Using Read-Through and Write-Through in Distributed Cache
Read this article in order to learn more about how to use read-through and write-through in distributed cache.
Join the DZone community and get the full member experience.
Join For Free

with the explosion of extremely high transaction web apps, soa, grid computing, and other server applications, data storage is unable to keep up. the reason is data storage cannot keep adding more servers to scale out, unlike application architectures that are extremely scalable.
in these situations, in-memory distributed cache offers an excellent solution to data storage bottlenecks. it spans multiple servers (called a cluster) to pool their memory together and keep all cache synchronized across servers, and it can keep growing this cache cluster endlessly, just like the application servers. this reduces pressure on data storage so that it is no longer a scalability bottleneck.
there are two main ways people use a distributed cache:
- cache-aside: this is where application is responsible for reading and writing from the database and the cache doesn't interact with the database at all. the cache is "kept aside" as a faster and more scalable in-memory data store. the application checks the cache before reading anything from the database. and, the application updates the cache after making any updates to the database. this way, the application ensures that the cache is kept synchronized with the database.
- read-through/write-through (rt/wt): this is where the application treats cache as the main data store and reads data from it and writes data to it. the cache is responsible for reading and writing this data to the database, thereby relieving the application of this responsibility.
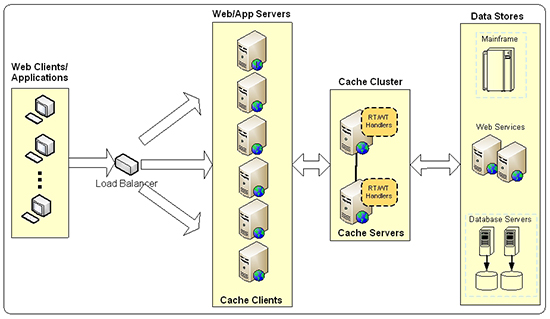
figure 1: read-through/write-through caching architecture.
benefits of read-through & write-through over cache-aside
cache-aside is a very powerful technique and allows you to issue complex database queries involving joins and nested queries and manipulate data any way you want. despite that, read-through/write-through has various advantages over cache-aside as mentioned below:
- simplify application code: in the cache-aside approach, your application code continues to have complexity and direct dependence on the database and even code duplication if multiple applications are dealing with the same data. read-through/write-through moves some of the data access code from your applications to the caching-tier. this dramatically simplifies your applications and abstracts away the database even more clearly.
- better read scalability with read-through: there are many situations where a cache-item expires and multiple parallel user threads end up hitting the database. multiplying this with millions of cached-items and thousands of parallel user requests, the load on the database becomes noticeably higher. but, read-through keeps cache-item in the cache while it is fetching the latest copy of it from the database. it then updates the cache-item. the end result is that the application never goes to the database for these cache-items and the database load is kept to the minimum.
- better write performance with write-behind: in cache-aside, application updates the database directly synchronously. whereas, a write-behind lets your application quickly update the cache and return. then, it lets the cache update the database in the background.
- better database scalability with write-behind: with write-behind, you can specify throttling limits so the database writes are not performed as fast as the cache updates and therefore the pressure on the database is not much. additionally, you can schedule the database writes to occur during off-peak hours, again to minimize pressure.
- auto-refresh cache on expiration: read-through allows the cache to automatically reload an object from the database when it expires. this means that your application does not have to hit the database in peak hours because the latest data is always in the cache.
- auto-refresh cache on database changes: read-through allows the cache to automatically reload an object from the database when its corresponding data changes in the database. this means that the cache is always fresh and your application does not have to hit the database in peak hours because the latest data is always in the cache.
read-through/write-through is not intended to be used for all data access in your application. it is best suited for situations where you're either reading individual rows from the database or reading data that can directly map to an individual cache-item. it is also ideal for reference data that is meant to be kept in the cache for frequent reads even though this data changes periodically.
developing a read-through handler
a read-through handler is registered with the cache server and allows the cache to directly read data from database. the ncache server provides a read-through handler interface that you need to implement. this enables ncache to call your read-through handler.
using system.data.sqlclient;
using alachisoft.web.caching;
...
public class sqlreadthruprovider : ireadthruprovider
{
private sqlconnection _connection;
// called upon startup to initialize connection
public void start(idictionary parameters)
{
_connection = new sqlconnection(parameters["connstring"]);
_connection.open();
}
// called at the end to close connection
public void stop() { _connection.close(); }
// responsible for loading object from external data source
public object load(string key, ref cachedependency dep)
{
string sql = "select * from customers where ";
sql += "customerid = @id";
sqlcommand cmd = new sqlcommand(sql, _connection);
cmd.parameters.add("@id", system.data.sqldbtype.varchar);
// let's extract actual customerid from "key"
int keyformatlen = "customers:customerid:".length;
string custid = key.substring(keyformatlen,
key.length - keyformatlen);
cmd.parameters["@id"].value = custid;
// fetch the row in the table
sqldatareader reader = cmd.executereader();
// copy data from "reader" to "cust" object
customers cust = new customers();
fillcustomers(reader, cust);
// specify a sqlcachedependency for this object
dep = new sqlcachedependency(cmd);
return cust;
}
}start() performs certain resource allocation tasks like estalishing connections to the main datasource, whereas stop() is meant to reset all such allocations. load is what the cache calls to read-through the objects.
developing a write-through handler
write-through handler is invoked, when the cache needs to write to the database as the cache is updated. normally, the application issues an update to the cache through add, insert, or remove.
using system.data.sqlclient;
using alachisoft.web.caching;
...
public class sqlwritethruprovider : iwritethruprovider
{
private sqlconnection _connection;
// called upon startup to initialize connection
public void start(idictionary parameters)
{
_connection = new sqlconnection(parameters["connstring"]);
_connection.open();
}
// called at the end to close connection
public void stop() { _connection.close(); }
// responsible for saving object into external datasource
public bool save (customer val)
{
int rowschanged = 0;
string[] customer = {val.customerid,val.contactname,val.companyname,
val.address,val.city,val.country,val.postalcode,
val.phone,val.fax};
sqlcommand cmd = _connection.createcommand();
cmd.commandtext = string.format(cultureinfo.invariantculture,
"update dbo.customers " + "set ," +
",," +
",," +
",," +
"," +
" where customerid = '{0}'", customer);
rowschanged = cmd.executenonquery();
if (rowschanged > 0)
{
return true;
}
return false;
}
}start() performs resource allocation tasks like estalishing connections to the datasource, whereas stop() is meant to reset all such allocations. save is the method the cache calls to write-through objects.
calling read-through & write-through from application
following sample code shows using the read-through/write-through capabilities of cache from a simple windows application.
using alachisoft.web.caching;
...
internal class mainform : system.windows.forms.form
{
/// fetches record from the cache, which internally accesses the
/// datasource using read-thru provider
private void onclickfind(object sender, system.eventargs e)
{
customer customer;
cache cache = ncache.caches[cachename];
string key = cbocustomerid.text.trim();
string providername = cboreadthruprovider.text;
customer = (customer) cache.get(key,
providername,
dsreadoption.readthru);
...
}
/// updates the record using the cache, which internally accesses
/// the datasource using write-thru provider
private void onclickupdate(object sender, system.eventargs e)
{
cache cache = ncache.caches[cachename];
customer customer = new customer();
...
string key = customer.customerid;
string providername = cbowritethruprovider.text;
cache.insert(key, new cacheitem(customer), dswriteoption.writethru, providername, null);
...
}
}Published at DZone with permission of Iqbal Khan. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments