management requirements.
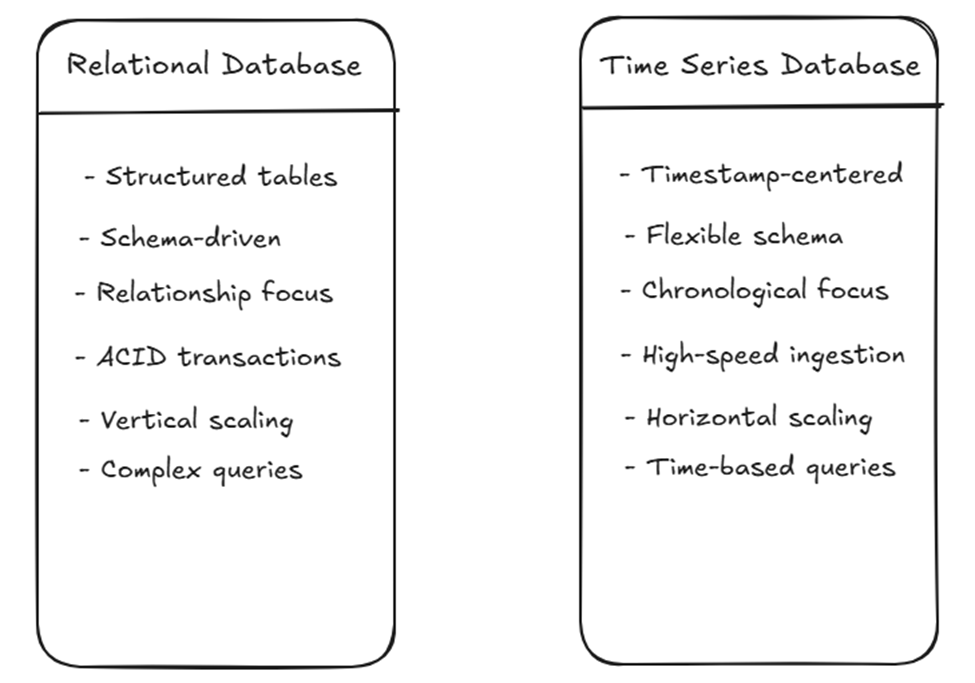
Data Structure
Relational Databases
- Each piece of data exists in structured tables that use rows and columns for organization
- Database systems employ schemas as tools to specify both structure and relationship definitions
- The system uses primary and foreign keys to establish links between tables
- Focus on maintaining data integrity and relationships
Time Series Databases
- Center structure around timestamps as primary identifiers
- A time series database stores sequences of data points that were collected at different times.
- Rigid schemas, as required by relational databases, are not necessary
- Prioritize chronological arrangement of data points
Performance Optimization
Relational Databases
- Optimized for transactional operations (OLTP)
- Focus on complex queries with structured data
- Focus on maintaining four core principles: atomicity, consistency, isolation, and durability
- Use a general indexing system with caching and query optimization methods
Time Series Databases
- Optimized for time-based queries and high-volume data ingestion
- Use specialized storage methods and data structures
- Use compression algorithms that are specifically designed for time series data
- Use methods, such as inverted or bitmap indexes, are used
Scalability
Relational Databases
- Traditionally, face challenges with horizontal scaling
- Often rely on vertical scaling (increasing single server resources)
- ACID properties are difficult to maintain when distributed systems are considered.
- A single server has its own restrictions on the amount of data it can handle
Time Series Databases
- Designed for horizontal scalability
- Distribution of data is possible across multiple nodes or clusters.
- The system handles rising data amounts more effectively.
- Higher numbers of concurrent read/write operations are supported by the system
Key Use Cases for Time Series Databases
Time series databases provide effective solutions for multiple applications that span various industries:
Internet of Things (IoT)
TSDBs store and analyze IoT-generated continuous time-stamped data, which powers smart home and building systems, industrial automation, predictive maintenance, and environmental monitoring systems.
DevOps and System Monitoring
TSDBs serve IT infrastructure and application monitoring by recording the following metrics:
- CPU and memory usage
- Network throughput
- Application performance
- Server health statistics
Financial Services
The financial sector relies on TSDBs for:
- High-frequency trading analytics
- Real-time risk assessment
- Algorithmic trading
- Portfolio optimization
Energy Sector
The energy management sector employs TSDBs for performing smart grid optimization along with renewable energy monitoring and resource tracking and optimization.
Healthcare
TSDBs support healthcare applications through:
- Remote patient monitoring
- Clinical research data tracking
- Health metrics analysis
Retail
TSDBs allow retailers to utilize their databases for three essential applications: customer behavior analysis, sales trend forecasting, and inventory management optimization.
Architecture: Data Flow in Time Series Systems
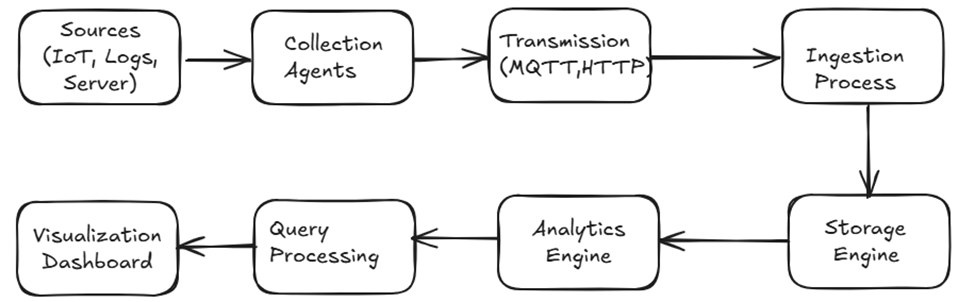
Figure: Time Series Database Architecture Flow
A standard time series database system consists of multiple operational components that function as a single system.
- Data Collection: Agents or collectors gather metrics from various sources (servers, applications, IoT devices)
- Data Transmission: Collected data is sent to the TSDB using protocols like HTTP, MQTT, or specialized APIs
- Data Ingestion: The TSDB processes and stores incoming data, often with timestamp indexing
- Data Storage: Specialized storage engines optimize data compression and retrieval
- Query Processing: Time-oriented query languages enable efficient data analysis
- Visualization: Dashboards and tools present the analyzed data in meaningful ways
Advantages of Time Series Databases
Time series databases demonstrate better capabilities than traditional databases for certain data management tasks.
- High-volume data handling: TSDBs efficiently manage large volumes of time-stamped data from various sources
- Superior performance: TSDBs achieve better performance than general databases when handling time-series data through fast ingestion, query processing, and efficient compression capabilities
- Specialized analytics: The system includes time-weighted average and moving average calculations and other time-related functions
- Efficient storage: Advanced compression algorithms reduce storage requirements while maintaining fast access to historical data
- Data lifecycle management: Automated policies for down-sampling or removing aging data
- Scalability: The system allows users to perform vertical and horizontal scaling to adapt to expanding data sizes
Limitations of Time Series Databases
Time series databases retain several restrictions beyond their multiple benefits.
- Complexity: The implementation and maintenance of time series databases tend to be more complicated than traditional database systems
- Limited options: The selection of available platforms for time series databases is limited compared to relational or NoSQL databases
- Storage requirements: Time series data accumulates large quantities of information, which demands extensive storage capacity
- Learning curve: Users need specific training to understand time series databases because of their unique query languages and system concepts.
- Not ideal for all data: Time series databases are less appropriate when dealing with complex relational data containing extensive interconnections.
Implementing a Time Series Database With InfluxDB and Python
Let's walk through a practical implementation using InfluxDB, a popular time series database, and Python.
Step 1: Setting Up InfluxDB
If you have Docker installed, you can quickly start InfluxDB using:
docker run --name influxdb -p 8086:8086 influxdb:2.1.0After running this command, access the InfluxDB UI at http://localhost:8086 to complete the initial setup.
Step 2: Installing the Python Client
Install the InfluxDB Python client library:
pip install influxdb-clientStep 3: Creating a Basic Python Script
Create a new file named influx_example.py with the following code to connect to InfluxDB:
import influxdb_client
from influxdb_client.client.write_api import SYNCHRONOUS
import os
from datetime import datetime
# InfluxDB connection parameters
url = "http://localhost:8086"
token = "your-token" # Replace with your token from InfluxDB UI
org = "your-org" # Replace with your organization
bucket = "your-bucket" # Replace with your bucket
# Initialize the client
client = influxdb_client.InfluxDBClient(
url=url,
token=token,
org=org
)
# Create write API
write_api = client.write_api(write_options=SYNCHRONOUS)
# Create a data point
point = influxdb_client.Point("measurement_name")\
.tag("location", "server-room")\
.field("temperature", 25.3)\
.time(datetime.utcnow())
# Write data to InfluxDB
write_api.write(bucket=bucket, org=org, record=point)
print("Data written successfully")
# Create query API
query_api = client.query_api()
# Query data
query = f'from(bucket: "{bucket}") |> range(start: -1h) |> filter(fn: (r) => r["_measurement"] == "measurement_name")'
result = query_api.query(org=org, query=query)
# Process and display results
for table in result:
for record in table.records:
print(f"Time: {record.get_time()}, Value: {record.get_value()}")
# Close the client
client.close()
Conclusion
Time series databases have become fundamental tools for managing the increasing volume of time-stamped data in our increasingly connected world. Their specialized design offers significant advantages in performance, scalability, and analytical capabilities compared to traditional database systems.
Organizations can make informed decisions about implementing time series databases by understanding time series data characteristics and TSDB architectural considerations. Time series databases serve as the essential base for effective time-based data management and analysis in all cases, including IoT device monitoring, financial market analysis, and application performance tracking.
F
Opinions expressed by DZone contributors are their own.
Comments