Use Lucene’s MMapDirectory on 64bit Platforms, Please!
By
 ·
·
Interview
·
·
Interview
Likes
(1)
Likes
There are no likes...yet! 👀
Be the first to like this post!
It looks like you're not logged in.
Sign in to see who liked this post!
Comment
Save
13.5K Views
Join the DZone community and get the full member experience.
Join For FreeDon’t be afraid – Some clarification to common misunderstandings
Since version 3.1, Apache Lucene and Solr use MMapDirectory
by default on 64bit Windows and Solaris systems; since version 3.3 also
for 64bit Linux systems. This change lead to some confusion among
Lucene and Solr users, because suddenly their systems started to behave
differently than in previous versions. On the Lucene and Solr mailing
lists a lot of posts arrived from users asking why their Java
installation is suddenly consuming three times their physical memory or
system administrators complaining about heavy resource usage. Also
consultants were starting to tell people that they should not use MMapDirectory and change their solrconfig.xml to work instead with slow SimpleFSDirectory or NIOFSDirectory (which is much slower on Windows, caused by a JVM bug #6265734). From the point of view of the Lucene committers, who carefully decided that using MMapDirectory is
the best for those platforms, this is rather annoying, because they
know, that Lucene/Solr can work with much better performance than
before. Common misinformation about the background of this change causes
suboptimal installations of this great search engine everywhere.
In this blog post, I will try to explain the basic operating system facts regarding virtual memory handling in the kernel and how this can be used to largely improve performance of Lucene (“VIRTUAL MEMORY for DUMMIES”). It will also clarify why the blog and mailing list posts done by various people are wrong and contradict the purpose of MMapDirectory. In the second part I will show you some configuration details and settings you should take care of to prevent errors like “mmap failed” and suboptimal performance because of stupid Java heap allocation.
In this blog post, I will try to explain the basic operating system facts regarding virtual memory handling in the kernel and how this can be used to largely improve performance of Lucene (“VIRTUAL MEMORY for DUMMIES”). It will also clarify why the blog and mailing list posts done by various people are wrong and contradict the purpose of MMapDirectory. In the second part I will show you some configuration details and settings you should take care of to prevent errors like “mmap failed” and suboptimal performance because of stupid Java heap allocation.
Virtual Memory[1]
Let’s start with your operating system’s kernel: The naive approach to
do I/O in software is the way, you have done this since the 1970s –
the pattern is simple: whenever you have to work with data on disk, you
execute a syscall to your operating system kernel, passing a pointer to some buffer (e.g. a byte[]
array in Java) and transfer some bytes from/to disk. After that you
parse the buffer contents and do your program logic. If you don’t want
to do too many syscalls (because those may cost a lot processing power),
you generally use large buffers in your software, so synchronizing the
data in the buffer with your disk needs to be done less often. This is
one reason, why some people suggest to load the whole Lucene index into
Java heap memory (e.g., by using RAMDirectory).
But all modern operating systems like Linux, Windows (NT+), MacOS X, or Solaris provide a much better approach to do this 1970s style of code by using their sophisticated file system caches and memory management features. A feature called “virtual memory” is a good alternative to handle very large and space intensive data structures like a Lucene index. Virtual memory is an integral part of a computer architecture; implementations require hardware support, typically in the form of a memory management unit (MMU) built into the CPU. The way how it works is very simple: Every process gets his own virtual address space where all libraries, heap and stack space is mapped into. This address space in most cases also start at offset zero, which simplifies loading the program code because no relocation of address pointers needs to be done. Every process sees a large unfragmented linear address space it can work on. It is called “virtual memory” because this address space has nothing to do with physical memory, it just looks like so to the process. Software can then access this large address space as if it were real memory without knowing that there are other processes also consuming memory and having their own virtual address space. The underlying operating system works together with the MMU (memory management unit) in the CPU to map those virtual addresses to real memory once they are accessed for the first time. This is done using so called page tables, which are backed by TLBs located in the MMU hardware (translation lookaside buffers, they cache frequently accessed pages). By this, the operating system is able to distribute all running processes’ memory requirements to the real available memory, completely transparent to the running programs.
But all modern operating systems like Linux, Windows (NT+), MacOS X, or Solaris provide a much better approach to do this 1970s style of code by using their sophisticated file system caches and memory management features. A feature called “virtual memory” is a good alternative to handle very large and space intensive data structures like a Lucene index. Virtual memory is an integral part of a computer architecture; implementations require hardware support, typically in the form of a memory management unit (MMU) built into the CPU. The way how it works is very simple: Every process gets his own virtual address space where all libraries, heap and stack space is mapped into. This address space in most cases also start at offset zero, which simplifies loading the program code because no relocation of address pointers needs to be done. Every process sees a large unfragmented linear address space it can work on. It is called “virtual memory” because this address space has nothing to do with physical memory, it just looks like so to the process. Software can then access this large address space as if it were real memory without knowing that there are other processes also consuming memory and having their own virtual address space. The underlying operating system works together with the MMU (memory management unit) in the CPU to map those virtual addresses to real memory once they are accessed for the first time. This is done using so called page tables, which are backed by TLBs located in the MMU hardware (translation lookaside buffers, they cache frequently accessed pages). By this, the operating system is able to distribute all running processes’ memory requirements to the real available memory, completely transparent to the running programs.
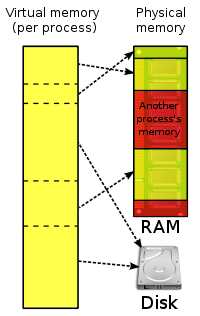
Schematic drawing of virtual memory
(image from Wikipedia [1], http://en.wikipedia.org/wiki/File:Virtual_memory.svg, licensed by CC BY-SA 3.0)
{kind=link}
By using this virtualization, there is one more thing, the operating system can do: If there is not enough physical memory, it can decide to “swap out” pages no longer used by the processes, freeing physical memory for other processes or caching more important file system operations. Once a process tries to access a virtual address, which was paged out, it is reloaded to main memory and made available to the process. The process does not have to do anything, it is completely transparent. This is a good thing to applications because they don’t need to know anything about the amount of memory available; but also leads to problems for very memory intensive applications like Lucene.
Lucene & Virtual Memory
Let’s take the example of loading the whole index or large parts of it into “memory” (we already know, it is only virtual memory). If we allocate a RAMDirectory and
load all index files into it, we are working against the operating
system: The operating system tries to optimize disk accesses, so it
caches already all disk I/O in physical memory. We copy all these cache
contents into our own virtual address space, consuming horrible amounts
of physical memory (and we must wait for the copy operation to take
place!). As physical memory is limited, the operating system may, of course, decide to swap out our large RAMDirectory and where does it land? – On disk again (in the OS swap file)! In fact, we are fighting against our O/S kernel who pages out all stuff we loaded from disk [2]. So RAMDirectory is not a good idea to optimize index loading times! Additionally, RAMDirectory has
also more problems related to garbage collection and concurrency.
Because the data residing in swap space, Java’s garbage collector has a
hard job to free the memory in its own heap management. This leads to
high disk I/O, slow index access times, and minute-long latency in your
searching code caused by the garbage collector driving crazy.
On the other hand, if we don’t use RAMDirectory to buffer our index and use NIOFSDirectory or SimpleFSDirectory, we have to pay another price: Our code has to do a lot of syscalls to the O/S kernel to copy blocks of data between the disk or filesystem cache and our buffers residing in Java heap. This needs to be done on every search request, over and over again.
On the other hand, if we don’t use RAMDirectory to buffer our index and use NIOFSDirectory or SimpleFSDirectory, we have to pay another price: Our code has to do a lot of syscalls to the O/S kernel to copy blocks of data between the disk or filesystem cache and our buffers residing in Java heap. This needs to be done on every search request, over and over again.
Memory Mapping Files
The solution to the above issues is MMapDirectory, which uses virtual memory and a kernel feature called “mmap” [3] to access the disk files.
Basically mmap does the same like handling the Lucene index as a swap file. The mmap() syscall tells the O/S kernel to virtually map our whole index files into the previously described virtual address space, and make them look like RAM available to our Lucene process. We can then access our index file on disk just like it would be a large byte[] array (in Java this is encapsulated by a ByteBuffer interface to make it safe for use by Java code). If we access this virtual address space from the Lucene code we don’t need to do any syscalls, the processor’s MMU and TLB handles all the mapping for us. If the data is only on disk, the MMU will cause an interrupt and the O/S kernel will load the data into file system cache. If it is already in cache, MMU/TLB map it directly to the physical memory in file system cache. It is now just a native memory access, nothing more! We don’t have to take care of paging in/out of buffers, all this is managed by the O/S kernel. Furthermore, we have no concurrency issue, the only overhead over a standard byte[] array is some wrapping caused by Java’s ByteBuffer interface (it is still slower than a real byte[] array, but that is the only way to use mmap from Java and is much faster than all other directory implementations shipped with Lucene). We also waste no physical memory, as we operate directly on the O/S cache, avoiding all Java GC issues described before.
What does this all mean to our Lucene/Solr application?
In our previous approaches, we were relying on using a syscall to copy the data between the file system cache and our local Java heap. How about directly accessing the file system cache? This is what mmap does!
Basically mmap does the same like handling the Lucene index as a swap file. The mmap() syscall tells the O/S kernel to virtually map our whole index files into the previously described virtual address space, and make them look like RAM available to our Lucene process. We can then access our index file on disk just like it would be a large byte[] array (in Java this is encapsulated by a ByteBuffer interface to make it safe for use by Java code). If we access this virtual address space from the Lucene code we don’t need to do any syscalls, the processor’s MMU and TLB handles all the mapping for us. If the data is only on disk, the MMU will cause an interrupt and the O/S kernel will load the data into file system cache. If it is already in cache, MMU/TLB map it directly to the physical memory in file system cache. It is now just a native memory access, nothing more! We don’t have to take care of paging in/out of buffers, all this is managed by the O/S kernel. Furthermore, we have no concurrency issue, the only overhead over a standard byte[] array is some wrapping caused by Java’s ByteBuffer interface (it is still slower than a real byte[] array, but that is the only way to use mmap from Java and is much faster than all other directory implementations shipped with Lucene). We also waste no physical memory, as we operate directly on the O/S cache, avoiding all Java GC issues described before.
What does this all mean to our Lucene/Solr application?
- We should not work against the operating system anymore, so allocate as less as possible heap space (-Xmx Java option). Remember, our index accesses rely on passed directly to O/S cache! This is also very friendly to the Java garbage collector.
- Free as much as possible physical memory to be available for the O/S kernel as file system cache. Remember, our Lucene code works directly on it, so reducing the number of paging/swapping between disk and memory. Allocating too much heap to our Lucene application hurts performance! Lucene does not require it with MMapDirectory.
Why does this only work as expected on operating systems and Java virtual machines with 64bit?
One limitation of 32bit platforms is the size of pointers, they can refer to any address within 0 and 232-1,
which is 4 Gigabytes. Most operating systems limit that address space
to 3 Gigabytes because the remaining address space is reserved for use
by device hardware and similar things. This means the overall linear
address space provided to any process is limited to 3 Gigabytes, so you
cannot map any file larger than that into this “small” address space to
be available as big byte[]
array. And when you mapped that one large file, there is no virtual
space (address like “house number”) available anymore. As physical
memory sizes in current systems already have gone beyond that size,
there is no address space available to make use for mapping files
without wasting resources (in our case “address space”, not physical memory!).
On 64bit platforms this is different: 264-1 is a very large number, a number in excess of 18 quintillion bytes, so there is no real limit in address space. Unfortunately, most hardware (the MMU, CPU’s bus system) and operating systems are limiting this address space to 47 bits for user mode applications (Windows: 43 bits) [4]. But there is still much of addressing space available to map terabytes of data.
On 64bit platforms this is different: 264-1 is a very large number, a number in excess of 18 quintillion bytes, so there is no real limit in address space. Unfortunately, most hardware (the MMU, CPU’s bus system) and operating systems are limiting this address space to 47 bits for user mode applications (Windows: 43 bits) [4]. But there is still much of addressing space available to map terabytes of data.
Common misunderstandings
If you have read carefully what I have told you about virtual memory, you can easily verify that the following is true:
- MMapDirectory does not consume additional memory and the size of mapped index files is not limited by the physical memory available on your server. By mmap() files, we only reserve address space not memory! Remember, address space on 64bit platforms is for free!
- MMapDirectory will not load the whole index into physical memory. Why should it do this? We just ask the operating system to map the file into address space for easy access, by no means we are requesting more. Java and the O/S optionally provide the option to try loading the whole file into RAM (if enough is available), but Lucene does not use that option (we may add this possibility in a later version).
- MMapDirectory does not overload the server when “top” reports horrible amounts of memory. “top” (on Linux) has three columns related to memory: “VIRT”, “RES”, and “SHR”. The first one (VIRT, virtual) is reporting allocated virtual address space (and that one is for free on 64 bit platforms!). This number can be multiple times of your index size or physical memory when merges are running in IndexWriter. If you have only one IndexReader open it should be approximately equal to allocated heap space (-Xmx) plus index size. It does not show physical memory used by the process. The second column (RES, resident) memory shows how much (physical) memory the process allocated for operating and should be in the size of your Java heap space. The last column (SHR, shared) shows how much of the allocated virtual address space is shared with other processes. If you have several Java applications using MMapDirectory to access the same index, you will see this number going up. Generally, you will see the space needed by shared system libraries, JAR files, and the process executable itself (which are also mmapped).
How to configure my operating system and Java VM to make optimal use of MMapDirectory?
First of all, default settings in Linux distributions and
Solaris/Windows are perfectly fine. But there are some paranoid system
administrators around, that want to control everything (with lack of
understanding). Those limit the maximum amount of virtual address space
that can be allocated by applications. So please check that “ulimit -v” and “ulimit -m” both report “unlimited”, otherwise it may happen that MMapDirectory reports “mmap failed”
while opening your index. If this error still happens on systems with
lot’s of very large indexes, each of those with many segments, you may
need to tune your kernel parameters in /etc/sysctl.conf: The default value of vm.max_map_count
is 65530, you may need to raise it. I think, for Windows and Solaris
systems there are similar settings available, but it is up to the reader
to find out how to use them.
For configuring your Java VM, you should rethink your memory requirements: Give only the really needed amount of heap space and leave as much as possible to the O/S. As a rule of thumb: Don’t use more than ¼ of your physical memory as heap space for Java running Lucene/Solr, keep the remaining memory free for the operating system cache. If you have more applications running on your server, adjust accordingly. As usual the more physical memory the better, but you don’t need as much physical memory as your index size. The kernel does a good job in paging in frequently used pages from your index.
A good possibility to check that you have configured your system optimally is by looking at both "top" (and correctly interpreting it, see above) and the similar command "iotop" (can be installed, e.g., on Ubuntu Linux by "apt-get install iotop"). If your system does lots of swap in/swap out for the Lucene process, reduce heap size, you possibly used too much. If you see lot's of disk I/O, buy more RUM (Simon Willnauer) so mmapped files don't need to be paged in/out all the time, and finally: buy SSDs.
Happy mmapping!
For configuring your Java VM, you should rethink your memory requirements: Give only the really needed amount of heap space and leave as much as possible to the O/S. As a rule of thumb: Don’t use more than ¼ of your physical memory as heap space for Java running Lucene/Solr, keep the remaining memory free for the operating system cache. If you have more applications running on your server, adjust accordingly. As usual the more physical memory the better, but you don’t need as much physical memory as your index size. The kernel does a good job in paging in frequently used pages from your index.
A good possibility to check that you have configured your system optimally is by looking at both "top" (and correctly interpreting it, see above) and the similar command "iotop" (can be installed, e.g., on Ubuntu Linux by "apt-get install iotop"). If your system does lots of swap in/swap out for the Lucene process, reduce heap size, you possibly used too much. If you see lot's of disk I/O, buy more RUM (Simon Willnauer) so mmapped files don't need to be paged in/out all the time, and finally: buy SSDs.
Happy mmapping!
Bibliography
operating system
Lucene
Memory (storage engine)
Space (architecture)
Java (programming language)
File system
Cache (computing)
application
Kernel (operating system)
Published at DZone with permission of Uwe Schindler, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments