High-Performance Batch Processing Using Apache Spark and Spring Batch
Batch processing is dealing with a large amount of data; it actually is a method of running high-volume, repetitive data jobs and each job does a specific task.
Join the DZone community and get the full member experience.
Join For FreeBatch processing is dealing with a large amount of data; it actually is a method of running high-volume, repetitive data jobs and each job does a specific task without user interaction. This kind of processing started from the beginning of computation and still continues and perhaps new methods, algorithms, and tools are still being introduced. The entry point of Batch Processing Systems is offline data that gathered in any type like CSV, RDBMS, or well-formed JSON or XML files, after processing data and doing the specified process on every record of data, the desired output is generated.
Note: Batch processing and stream processing are two different concepts.
Batch Processing vs. Stream Processing
Sometimes these two concepts are considered the same, but in fact, they are completely different, in batch processing data is gathered once and sent to batch processing system, but stream processing continues and real-time, in batch processing systems, jobs are executed with scheduler and result of the processing could not be shown at the moment of sending jobs to the scheduler.
| Batch Processing | Stream Processing |
| Data is collected over time. | Data streams are continuous. |
| Once data is collected, it's sent to a batch processing system. | Data is processed piece-by-piece. |
| Batch processing is lengthy and it is meant for large quantitive of information that are not time-sensitive. | Stream processing in real-time, which means that result of processing is ready immediately. |
Case Study
Let‘s take a look at a sample system that relies on batch processing because my professional working area in developing banking and payment system most of my samples are on the banking systems; suppose that you have a Card Issuer system that issues named gift card for given names.

The input of this system is the name of the cardholder and the output is a gift card, it takes one second to issue each card, so good everything goes well until the system issues just one card, but consider a company wants to issue cards to 100000 of employees, it takes 100000 seconds if it is done sequentially, but if you have 100 thread each thread issues one card you can issue this number of cards 100x time faster.
Let's Do Something Crazy
Decide to develop a batch card issuer system. First of all, you need a reader that responsible for reading data from the source and deliver data to the processor.
staring point an abstract reader class:
import java.util.Collections;
import java.util.List;
public abstract class CardBatchReader {
final List <String> list;
public CardBatchReader(List<String> list){
this.list= Collections.unmodifiableList(list);
}
public abstract String getNextItem();
public Integer getNumberOfItems(){
return list.size();
}
}
Round-robin implementation for the reader:
xxxxxxxxxx
public class RoundRobinCardBatchReader extends CardBatchReader {
Integer idx = 0;
public RoundRobinCardBatchReader(List<String> cardNumberList) {
super(cardNumberList);
}
public String getNextItem() {
String result ;
result = list.get(idx);
idx++;
return result;
}
}
Sample card issuer service :
xxxxxxxxxx
public class CardIssuerService {
private static CardBatchReader reader;
public CardIssuerService(CardBatchReader reader){
this.reader=reader;
}
private void IssueCard(){
//suppose this is real card issue service
System.out.println("Card issued for "+reader.getNextItem()+" in thread :-> " +Thread.currentThread().getId());
}
public void IssueCards(){
IntStream.range(0,reader.getNumberOfItems()).parallel().forEach(
c->{
IssueCard();
}
);
}
}
Finally a batch executor:
xxxxxxxxxx
public class BatchExecuter {
static List<String> list= Arrays.asList(
"Alex",
"Bob",
"Mostafa",
"Yashar",
"Alireza",
"Fatemeh",
"Jalal",
"arash"
); //this data arrived from anywhere
public static void main(String args[]){
CardBatchReader reader=new RoundRobinCardBatchReader(list);
CardIssuerService cardIssuerService=new CardIssuerService(reader);
cardIssuerService.IssueCards();
}
}
Finally, result:
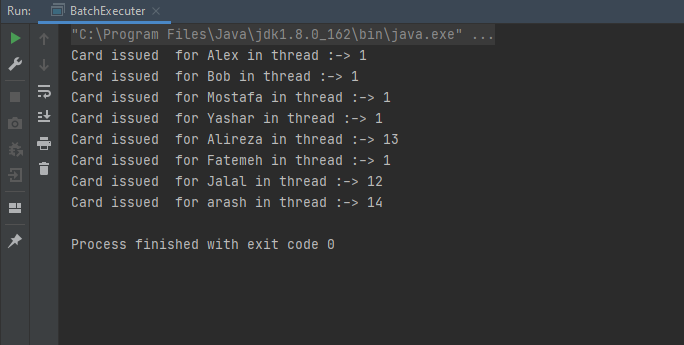
It was a simple snippet of codes that simulates a batch system as you can see for 8 people we have 8 threads, and each thread issues one card, it seems that we solve the problem!
But there is a couple of questions:
- Why each thread does not issue more than one card?
- How I can stop the batch?
- What happens for transaction management?
- And so many other questions...
All of these requirements can be applied to our code, but why? Other people have done all this for us before, why do we have to spend time doing this?
Batch processing systems mostly based on threads and parallel processing and everybody can design his own batch processing system, but why reinventing the wheel? There are many excellent batch processing frameworks that you can decide to choose and use them, Spring Batch and JBatch are two of them in this article we will just focus on Spring Batch.
Spring Batch
Spring Batch provides reusable functions that are essential in processing large volumes of records, including logging/tracing, transaction management, job processing statistics, job restart, skip, and resource management. It also provides more advanced technical services and features that will enable extremely high-volume and high-performance batch jobs through optimization and partitioning techniques. Simple as well as complex, high-volume batch jobs can leverage the framework in a highly scalable manner to process significant volumes of information.
Features:
- Transaction Management.
- Chunk based processing.
- Declarative I/O.
- Start /stop/restart/retry.
I do not want to deep into the details of Spring Batch, you can find all information about it here, but in this part, we try to solve the card issuer problem by Spring Batch for using it in the next parts of the article.
Before we start, let's review again the problem and architecture, we have a have big file contains names and we want to issue a card for such names, regularly the first step is storing in the database and after revising (e.g., removing duplicate names, or eliminating null records) Spring Boot comes into operation, reads data from the database, processes that data, and issues a card.
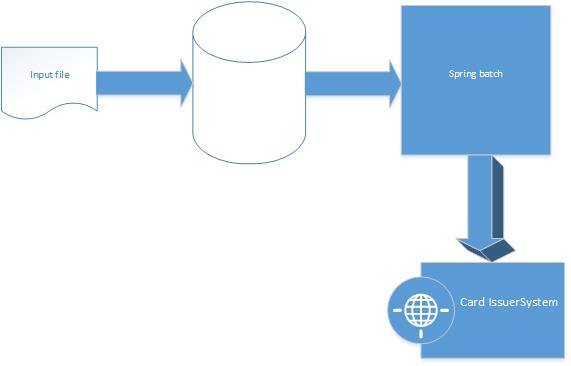
Ok, first of all, you should create a new Spring Boot project with the following Maven dependency:
x
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tosan</groupId>
<artifactId>Tosan-Flowable</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.hsqldb</groupId>
<artifactId>hsqldb</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
Like every Spring Boot-based project, you need an application class, don't forget:
xxxxxxxxxx
In your application class:
xxxxxxxxxx
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
public class SpringBatchApplication
{
public static void main(String[] args)
{
SpringApplication.run(SpringBatchApplication.class, args);
}
}
Obviously, the CardHolder class needed for the base entity.
x
import java.io.Serializable;
public class CardHolder implements Serializable {
private String expireDate;
private String cardHolderName;
public String getExpireDate() {
return expireDate;
}
public int hashCode() {
return super.hashCode();
}
public boolean equals(Object obj) {
return super.equals(obj);
}
public void setExpireDate(String expireDate) {
this.expireDate = expireDate;
}
public String getCardHolderName() {
return cardHolderName;
}
public void setCardHolderName(String cardHolderName) {
this.cardHolderName = cardHolderName;
}
public String toString() {
return "Card issued with expired date [ "+expireDate+" ] and name ["+ cardHolderName +"]";
}
The data entry point of our batch systems is the reader, so here is a code of CardHolderItemReader:
x
import org.springframework.batch.item.ItemReader;
import org.springframework.beans.factory.annotation.Autowired;
import java.io.FileNotFoundException;
import java.util.List;
public class CardHolderItemReader implements ItemReader<CardHolder> {
private List<CardHolder> customerList;
static int idx=0;
CardHoldersRepository cardHoldersRepository;
public CardHolderItemReader() {
customerList=cardHoldersRepository.getCardHolders();
}
public CardHolder read() throws Exception {
CardHolder c= customerList.get(idx);
idx++;
if(idx==customerList.size())
return null ;
return c;
}
private List<CardHolder> customers() throws FileNotFoundException {
return this.customerList;
}
The main part: The processor that processes the CardHolder item list and issues cards!
xxxxxxxxxx
import org.springframework.batch.item.validator.ValidatingItemProcessor;
public class CardIssueProcessor extends ValidatingItemProcessor<CardHolder> {
public CardIssueProcessor() {
super(
item -> {
if(item!=null) {
//connect to card issuer service and issue card
System.out.println("card Issued for " + item.getCardHolderName());
}
}
);
setFilter(true);
}
}
Batch config class: besides all Spring Batch-related code we have a scheduled method named 'run' that fires jobs every 500 milliseconds.
x
package com.config;
import org.springframework.batch.core.*;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.support.CompositeItemProcessor;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.Scheduled;
import java.util.Arrays;
public class CardReportJobConfig {
private JobBuilderFactory jobBuilders;
private StepBuilderFactory stepBuilders;
JobLauncher jobLauncher;
public Job customerReportJob() {
return jobBuilders.get("customerReportJob")
.start(taskletStep())
.next(chunkStep())
.build();
}
public Step taskletStep() {
return stepBuilders.get("taskletStep")
.tasklet(Tasklettasklet())
.build();
}
public Tasklet Tasklettasklet() {
return new Tasklet() {
public RepeatStatus execute(StepContribution stepContribution, ChunkContext chunkContext) throws Exception {
return RepeatStatus.FINISHED;
}
};
}
public Step chunkStep() {
return stepBuilders.get("chunkStep")
.<CardHolder, CardHolder>chunk(20)
.reader(reader())
.processor(processor())
.writer(writer())
.build();
}
public ItemReader<CardHolder> reader() {
return new CardHolderItemReader();
}
public ItemProcessor<CardHolder, CardHolder> processor() {
final CompositeItemProcessor<CardHolder, CardHolder> processor = new CompositeItemProcessor<>();
processor.setDelegates(Arrays.asList(new CardIssueProcessor()));
return processor;
}
public ItemWriter<CardHolder> writer() {
return new CardHolderItemWriter();
}
(fixedRate = 500)
public void run() throws Exception {
JobExecution execution = jobLauncher.run(
customerReportJob(),
new JobParametersBuilder().toJobParameters()
);
}
}
Here is a writer class that stores the log and result of operation into the file named 'output.txt.'
x
import org.springframework.batch.item.ItemWriter;
import javax.annotation.PreDestroy;
import java.io.*;
import java.util.List;
public class CardHolderItemWriter implements ItemWriter<CardHolder>, Closeable {
private final PrintWriter writer;
public CardHolderItemWriter() {
OutputStream out;
try {
out = new FileOutputStream("output.txt");
} catch (FileNotFoundException e) {
out = System.out;
}
this.writer = new PrintWriter(out);
}
public void write(final List<? extends CardHolder> items) throws Exception {
for (CardHolder item : items) {
writer.println(item.toString());
}
}
public void close() throws IOException {
writer.close();
}
}

But there is an important problem we need to write the file into the database before starting the batch, it is possible to handle them in memory but it is not a good idea for such huge files.
Integration Spark and Spring Batch
The main problem of using a database as a storage of files before the batch operation is performance because you need to write millions of records into the database and read from it, sometimes revise these records. So what is the solution? The answer is Spark. Spark can replace the database in the starting point of batches:
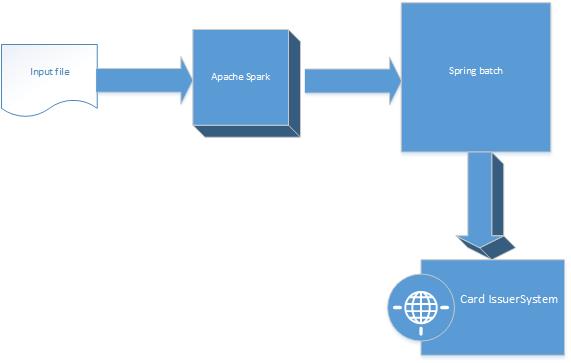
In the previous article, I had a full explanation of spark. In this part, we want to integrate it with Spring Batch. The first step is the creation of SparkDataFactory that connects to spark and reads data from the file and returns the list of CardHolders:
xxxxxxxxxx
import java.util.List;
public class SparkDataFactory {
private static final String CSV_URL="HolderNames.csv";
private static volatile SparkDataFactory me;
private SparkDataFactory(){
}
public static SparkDataFactory getInstance(){
if(me==null)
synchronized (SparkDataFactory.class) {
me = new SparkDataFactory();
}
return me;
}
public List<CardHolder> readData() {
SparkSession spark =SparkSession.builder().master("local[*]").getOrCreate();
JavaRDD<CardHolder> peopleRDD = spark.read()
.textFile(CSV_URL)
.javaRDD()
.map(line -> {
String[] parts = line.split(",");
CardHolder holder = new CardHolder();
holder.setCardHolderName(parts[0]);
holder.setExpireDate(parts[1]);
return holder;
});
return peopleRDD.collect();
}
}
The next step is replacing SpringDataRepository with a Spark reader for reading data.
Remember that you can decide to read the data in your desired size, for example, you can decide to read data in the list with size 100, and each time you read 100 record:
import org.springframework.batch.item.ItemReader;
import org.springframework.beans.factory.annotation.Autowired;
import java.io.FileNotFoundException;
import java.util.List;
public class CardHolderItemReader implements ItemReader<CardHolder> {
private List<CardHolder> customerList;
static int idx=0;
CardHoldersRepository cardHoldersRepository;
public CardHolderItemReader() {
customerList=SparkDataFactory.getInstance().readData();
}
@Override
public CardHolder read() throws Exception {
CardHolder c= customerList.get(idx);
idx++;
if(idx==customerList.size())
return null ;
return c;
}
private List<CardHolder> customers() throws FileNotFoundException {
return this.customerList;
}
}
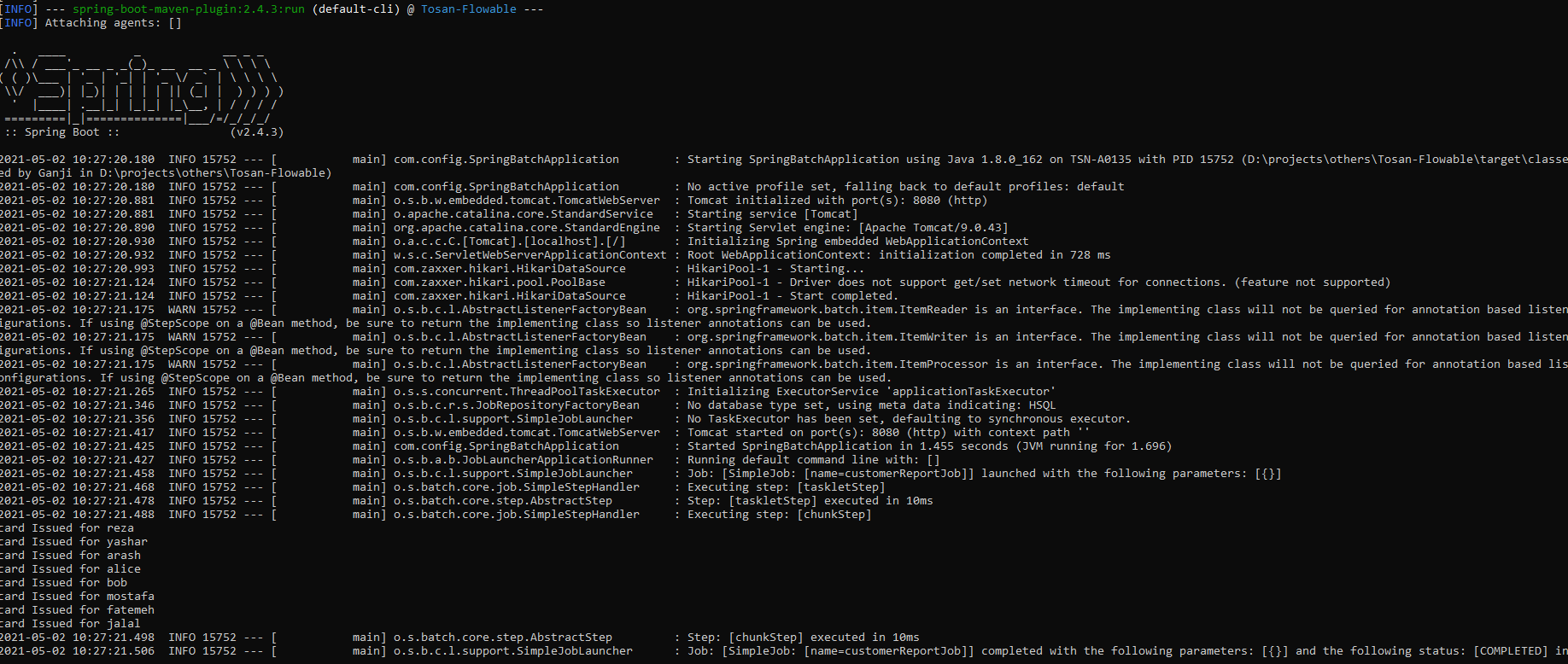
The execution result is:
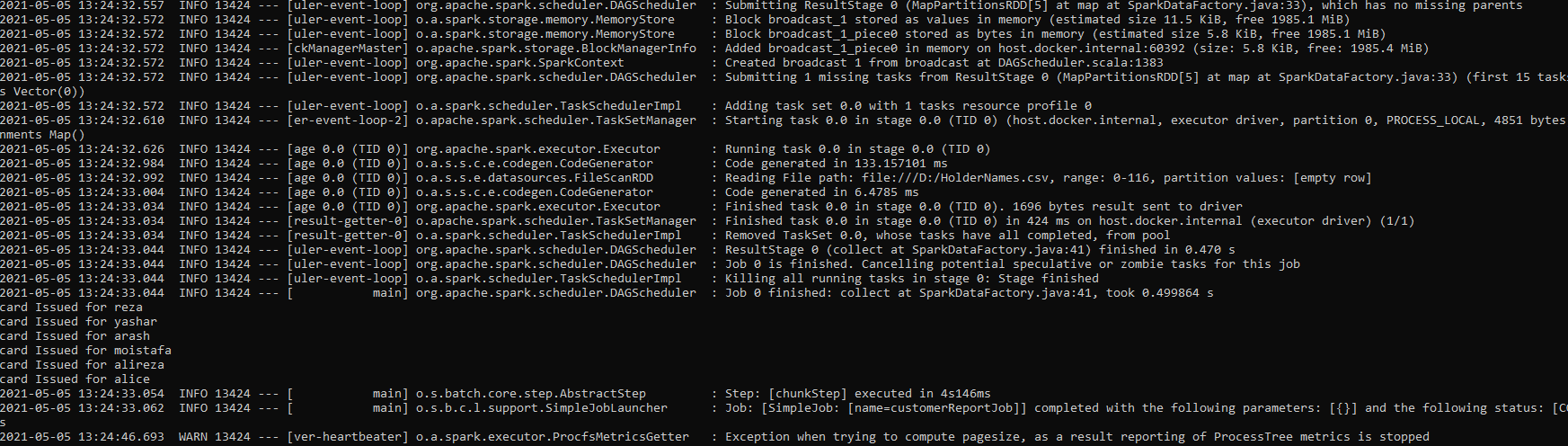
OK, we did it! In the simple non-functional test, I measured the performance in the two cases, database-based approach and Spark-based approach, test results show that there is about a 60x improvement in batch execution time for 2 million records when we used Spark.
What Is Next: Clouds
You can use Spring Data flow as a part of Spring Cloud to build your batch application in the cloud infrastructure, Spring Cloud Data Flow provides tools to create complex typologies for batch data, you can find more information about it here; it will be interesting. Enjoy it!
Opinions expressed by DZone contributors are their own.
Comments