Using Apache Kafka for Integration and Data Processing Pipelines with Spring
Join the DZone community and get the full member experience.
Join For Freewritten by josh long on the spring blog
applications generated more and more data than ever before and a huge part of the challenge - before it can even be analyzed - is accommodating the load in the first place. apache’s kafka meets this challenge. it was originally designed by linkedin and subsequently open-sourced in 2011. the project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. the design is heavily influenced by transaction logs. it is a messaging system, similar to traditional messaging systems like rabbitmq, activemq, mqseries, but it’s ideal for log aggregation, persistent messaging, fast (_hundreds_ of megabytes per second!) reads and writes, and can accommodate numerous clients. naturally, this makes it perfect for cloud-scale architectures!
kafka powers many large production systems . linkedin uses it for activity data and operational metrics to power the linkedin news feed, and linkedin today, as well as offline analytics going into hadoop. twitter uses it as part of their stream-processing infrastructure. kafka powers online-to-online and online-to-offline messaging at foursquare. it is used to integrate foursquare monitoring and production systems with hadoop-based offline infrastructures. square uses kafka as a bus to move all system events through square’s various data centers. this includes metrics, logs, custom events, and so on. on the consumer side, it outputs into splunk, graphite, or esper-like real-time alerting. netflix uses it for 300-600bn messages per day. it’s also used by airbnb, mozilla, goldman sachs, tumblr, yahoo, paypal, coursera, urban airship, hotels.com, and a seemingly endless list of other big-web stars. clearly, it’s earning its keep in some powerful systems!
installing apache kafka
there are many different ways to get apache kafka installed. if you’re on osx, and you’re using homebrew, it can be as simple as
brew install kafka
. you can also
download the latest distribution from apache
. i downloaded
kafka_2.10-0.8.2.1.tgz
, unzipped it, and then within you’ll find there’s a distribution of
apache zookeeper
as well as kafka, so nothing else is required. i installed apache kafka in my
$home
directory, under another directory,
bin
, then i created an environment variable,
kafka_home
, that points to
$home/bin/kafka
.
start apache zookeeper first, specifying where the configuration properties file it requires is:
$kafka_home/bin/zookeeper-server-start.sh $kafka_home/config/zookeeper.properties
the apache kafka distribution comes with default configuration files for both zookeeper and kafka, which makes getting started easy. you will in more advanced use cases need to customize these files.
then start apache kafka. it too requires a configuration file, like this:
$kafka_home/bin/kafka-server-start.sh $kafka_home/config/server.properties
the
server.properties
file contains, among other things, default values for where to connect to apache zookeeper (
zookeeper.connect
), how much data should be sent across sockets, how many partitions there are by default, and the broker id (
broker.id
- which must be unique across a cluster).
there are other scripts in the same directory that can be used to send and receive dummy data, very handy in establishing that everything’s up and running!
now that apache kafka is up and running, let’s look at working with apache kafka from our application.
some high level concepts..
a kafka broker cluster consists of one or more servers where each may have one or more broker processes running. apache kafka is designed to be highly available; there are no master nodes. all nodes are interchangeable. data is replicated from one node to another to ensure that it is still available in the event of a failure.
in kafka, a topic is a category, similar to a jms destination or both an amqp exchange and queue. topics are partitioned, and the choice of which of a topic’s partition a message should be sent to is made by the message producer. each message in the partition is assigned a unique sequenced id, its offset . more partitions allow greater parallelism for consumption, but this will also result in more files across the brokers.
producers send messages to apache kafka broker topics and specify the partition to use for every message they produce. message production may be synchronous or asynchronous. producers also specify what sort of replication guarantees they want.
consumers listen for messages on topics and process the feed of published messages. as you’d expect if you’ve used other messaging systems, this is usually (and usefully!) asynchronous.
like spring xd and numerous other distributed system, apache kafka uses apache zookeeper to coordinate cluster information. apache zookeeper provides a shared hierarchical namespace (called znodes ) that nodes can share to understand cluster topology and availability (yet another reason that spring cloud has forthcoming support for it..).
zookeeper is very present in your interactions with apache kafka. apache kafka has, for example, two different apis for acting as a consumer. the higher level api is simpler to get started with and it handles all the nuances of handling partitioning and so on. it will need a reference to a zookeeper instance to keep the coordination state.
let’s turn now turn to using apache kafka with spring.
using apache kafka with spring integration
the recently released apache kafka 1.1 spring integration adapter is very powerful, and provides inbound adapters for working with both the lower level apache kafka api as well as the higher level api.
the adapter, currently, is xml-configuration first, though work is already underway on a spring integration java configuration dsl for the adapter and milestones are available. we’ll look at both here, now.
to make all these examples work, i added the libs-milestone-local maven repository and used the following dependencies:
- org.apache.kafka:kafka_2.10:0.8.1.1
- org.springframework.boot:spring-boot-starter-integration:1.2.3.release
- org.springframework.boot:spring-boot-starter:1.2.3.release
- org.springframework.integration:spring-integration-kafka:1.1.1.release
- org.springframework.integration:spring-integration-java-dsl:1.1.0.m1
using the spring integration apache kafka with the spring integration xml dsl
first, let’s look at how to use the spring integration outbound adapter to send
message<t>
instances from a spring integration flow to an external apache kafka instance. the example is fairly straightforward: a spring integration
channel
named
inputtokafka
acts as a conduit that forwards
message<t>
messages to the outbound adapter,
kafkaoutboundchanneladapter
. the adapter itself can take its configuration from the defaults specified in the
kafka:producer-context
element or it from the adapter-local configuration overrides. there may be one or many configurations in a given
kafka:producer-context
element.
<?xml version="1.0" encoding="utf-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/xmlschema-instance"
xmlns:int="http://www.springframework.org/schema/integration"
xmlns:int-kafka="http://www.springframework.org/schema/integration/kafka"
xmlns:task="http://www.springframework.org/schema/task"
xsi:schemalocation="http://www.springframework.org/schema/integration/kafka http://www.springframework.org/schema/integration/kafka/spring-integration-kafka.xsd
http://www.springframework.org/schema/integration http://www.springframework.org/schema/integration/spring-integration.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task.xsd">
<int:channel id="inputtokafka">
<int:queue/>
</int:channel>
<int-kafka:outbound-channel-adapter
id="kafkaoutboundchanneladapter"
kafka-producer-context-ref="kafkaproducercontext"
channel="inputtokafka">
<int:poller fixed-delay="1000" time-unit="milliseconds" receive-timeout="0" task-executor="taskexecutor"/>
</int-kafka:outbound-channel-adapter>
<task:executor id="taskexecutor" pool-size="5" keep-alive="120" queue-capacity="500"/>
<int-kafka:producer-context id="kafkaproducercontext">
<int-kafka:producer-configurations>
<int-kafka:producer-configuration broker-list="localhost:9092"
topic="event-stream"
compression-codec="default"/>
</int-kafka:producer-configurations>
</int-kafka:producer-context>
</beans>
here’s the java code from a spring boot application to trigger message sends using the outbound adapter by sending messages into the incoming
inputtokafka
messagechannel
.
package xml;
import org.apache.commons.logging.log;
import org.apache.commons.logging.logfactory;
import org.springframework.beans.factory.annotation.qualifier;
import org.springframework.boot.commandlinerunner;
import org.springframework.boot.springapplication;
import org.springframework.boot.autoconfigure.springbootapplication;
import org.springframework.context.annotation.bean;
import org.springframework.context.annotation.dependson;
import org.springframework.context.annotation.importresource;
import org.springframework.integration.config.enableintegration;
import org.springframework.messaging.messagechannel;
import org.springframework.messaging.support.genericmessage;
@springbootapplication
@enableintegration
@importresource("/xml/outbound-kafka-integration.xml")
public class demoapplication {
private log log = logfactory.getlog(getclass());
@bean
@dependson("kafkaoutboundchanneladapter")
commandlinerunner kickoff(@qualifier("inputtokafka") messagechannel in) {
return args -> {
for (int i = 0; i < 1000; i++) {
in.send(new genericmessage<>("#" + i));
log.info("sending message #" + i);
}
};
}
public static void main(string args[]) {
springapplication.run(demoapplication.class, args);
}
}
using the new apache kafka spring integration java configuration dsl
shortly after the spring integration 1.1 release, spring integration rockstar
artem bilan
got to work
on adding a spring integration java configuration dsl analog
and the result is a thing of beauty! it’s not yet ga (you need to add the
libs-milestone
repository for now), but i encourage you to try it out and kick the tires. it’s working well for me and the spring integration team are always keen on getting early feedback whenever possible! here’s an example that demonstrates both sending messages and consuming them from two different
integrationflow
s. the producer is similar to the example xml above.
new in this example is the polling consumer. it is batch-centric, and will pull down all the messages it sees at a fixed interval. in our code, the message received will be a map that contains as its keys the topic and as its value another map with the partition id and the batch (in this case, of 10 records), of records read. there is a
messagelistenercontainer
-based alternative that processes messages as they come.
package jc;
import org.apache.commons.logging.log;
import org.apache.commons.logging.logfactory;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.beans.factory.annotation.qualifier;
import org.springframework.beans.factory.annotation.value;
import org.springframework.boot.commandlinerunner;
import org.springframework.boot.springapplication;
import org.springframework.boot.autoconfigure.springbootapplication;
import org.springframework.context.annotation.bean;
import org.springframework.context.annotation.configuration;
import org.springframework.context.annotation.dependson;
import org.springframework.integration.integrationmessageheaderaccessor;
import org.springframework.integration.config.enableintegration;
import org.springframework.integration.dsl.integrationflow;
import org.springframework.integration.dsl.integrationflows;
import org.springframework.integration.dsl.sourcepollingchanneladapterspec;
import org.springframework.integration.dsl.kafka.kafka;
import org.springframework.integration.dsl.kafka.kafkahighlevelconsumermessagesourcespec;
import org.springframework.integration.dsl.kafka.kafkaproducermessagehandlerspec;
import org.springframework.integration.dsl.support.consumer;
import org.springframework.integration.kafka.support.zookeeperconnect;
import org.springframework.messaging.messagechannel;
import org.springframework.messaging.support.genericmessage;
import org.springframework.stereotype.component;
import java.util.list;
import java.util.map;
/**
* demonstrates using the spring integration apache kafka java configuration dsl.
* thanks to spring integration ninja <a href="http://spring.io/team/artembilan">artem bilan</a>
* for getting the java configuration dsl working so quickly!
*
* @author josh long
*/
@enableintegration
@springbootapplication
public class demoapplication {
public static final string test_topic_id = "event-stream";
@component
public static class kafkaconfig {
@value("${kafka.topic:" + test_topic_id + "}")
private string topic;
@value("${kafka.address:localhost:9092}")
private string brokeraddress;
@value("${zookeeper.address:localhost:2181}")
private string zookeeperaddress;
kafkaconfig() {
}
public kafkaconfig(string t, string b, string zk) {
this.topic = t;
this.brokeraddress = b;
this.zookeeperaddress = zk;
}
public string gettopic() {
return topic;
}
public string getbrokeraddress() {
return brokeraddress;
}
public string getzookeeperaddress() {
return zookeeperaddress;
}
}
@configuration
public static class producerconfiguration {
@autowired
private kafkaconfig kafkaconfig;
private static final string outbound_id = "outbound";
private log log = logfactory.getlog(getclass());
@bean
@dependson(outbound_id)
commandlinerunner kickoff(
@qualifier(outbound_id + ".input") messagechannel in) {
return args -> {
for (int i = 0; i < 1000; i++) {
in.send(new genericmessage<>("#" + i));
log.info("sending message #" + i);
}
};
}
@bean(name = outbound_id)
integrationflow producer() {
log.info("starting producer flow..");
return flowdefinition -> {
consumer<kafkaproducermessagehandlerspec.producermetadataspec> spec =
(kafkaproducermessagehandlerspec.producermetadataspec metadata)->
metadata.async(true)
.batchnummessages(10)
.valueclasstype(string.class)
.<string>valueencoder(string::getbytes);
kafkaproducermessagehandlerspec messagehandlerspec =
kafka.outboundchanneladapter(
props -> props.put("queue.buffering.max.ms", "15000"))
.messagekey(m -> m.getheaders().get(integrationmessageheaderaccessor.sequence_number))
.addproducer(this.kafkaconfig.gettopic(),
this.kafkaconfig.getbrokeraddress(), spec);
flowdefinition
.handle(messagehandlerspec);
};
}
}
@configuration
public static class consumerconfiguration {
@autowired
private kafkaconfig kafkaconfig;
private log log = logfactory.getlog(getclass());
@bean
integrationflow consumer() {
log.info("starting consumer..");
kafkahighlevelconsumermessagesourcespec messagesourcespec = kafka.inboundchanneladapter(
new zookeeperconnect(this.kafkaconfig.getzookeeperaddress()))
.consumerproperties(props ->
props.put("auto.offset.reset", "smallest")
.put("auto.commit.interval.ms", "100"))
.addconsumer("mygroup", metadata -> metadata.consumertimeout(100)
.topicstreammap(m -> m.put(this.kafkaconfig.gettopic(), 1))
.maxmessages(10)
.valuedecoder(string::new));
consumer<sourcepollingchanneladapterspec> endpointconfigurer = e -> e.poller(p -> p.fixeddelay(100));
return integrationflows
.from(messagesourcespec, endpointconfigurer)
.<map<string, list<string>>>handle((payload, headers) -> {
payload.entryset().foreach(e -> log.info(e.getkey() + '=' + e.getvalue()));
return null;
})
.get();
}
}
public static void main(string[] args) {
springapplication.run(demoapplication.class, args);
}
}
the example makes heavy use of java 8 lambdas.
the producer spends a bit of time establishing how many messages will be sent in a single send operation, how keys and values are encoded (kafka only knows about
byte[]
arrays, after all) and whether messages should be sent synchronously or asynchronously. in the next line, we configure the outbound adapter itself and then define an
integrationflow
such that all messages get sent out via the kafka outbound adapter.
the consumer spends a bit of time establishing which zookeeper instance to connect to, how many messages to receive (10) in a batch, etc. once the message batches are recieved, they’re handed to the
handle
method where i’ve passed in a lambda that’ll enumerate the payload’s body and print it out. nothing fancy.
using apache kafka with spring xd
apache kafka is a message bus and it can be very powerful when used as an integration bus. however, it really comes into its own because it’s fast enough and scalable enough that it can be used to route big-data through processing pipelines. and if you’re doing data processing, you really want spring xd ! spring xd makes it dead simple to use apache kafka (as the support is built on the apache kafka spring integration adapter!) in complex stream-processing pipelines. apache kafka is exposed as a spring xd source - where data comes from - and a sink - where data goes to.
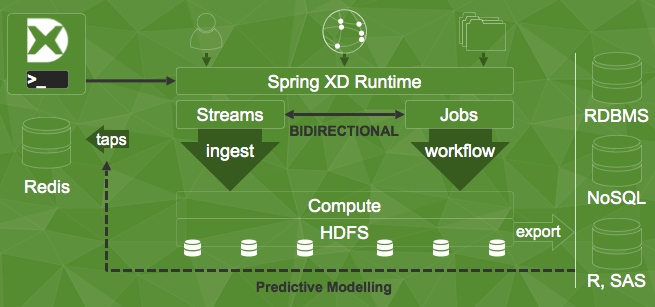
spring xd exposes a super convenient dsl for creating
bash
-like pipes-and-filter flows. spring xd is a centralized runtime that manages, scales, and monitors data processing jobs. it builds on top of spring integration, spring batch, spring data and spring for hadoop to be a one-stop data-processing shop. spring xd jobs read data from
sources
, run them through processing components that may count, filter, enrich or transform the data, and then write them to sinks.
spring integration and spring xd ninja
marius bogoevici
, who did a lot of the recent work in the spring integration and spring xd implementation of apache kafka, put together a really nice example demonstrating
how to get a full working spring xd and kafka flow working
. the
readme
walks you through getting apache kafka, spring xd and the requisite topics all setup. the essence, however, is when you use the spring xd shell and the shell dsl to compose a stream. spring xd components are named components that are pre-configured but have lots of parameters that you can override with
--..
arguments via the xd shell and dsl. (that dsl, by the way, is written by the amazing
andy clement
of spring expression language fame!) here’s an example that configures a stream to read data from an apache kafka source and then write the message a component called
log
, which is a sink.
log
, in this case, could be syslogd, splunk, hdfs, etc.
xd> stream create kafka-source-test --definition "kafka --zkconnect=localhost:2181 --topic=event-stream | log"--deploy
and that’s it! naturally, this is just a tase of spring xd, but hopefully you’ll agree the possibilities are tantalizing.
deploying a kafka server with lattice and docker
it’s easy to get an example kafka installation all setup using lattice , a distributed runtime that supports, among other container formats, the very popular docker image format. there’s a docker image provided by spotify that sets up a collocated zookeeper and kafka image . you can easily deploy this to a lattice cluster, as follows:
ltc create --run-as-root m-kafka spotify/kafkafrom there, you can easily scale the apache kafka instances and even more easily still consume apache kafka from your cloud-based services.
next steps
you can find the code for this blog on my github account .
we’ve only scratched the surface!
if you want to learn more (and why wouldn’t you?), then be sure to check out marius bogoevici and dr. mark pollack’s upcoming webinar on reactive data-pipelines using spring xd and apache kafka where they’ll demonstrate how easy it can be to use rxjava, spring xd and apache kafka!
Published at DZone with permission of Pieter Humphrey. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments