Using In-Memory Database in MuleSoft With Apache Derby
You have a file with two million records and you need to filter the values to find a certain match. How do you query such a database?
Join the DZone community and get the full member experience.
Join For FreeLet's consider a scenario in which we have to scan a large file (say, with two million records) and filter a few values after a match is found in the file. We can read the file and put it into an in-memory database and later query the database to get the results.
Here's how to do it.
1. Download the Apache Derby JAR file here.
2. Import the derby.jar file into the Mule workspace from db-derby-10.13.1.1-lib\lib.

3. Add the below Spring bean in the global element configuration section.
<!--The below spring bean is creating a derby database named "mydemodb". -->
<spring:beans>
<spring:bean id="datasource" name="datasource" class="org.enhydra.jdbc.standard.StandardXADataSource" destroy-method="shutdown">
<spring:property name="driverName" value="org.apache.derby.jdbc.EmbeddedDriver"/>
<spring:property name="url" value="jdbc:derby:mydemodb"/>
</spring:bean>
</spring:beans>
<!--The below, creates a connection to the derby datbase -->
<db:derby-config name="Derby_Configuration" url="jdbc:derby:mydemodb;create=true" doc:name="Derby Configuration"/>4. The database connection can also be done using Anypoint Database connectors.

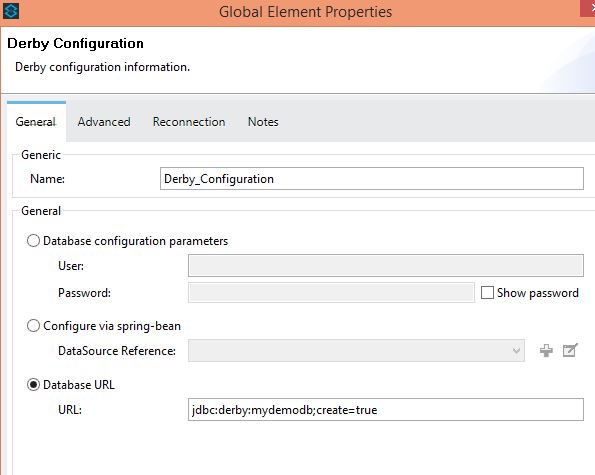
Note: The test connection might not be successful, but the flow will run fine.
5. Now, to create a table in the database, we will execute a Java code DBInitialization. The Java code can be executed in a Spring bean as shown below. Put this Spring bean in the global Mule configuration component.
<spring:beans>
<spring:bean id="dbinitialization" name="dbinit" class="utils.memorydb.DBInitialization" scope="singleton"/>
</spring:beans><spring:beans>
<spring:bean id="dbinitialization" name="dbinit" class="utils.memorydb.DBInitialization" scope="singleton"/>
</spring:beans>

Note: This can be done using Mule database connectors, as well. Here, we have used Java code to create the table as we need to re-create the table, each time the flow starts.
Below is the Java code to create the table in Derby database mydemodb. The function initCreateTable is dropping and re-creating the table it already existed. (This can be handy in requirements where the table is to be reloaded in every transaction.)
package utils.memorydb;
import java.sql.Connection;
import java.sql.DatabaseMetaData;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class DBInitialization {
public DBInitialization() throws Exception {
this.initCreateTable();
}
public void initCreateTable() throws Exception {
String dbURL = "jdbc:derby:mydemodb;create=true";
Connection conn = null;
try {
Class.forName("org.apache.derby.jdbc.EmbeddedDriver").newInstance();
// Get a connection
conn = DriverManager.getConnection(dbURL);
DatabaseMetaData dbm = conn.getMetaData();
Statement stmt = conn.createStatement();
String tables[] = {"IL_FILE"};
for (int i = 0 ; i< tables.length; i++) {
ResultSet check = dbm.getTables(null,null,tables[i],null);
if (check.next()) {
stmt.executeUpdate("DROP TABLE "+ tables[i]);
stmt.executeUpdate("CREATE TABLE "+ tables[i] +" (A VARCHAR(50), B VARCHAR(50), C VARCHAR(50), D VARCHAR(50))");
}
else {
stmt.executeUpdate("CREATE TABLE "+ tables[i] +" (A VARCHAR(50), B VARCHAR(50), C VARCHAR(50), D VARCHAR(50))");
}
}
} catch (java.sql.SQLException sqle) {
sqle.printStackTrace();
throw sqle;
}
}
}6. The Mule flow that will read the large file and update the derby table IL_FILE in bulk mode is shown below:

Flow in XML:
<?xml version="1.0" encoding="UTF-8"?>
<mule xmlns:cluster="http://www.mulesoft.org/schema/mule/ee/cluster" xmlns:http="http://www.mulesoft.org/schema/mule/http" xmlns:db="http://www.mulesoft.org/schema/mule/db" xmlns:jdbc-ee="http://www.mulesoft.org/schema/mule/ee/jdbc"
xmlns:batch="http://www. . . . .
. . . . . . . . . . .
. . . . . . . . . .
http://www.mulesoft.org/schema/mule/http http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd">
<file:connector name="File" autoDelete="false" streaming="false" validateConnections="true" doc:name="File"/>
<spring:beans>
<spring:bean id="datasource" name="datasource" class="org.enhydra.jdbc.standard.StandardXADataSource" destroy-method="shutdown">
<spring:property name="driverName" value="org.apache.derby.jdbc.EmbeddedDriver"/>
<spring:property name="url" value="jdbc:derby:mydemodb"/>
</spring:bean>
<spring:bean id="dbinitialization" name="dbinit" class="utils.memorydb.DBInitialization" scope="singleton"/>
</spring:beans>
<db:derby-config name="Derby_Configuration" url="jdbc:derby:mydemodb;create=true" doc:name="Derby Configuration"/>
<!-- Flow -->
<flow name="myDemoDerbyDatabaseFlow">
<poll doc:name="Poll">
<fixed-frequency-scheduler frequency="1000" timeUnit="DAYS"/>
<logger message="****************************Started*****************************8" level="INFO" doc:name="Logger"/>
</poll>
<mulerequester:request resource="file://D:/Accounts/RB/POC/UK_EU_DSFCST_IL.csv?autoDelete=false" doc:name="IL_File_Read"/>
<set-payload value="I_A,I_B,I_C,I_D#['\n']#[message.payloadAs(java.lang.String)]" mimeType="application/csv" doc:name="Set Payload"/>
<!-- Creating ArrayList for Bulk Insert -->
<dw:transform-message metadata:id="e71ef32c-63ce-49ca-bbed-3b7f573ee4a2" doc:name="Iterable_For_Bulk_Update">
<dw:input-payload mimeType="application/csv"/>
<dw:set-payload><![CDATA[%dw 1.0
%output application/java
---
payload map ((payload01 , indexOfPayload01) -> {
A: payload01[0],
B: payload01[1],
C: payload01[2],
D: payload01[3]
})]]></dw:set-payload>
</dw:transform-message>
<!-- Bulk Insertion in Derby table -->
<db:insert config-ref="Derby_Configuration" bulkMode="true" doc:name="BULK_Inset_ILFile">
<db:parameterized-query><![CDATA[INSERT INTO IL_FILE (A,B,C,D) VALUES (#[payload.A], #[payload.B], #[payload.C], #[payload.D])]]></db:parameterized-query>
</db:insert>
<!-- Select query execution from Derby table -->
<db:select config-ref="Derby_Configuration" doc:name="QueryDerby">
<db:parameterized-query><![CDATA[Select * from IL_FILE
where A='24903' and B='0035069' and C='20161107']]></db:parameterized-query>
</db:select>
<logger message="*********************End Transforming**********************" level="INFO" doc:name="Logger"/>
</flow>
</mule>Query output:

Opinions expressed by DZone contributors are their own.
Comments