Using Generative AI and ML Models for Email and Mobile Subject Line Optimization
Using Generative AI and ML models in tandem to automatically create compelling subject lines and titles tailored to tone and audience for maximum engagement.
Join the DZone community and get the full member experience.
Join For FreeThe subject lines and titles of emails and push notifications play an important role in determining engagement rates. Digital communication requires the skill of crafting compelling subject lines and concise push notification titles that capture user attention. Marketers craft subject lines based on the tone of the message to be delivered and the intended target audience. By effectively “teaching” this skill and optimizing it for digital communication, generative AI models offer an exciting avenue for automating this process. The article discusses some approaches to creating effective subject lines and push notification messages while combining them with classical machine learning models to predict open rates with Generative AI (Large Language Models).
Methodology
It’s not just about creating catchy subject lines that today’s LLMs can easily generate with the right prompt. The goal is to generate an ideal candidate for the context and content that will entice the recipient to click and view the message. Machine learning (ML) models, specifically random forest algorithms, can predict a recipient’s likelihood of clicking a message with high confidence if they are trained appropriately. By combining LLMs with predictive ML models, it is possible to go generate high-quality subject lines and push notification titles. Below are a few possible ways.
Approach 1: Train the predictive ML model by extracting key features of subject lines such as length, language complexity, sentiment, and their corresponding open rates (labels) from training data. Generate multiple candidate subject lines using a LLM. The ML model can predict the open rate for each candidate subject line by extracting key features and passing them as input. Choose the subject line with the highest predicted open rate.
Approach 2: Similar to the previous approach, the model is trained on raw messages from the dataset and corresponding open rate labels instead of preprocessing the dataset to extract key features. Use this trained model to generate predicted open rates for the subject line generated by the LLM. Pick the subject line with the highest predicted open rate.
Approach 3: This approach extends Approach 1. Besides being trained on key features, the LLM is also fine-tuned to generate subject lines based on email content, open rates, tone (like urgency, positivity, etc.), and target audience persona (like demographics). The fine-tuned LLM generates multiple candidate subject lines, and the predictive ML model trained on subject line features picks the most effective from the candidates
The core idea is to leverage both the linguistic capabilities of the LLM and the predictive power of a traditional ML model by using them together. The LLM generates candidates, which are then scored by the ML model.
Let’s expand on Approach 3.
Training Phase
Collect Data To Train the Model
The first step is to gather samples of emails and mobile push notifications. Along with message content, subject line, channel, and open rate, training data should also include tone and audience labels. In the dataset, label each entry as follows: content, subject line, mobile push title, channel type, open/click rate, tone, and audience segment. In messaging, a ‘channel’ type refers to a medium through which a message or content is delivered. The optimal subject line length and style differ between channels like email and mobile push notifications.
#Sample Training Data Content: New product announcement! Subject: Announcing our new XYZ product! Tone: Exciting Audience: Tech enthusiasts Channel: Email Open rate: 0.25 Content: Black Friday deals are here! Title: Black Friday Deals! Tone: Urgent Audience: Bargain hunters Channel: Mobile Click rate: 0.15
Make sure to provide sufficient training data with open/click rate labels.
Fine-Tune the Large Language Model (LLM)
Fine-tune the LLM model based on the samples that have been collected. This teaches it to generate subject lines or titles based on the channel. It is also important to specify the tone and audience segment in addition to the channel. This conditions text generation not only on the channel but also on the tone of the message and the intended recipients of the message. To fine-tune the model, for example, create a JSON file for the dataset if using OpenAI’s GPT. This file can then be used to fine-tune an OpenAI model using the OpenAI CLI tool’s fine_tunes.create command.
JSON{"prompt": "Content: New product announcement! Tone: Exciting Audience: Tech enthusiasts Channel: Email", "rate": "Open rate: 0.25", "completion": "Subject: Announcing our new XYZ product!"} {"prompt": "Content: Black Friday deals are here! Tone: Urgent Audience: Bargain hunters Channel: Mobile", "rate": "Click rate: 0.15", "completion": "Title: Black Friday Deals!"}
Train the Predictor ML Model
Following the fine-tuning of the LLM model, an ML model needs to be trained to score and select the most effective subject lines. This can be accomplished using a variety of prediction models. The Random Forest algorithm can be used to predict which subject lines will have the highest open rate. Subject lines from the training dataset will have to be extracted for key features. The vectors from these key features can be utilized to train the Random Forest model.
from sklearn.ensemble import RandomForestRegressor
#Train Model
model = RandomForestRegressor()
model.fit(X, y)
# Where X contains the key feature vectors and y contains the open rate label for each corresponding subject line
# For example;
# X = [
# [12, 0.6, 4], # Subject 1
# [8, -0.2, 1], # Subject 2
# [10, 0.1, 2] # Subject 3
# ]
# Example open rate labels
# y = [0.02, 0.05, 0.10]Extract Key Feature Vectors
To extract key features, there are several open-source libraries that can be used. For sentiment extraction, TextBlob’s built-in sentiment method and VADER (Valence Aware Dictionary and Sentiment Reasoner) can be useful. TextStat can be used to determine reading ease, Flesch-Kincaid grade level, and other readability metrics. RAKE (Rapid Automatic Keyword Extraction) can extract keywords.
from textblob import TextBlob
import rake
import nltk
def get_features_of_subject_line(text):
# Length of Subject Line
length = len(text)
# Sentiment
sentiment = TextBlob(text).sentiment.polarity
# Keyword matches
keywords_to_match = ["sale", "new", "hot", "free"]
matches = 0
rake_extractor = rake.Rake()
keywords = rake_extractor.extract_keywords_from_text(text)
for kw in keywords:
if kw in keywords_to_match:
matches += 1
# Readability
readability = nltk.textstat.flesch_reading_ease(text)
return [length, sentiment, matches, readability]
For email, extract features like length, sentiment, keyword matches, and readability. Mobile features include character length, tone, emojis, and segmentation. The key difference is extracting channel-specific features to account for stylistic differences between email and mobile. The model learns to weigh features appropriately for each channel. This allows for optimizing subject line generation and selection to each channel’s constraints and audience expectations.
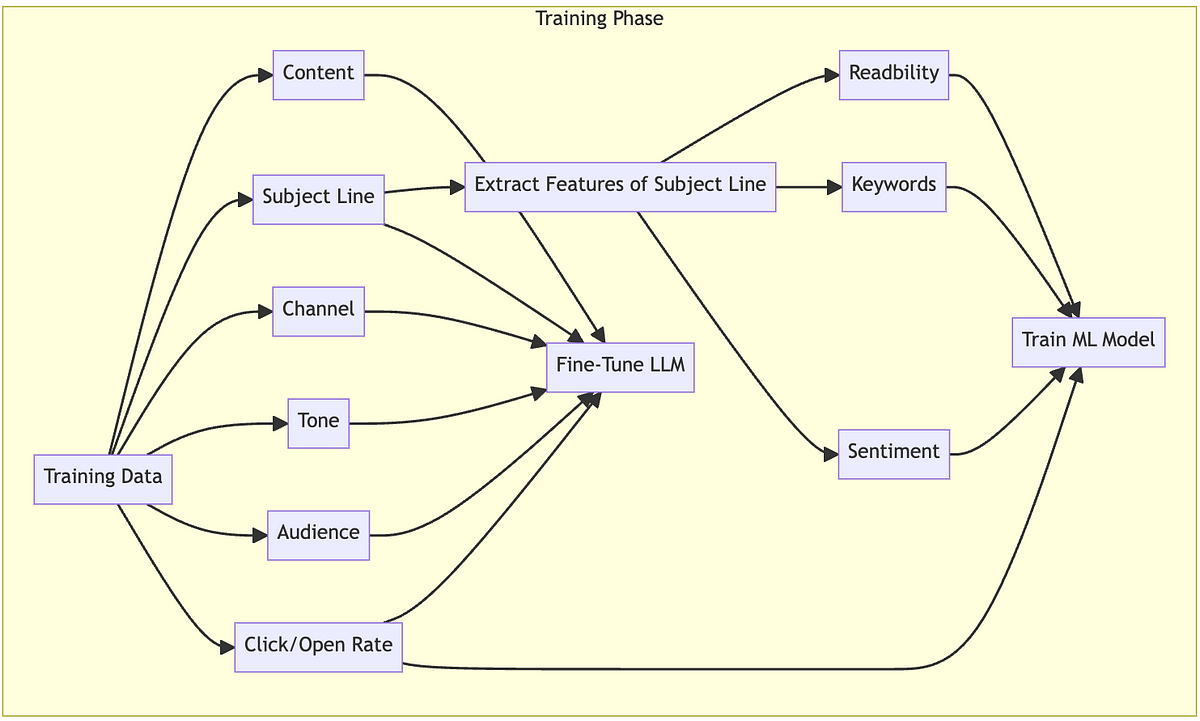 Flow diagram illustrating the training steps (Image By Author)
Flow diagram illustrating the training steps (Image By Author)
Prediction Phase
Generate Subject Line Candidates
To generate subject line candidates for a new message, input the message content, channel, desired tone, and target audience segment into the fine-tuned LLM model. Specify the number of desired candidates in the prompt. The model will generate the requested number of candidates using language appropriate for the channel, in the specified tone, and tailored to the target audience.
Use Trained Predictor Model To Choose the Best Candidate
The previously trained predictor model can now be used to select the most optimal subject line from the candidates generated by the LLM. For each candidate, key features are extracted and input into the model to generate predictions. The subject line with the highest predicted score is chosen as the best option, having the highest probability of enticing the target audience to click and open the message.
# Subject lines generated by the LLM
candidates = ["Holiday Sale!", "Black Friday Deals", "Cyber Monday Blowout"]
# Extract features from each candidate
features = []
for text in candidates:
feats = get_features(text)
features.append(feats)
# Make predictions on candidate features
predictions = model.predict(features)
# Pick subject line with best prediction
best_index = np.argmax(predictions)
best_subject = candidates[best_index]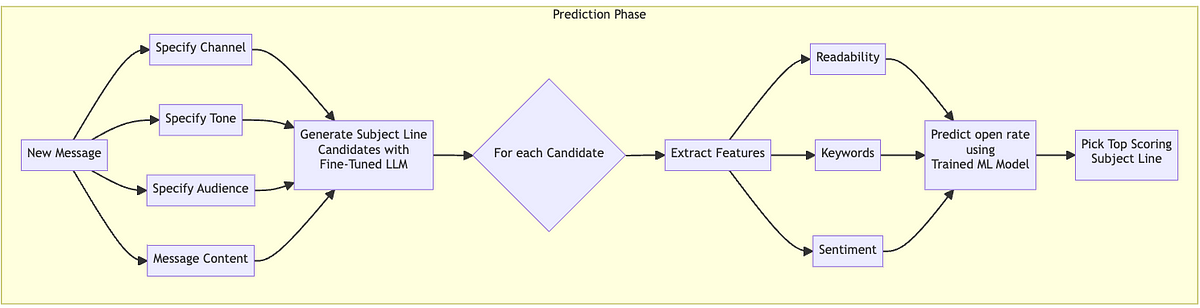 Flow diagram illustrating the prediction steps (Image By Author)
Flow diagram illustrating the prediction steps (Image By Author)
Steps Towards Productization
If serious consideration is being paid to commercializing this approach into a product, there are a few areas to explore in order to enhance the user experience. Providing detailed insights into what could improve or decrease the effectiveness of subject lines and notification titles would be especially useful for marketers as they edit/customize the subject lines and titles generated by the above approach.
Text length: Suggestions for shortening text that exceeds the optimal length for each audience.
Keyword impact: Highlighting keywords that impact engagement rates and suggesting the elimination of negative keywords while encouraging the addition of positive keywords.
Keyword Use and Frequency: Providing insights on how to avoid audience fatigue by using keywords at the right frequency.
Historical Success Cases: Based on past successes, provide similar texts that have been highly engaging in the past.
Industry benchmarking: The predicted engagement rates can be compared to industry benchmarks and modifications suggested if underperformance is detected.
Testing: A/B test the top candidates and iterate based on performance.
Training Loop: Continuously retrain the model on new data for improving predictions.
Personalization: Personalize subject lines for individual subscribers based on their engagement to past messages.
The Human in the Loop: Balancing AI and Human Intervention
As AI is integrated into marketing strategies, having human involvement is important. Marketers should be able to review and edit the subject lines or notification titles created by the models before deployment. Besides ensuring the quality and appropriateness of the communication, this also enables the incorporation of creative input that the model might not have been able to do.
Furthermore, having a feedback loop mechanism paves the way for continuous improvement and learning. The engagement data collected post-deployment provides valuable insights, which are then fed back into the model for further refinement. Anonymizing the post-deployment data before it is used for further refinement is crucial to ensure compliance with data privacy laws.
As a final step, to improve the accuracy of the output of the LLMs and other models, building guardrails and grounding techniques can assist marketers in remaining legally, ethically, and brand-compliant. This also enhances trust and maintains the personal connection at the heart of all communication, even when driven by AI.
Conclusion
A combination of Generative AI and traditional Machine Learning models can be leveraged to create compelling subject lines and notification titles. Generative AI can be fine-tuned to create subject lines based on tone and audience. Predictive models like Random Forest can be utilized to pick the most effective subject line and title for maximum engagement.
Opinions expressed by DZone contributors are their own.
Comments