Unlocking Scalable Data Lakes: Building With Apache Iceberg, AWS Glue, and S3
Apache Iceberg + AWS Glue + S3 bring ACID, schema evolution, and time travel to data lakes—fixing schema drift, small files, and cost sprawl at enterprise scale.
Join the DZone community and get the full member experience.
Join For FreeIntroduction: The Pain of Traditional Data Lakes
Over the last decade, cloud object storage (Amazon S3, Azure Blob, Google Cloud Storage) has become the de facto substrate for data lakes. The promise was alluring: cheap, durable, infinitely scalable storage with a “store first, model later” mindset.
But in practice, traditional data lakes quickly turned into “data swamps.” Engineers face recurring issues:
- Schema drift — source systems evolve, columns get added or reordered, and analysts downstream hit mysterious nulls or misaligned data.
- Partitioning pain — manual folder hierarchies (
year=2025/month=09/day=29) work until they don’t. Queries skip partitions poorly, and teams argue over partition depth. - Small file and compaction issues — ingestion pipelines often generate thousands of tiny files, leading to poor query performance and skyrocketing costs.
- No transactional guarantees — concurrent writers step on each other, producing partial updates or duplicate data.
- Cost sprawl — without governance, analysts query petabytes of data unnecessarily, sending the bill northward.
These aren’t edge cases—they’re the day-to-day reality of enterprise-scale data engineering. The good news: open table formats like Apache Iceberg, paired with S3 and AWS Glue, have transformed the landscape.
Why Apache Iceberg
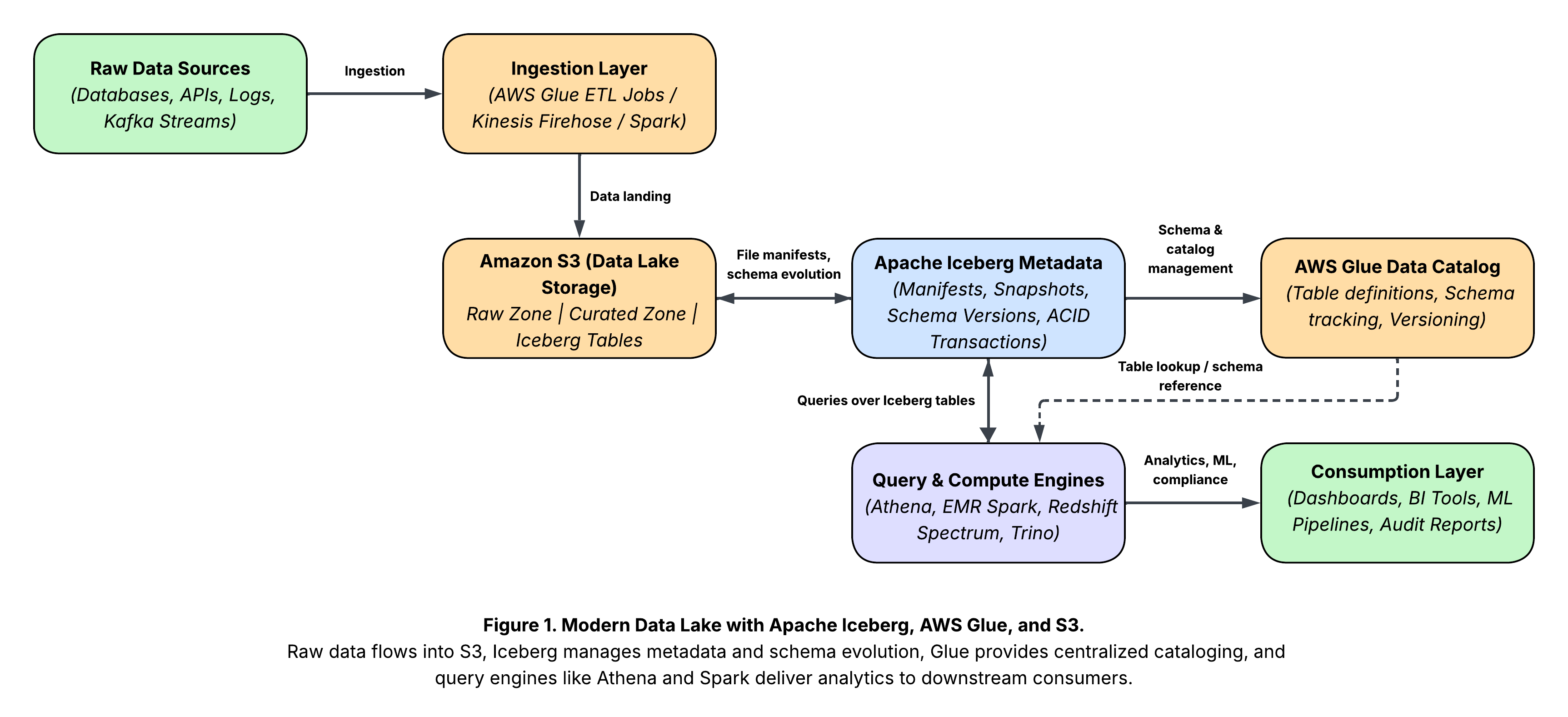
Apache Iceberg is an open table format designed to bring data warehouse reliability to the data lake. Unlike Hive-style tables that rely on directory structures, Iceberg maintains a manifest and metadata layer that tracks every file, schema, and snapshot.
Key capabilities that resonate in production:
- ACID transactions – concurrent inserts, updates, and deletes are handled safely.
- Schema evolution – add, drop, rename, or reorder columns without breaking queries.
- Time travel – query historical versions of a table for debugging, auditing, or reproducing past analytics.
- Open adoption – works with Spark, Flink, Trino, Athena, and more. No vendor lock-in.
When you adopt Iceberg, you stop fighting your lake’s folder structure and start treating your data as first-class, queryable tables with lineage and consistency.
S3 as the Backbone
Amazon S3 remains the most battle-tested foundation for scalable data lakes. Why?
- Durability – eleven nines (
99.999999999%) across multiple availability zones. - Cost-effectiveness – tiered storage (Standard, IA, Glacier) lets you manage data lifecycle and keep costs predictable.
- Scale – trillions of objects, virtually unlimited throughput.
Iceberg treats S3 as a dumb but durable object store, while metadata and catalogs handle the smarts. This separation of storage from compute gives enterprises elasticity: scale out Athena or Spark clusters for heavy workloads, scale back to zero when idle.
AWS Glue’s Role
AWS Glue ties the ecosystem together. Its responsibilities:
- Metadata catalog – a Hive-compatible catalog that Iceberg can use for table definitions, schema evolution, and versioning.
- ETL orchestration – managed PySpark jobs for transformations, compaction, and data hygiene.
- Schema tracking – Glue crawlers detect schema drift, though with Iceberg, you’ll often control this explicitly.
Glue makes Iceberg tables queryable from Athena, Redshift Spectrum, and EMR. It’s also where you schedule maintenance tasks like compaction, which are critical for controlling small-file bloat.
Hands-On Examples
1. Create an Iceberg Table in Athena
CREATE TABLE iceberg_db.transactions
(
transaction_id BIGINT,
user_id BIGINT,
amount DECIMAL(10,2),
transaction_date DATE
)
PARTITIONED BY (transaction_date)
LOCATION 's3://my-data-lake/transactions/'
TBLPROPERTIES (
'table_type'='ICEBERG',
'format'='PARQUET'
);
This defines an Iceberg-backed table in Glue using S3 storage. The manifest and metadata files are automatically managed.
2. Schema Evolution With ALTER TABLE
Suppose the upstream system starts sending a new column payment_method. With Iceberg, you can evolve the schema safely:
ALTER TABLE iceberg_db.transactions
ADD COLUMN payment_method STRING;Downstream queries immediately see the new column, with historical data backfilled as NULL. No need to rebuild or reload partitions.
3. Time Travel Query
You discover that yesterday’s ETL introduced bad data. Iceberg snapshots let you roll back or query a prior state:
SELECT *
FROM iceberg_db.transactions
FOR VERSION AS OF '2025-09-28T10:00:00.000Z';This instantly queries the table as it existed at the snapshot timestamp—crucial for audits or root cause analysis.
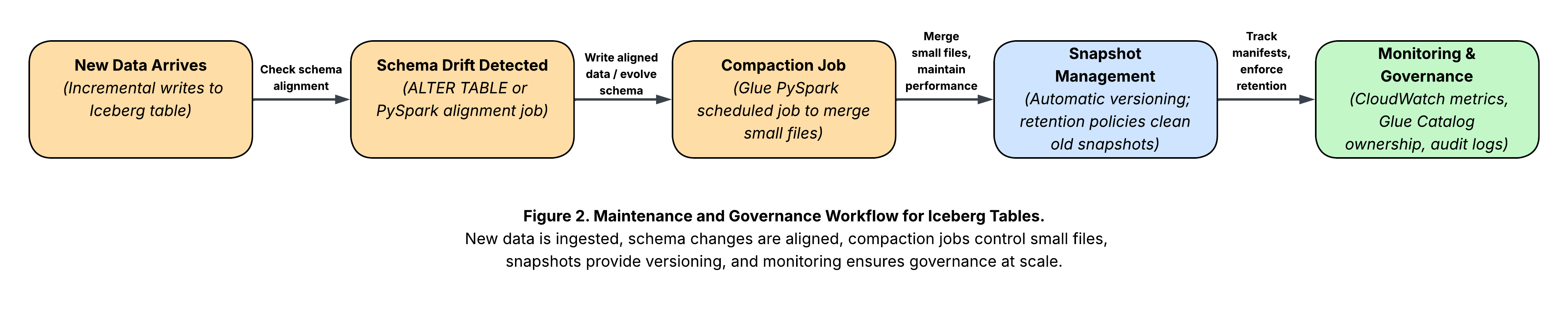
4. Glue PySpark Compaction Job
Compaction reduces thousands of small files into fewer large files, improving query performance.
import sys
from awsglue.context import GlueContext
from pyspark.context import SparkContext
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
# Read Iceberg table
df = spark.read.format("iceberg").load("iceberg_db.transactions")
# Repartition to larger files
df.repartition(10).writeTo("iceberg_db.transactions").overwritePartitions()
Here, repartitioning controls file sizes. Run this as a scheduled Glue job to keep tables performant.
5. Glue Job for Schema Evolution Handling
You can handle schema drift explicitly in PySpark by aligning new data before writing:
from pyspark.sql.functions import lit
# Incoming data
incoming_df = spark.read.json("s3://incoming/new_transactions/")
# Align schema with Iceberg table
aligned_df = incoming_df.withColumn("payment_method",
lit(None).cast("string"))
aligned_df.writeTo("iceberg_db.transactions").append()This guarantees that even if the source system sends partial fields, the Iceberg schema remains consistent.
Enterprise Use Cases
- Schema evolution at scale. Ingesting from dozens of source systems, each evolving independently, is inevitable. Iceberg’s schema evolution lets you adapt incrementally, without downtime.
- Audit and compliance. Time travel enables GDPR, SOX, and HIPAA audit scenarios — query exactly what a report looked like last year. Combined with Glue Catalog lineage, auditors get confidence in reproducibility.
- Right to forget. Deleting specific user rows (
DELETE FROM iceberg_db.transactions WHERE user_id=12345) is ACID-safe in Iceberg, unlike traditional Hive-style lakes, where deletes were “best effort.” - Optimizing cloud spend. Scheduled compaction reduces small-file query overhead, often cutting Athena/Trino query costs by 30 – 40%. Lifecycle policies in S3 further tier older snapshots to Glacier for pennies.
Best Practices
- Partitioning strategies – avoid over-partitioning. Partition by
transaction_dateor bucketing by user ID; don’t create a directory per hour unless workloads demand it. - Compaction tuning – aim for 128–512 MB file sizes. Schedule Glue compaction nightly or weekly based on ingestion rates.
- Catalog integration – centralize schema management in Glue. Avoid rogue pipelines creating unmanaged Iceberg tables.
- Monitoring – track manifest growth, snapshot retention, and small-file counts. Tools like CloudWatch or custom metrics help identify drift.
- Governance – enforce table ownership and schema review. Iceberg makes evolution easy, but chaos without governance will still sink you.
Conclusion
The combination of Apache Iceberg, AWS Glue, and Amazon S3 unlocks the full promise of the modern data lake: open, scalable, reliable, and cost-optimized.
- Iceberg provides transactional guarantees, schema evolution, and time travel.
- S3 gives durable, cost-effective scale.
- Glue serves as the metadata and orchestration layer, keeping everything queryable and governed.
From personal experience across healthcare, finance, and large-scale enterprise environments, this stack consistently drives cost savings, reliability, and developer velocity. Instead of fighting schema drift, small files, and broken partitions, teams can focus on delivering analytics and ML pipelines that move the business.
Iceberg on Glue over S3 isn’t just another shiny tool — it’s the foundation of the next-generation enterprise data lake.
Opinions expressed by DZone contributors are their own.
Comments