What is Scalable Machine Learning?
Join the DZone community and get the full member experience.
Join For Freescalability has become one of those core concept slash buzzwords of big data. it’s all about scaling out, web scale, and so on. in principle, the idea is to be able to take one piece of code and then throw any number of computers at it to make it fast.
the terms “scalable” and “large scale” have been used in machine learning circles long before there was big data. there had always been certain problems which lead to a large amount of data, for example in bioinformatics, or when dealing with large number of text documents. so finding learning algorithms, or more generally data analysis algorithms which can deal with a very large set of data was always a relevant question.
interestingly, this issue of scalability were seldom solved using actual scaling in in machine learning, at least not in the big data kind of sense. part of the reason is certainly that multicore processors didn’t yet exist at the scale they do today and that the idea of “just scaling out” wasn’t as pervasive as it is today.
instead, “scalable” machine learning is almost always based on finding more efficient algorithms, and most often, approximations to the original algorithm which can be computed much more efficiently.
to illustrate this, let’s search for nips papers (the annual advances in neural information processing systems, short nips, conference is one of the big ml community meetings) for papers which have the term “scalable” in the title.
here are some examples:
-
scalable inference for logistic-normal topic models
… this paper presents a partially collapsed gibbs sampling algorithm that approaches the provably correct distribution by exploring the ideas of data augmentation …
partially collapsed gibbs sampling is a kind of estimation algorithm for certain graphical models.
-
a scalable approach to probabilistic latent space inference of large-scale networks
… with […] an efficient stochastic variational inference algorithm, we are able to analyze real networks with over a million vertices […] on a single machine in a matter of hours …
stochastic variational inference algorithm is both an approximation and an estimation algorithm.
-
scalable kernels for graphs with continuous attributes
… in this paper, we present a class of path kernels with computational complexity $o(n^2(m + \delta^2 ))$ …
and this algorithm has squared runtime in the number of data points, so wouldn’t even scale out well even if you could.
usually, even if there is potential for scalability, it usually something that is “embarassingly parallel” (yep, that’s a technical term), meaning that it’s something like a summation which can be parallelized very easily. still, the actual “scalability” comes from the algorithmic side.
so how do scalable ml algorithms look like? a typical example are the stochastic gradient descent (sgd) class of algorithms. these algorithms can be used, for example, to train classifiers like linear svms or logistic regression. one data point is considered at each iteration. the prediction error on that point is computed and then the gradient is taken with respect to the model parameters, giving information about how to adapt these parameters slightly to make the error smaller.
vowpal wabbit is one program based on this approach and it has a nice definition of what it considers to mean scalable in machine learning:
there are two ways to have a fast learning algorithm: (a) start with a slow algorithm and speed it up, or (b) build an intrinsically fast learning algorithm. this project is about approach (b), and it’s reached a state where it may be useful to others as a platform for research and experimentation.
so “scalable” means having a learning algorithm which can deal with any amount of data, without consuming ever growing amounts of resources like memory. for sgd type algorithms this is the case, because all you need to store are the model parameters, usually a few ten to hundred thousand double precision floating point value, so maybe a few megabytes in total. the main problem to speed this kind of computation up is how to stream the data by fast enough.
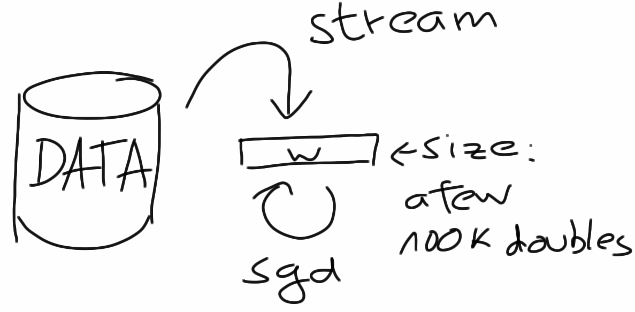
to put it differently, not only does this kind of scalability not rely on scaling out, it’s actually not even necessary or possible to scale the computation out because the main state of the computation easily fits into main memory and computations on it cannot be distributed easily.
i know that gradient descent is often taken as an example for map reduce and other approaches like in this paper on the architecture of spark , but that paper discusses a version of gradient descent where you are not taking one point at a time, but aggregate the gradient information for the whole data set before making the update to the model parameters. while this can be easily parallelized, it does not perform well in practice because the gradient information tends to average out when computed over the whole data set.
if you want to know more, this large scale learning challenge sören sonnneburg organized in 2008 still has valuable information on how to deal with massive data sets.
of course, there are things which can be easily scaled well using hadoop or spark, in particular any kind of data preprocessing or feature extraction where you need to apply the same operation to each data point in your data set. another area where parallelization is easy and useful is when you are using cross validation to do model selection where you usually have to train a large number of models for different parameter sets to find the combination which performs best. again, even here there is more potential for even speeding up such computations using better algorithms like in this paper of mine .
i’ve just scratched the surface of this, but i hope you got the idea that scalability can mean quite different things. in big data (meaning the infrastructure side of it) what you want to compute is pretty well defined, for example some kind of aggregate over your data set, so you’re left with the question of how to parallelize that computation well. in machine learning, you have much more freedom because data is noisy and there’s always some freedom in how you model your data, so you can often get away with computing some variation of what you originally wanted to do and still perform well. often, this allows you to speed up your computations significantly by decoupling computations. parallelization is important, too, but alone it won’t get you very far.
luckily, there are projects like spark and stratosphere/flink which work on providing more useful abstractions beyond map and reduce to make the last part easier for data scientists, but you won’t get rid of the algorithmic design part any time soon.
Published at DZone with permission of Mikio Braun. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments