What's New With Jakarta NoSQL? (Part 1): Intro to Document With MongoDB
This post will talk about the newest milestone version of this new specification and more.
Join the DZone community and get the full member experience.
Join For Free
Jakarta EE picks up where Java EE 8 left off, but the roadmap going forward will be focused on modern innovations like microservices, modularity, and NoSQL databases. This post will talk about the newest milestone version of this new specification and the subsequent actions to make the Jakarta EE community even greater in the cloud.
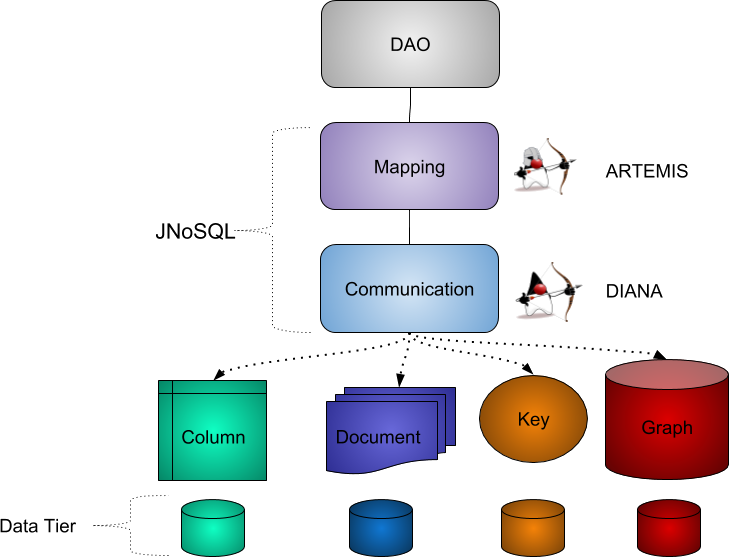
Why Jakarta NoSQL?
Vendor lock-in is one of the things any Java developer needs to consider when choosing NoSQL databases. If there’s a need for a switch, other considerations include time spent on the change, the learning curve of a new API to use with this database, the code that will be lost, the persistence layer that needs to be replaced. Jakarta NoSQL avoids most of these issues through Communication APIs. Jakarta NoSQL also has template classes that apply the design pattern ‘template method’ to database operations. And the Repository interface allows Java developers to create and extend interfaces, with implementation automatically provided by Jakarta NoSQL — support method queries built by developers will automatically be implemented for them.
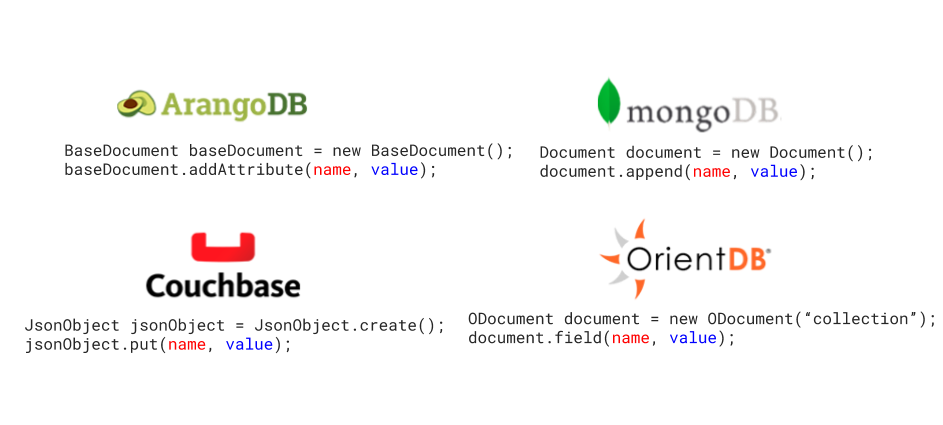
To make it clear, let’s create some sample code. The picture below shows four different databases:
- ArangoDB
- MongoDB
- Couchbase
- OrientDB
What do Those Databases Have in Common?
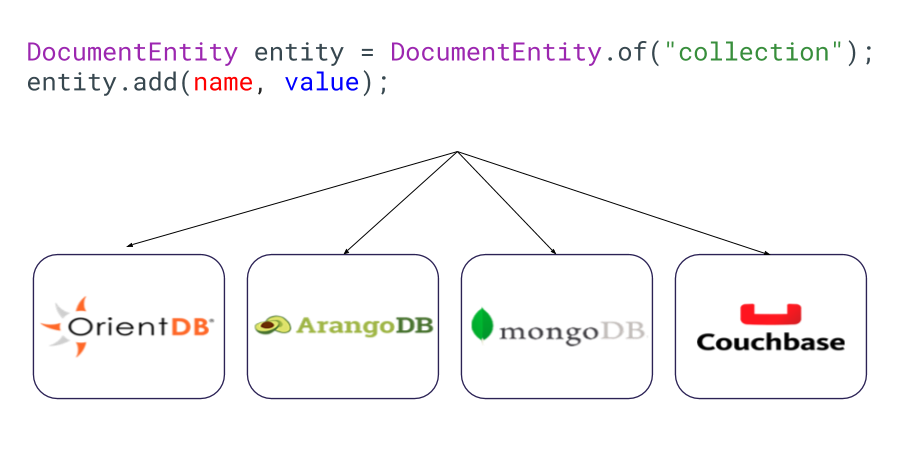
Yup, they’re all document NoSQL databases, and they’re trying to create a document, a tuple with a name, and the information itself. They’re all doing the exact same thing with the same behavior goal, however, with a different class, method name, and so on. So, if you want to move your code from one database to another, you need to learn a new API and update the whole database code to the database API code target.
Through the communication specification, we can easily change between databases just by using the driver databases that look like JDBC drivers. So, you can be more comfortable learning a new NoSQL database from the software architecture perspective; we can easily and quickly jump to another NoSQL.
Show me the code API
To demonstrate how the Jakarta NoSQL works, let’s create a small REST API; that API will run in cloud with Platform.sh. The API will handle the heroes, and all the information will be stored into MongoDB. As a first step, we need to set the dependencies Jakarta NoSQL needs:
- Jakarta Context Dependency Injection 2.0. Jakarta Contexts Dependency Injection specifies a means for obtaining objects that maximize reusability, testability, and maintainability—compared to traditional approaches such as constructors, factories, and service locators. Think of it as a glue for the entire Jakarta EE world.
- Jakarta JSON Binding. Defines a binding framework for converting Java objects to and from JSON documents.
- Jakarta Bean Validation 2.0 (optional). Jakarta Bean Validation defines a metadata model and API for JavaBean and method validation.
- Eclipse MicroProfile Configuration (optional). Eclipse MicroProfile Config is a solution to externalize configuration from Java applications.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.soujava</groupId>
<artifactId>heroes</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>war</packaging>
<name>heroes-demo</name>
<url>https://soujava.org.br/</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<failOnMissingWebXml>false</failOnMissingWebXml>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<version.microprofile>2.2</version.microprofile>
<version.payara.micro>5.193.1</version.payara.micro>
<payara.version>1.0.5</payara.version>
<platform.sh.version>2.2.3</platform.sh.version>
<jakarta.nosql.version>1.0.0-b1</jakarta.nosql.version>
</properties>
<dependencies>
<dependency>
<groupId>jakarta.platform</groupId>
<artifactId>jakarta.jakartaee-web-api</artifactId>
<version>8.0.0</version>
</dependency>
<dependency>
<groupId>org.eclipse.microprofile.config</groupId>
<artifactId>microprofile-config-api</artifactId>
<version>1.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.eclipse.jnosql.artemis</groupId>
<artifactId>artemis-document</artifactId>
<version>${jakarta.nosql.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jnosql.diana</groupId>
<artifactId>mongodb-driver</artifactId>
<version>${jakarta.nosql.version}</version>
</dependency>
</dependencies>
<build>
<finalName>heros</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-war-plugin</artifactId>
<version>3.2.2</version>
<configuration>
<failOnMissingWebXml>false</failOnMissingWebXml>
<packagingExcludes>pom.xml</packagingExcludes>
</configuration>
</plugin>
<plugin>
<groupId>fish.payara.maven.plugins</groupId>
<artifactId>payara-micro-maven-plugin</artifactId>
<version>${payara.version}</version>
<configuration>
<payaraVersion>${version.payara.micro}</payaraVersion>
<autoDeployEmptyContextRoot>true</autoDeployEmptyContextRoot>
</configuration>
</plugin>
</plugins>
</build>
</project>
One amazing aspect of using Platform.sh is that we don’t need to worry about the infrastructure installation that includes the MongoDB server itself; it will create several containers that include the application and the database. We’ll talk more about Platform.sh and its relationship with cloud-native soon.
The first step is to create the Hero entity, in the annotations package now as jakarta.nosql.mapping.
xxxxxxxxxx
import jakarta.nosql.mapping.Column;
import jakarta.nosql.mapping.Entity;
import jakarta.nosql.mapping.Id;
import javax.json.bind.annotation.JsonbVisibility;
import java.io.Serializable;
import java.util.Objects;
import java.util.Set;
(FieldPropertyVisibilityStrategy.class)
public class Hero implements Serializable {
private String name;
private Integer age;
private Set<String> powers;
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (!(o instanceof Hero)) {
return false;
}
Hero hero = (Hero) o;
return Objects.equals(name, hero.name);
}
public int hashCode() {
return Objects.hashCode(name);
}
public String toString() {
return "Hero{" +
"name='" + name + '\'' +
", age=" + age +
", powers=" + powers +
'}';
}
}
import javax.json.bind.config.PropertyVisibilityStrategy;
import java.lang.reflect.Field;
import java.lang.reflect.Method;
public class FieldPropertyVisibilityStrategy implements PropertyVisibilityStrategy {
public boolean isVisible(Field field) {
return true;
}
public boolean isVisible(Method method) {
return true;
}
}
The next step is to create a connection to the NoSQL database, so we’ll create a DocumentCollectionManager instance. Think of EntityManager as a Document database. We know that hard-coded information isn’t safe nor is it a t good practice. That’s why the twelve-factor mentions it in the third section. Further, the application doesn’t need to know where this information comes from. To follow the good practices of the twelve-factor and to support the cloud-native principle, Jakarta NoSQL has support for the Eclipse MicroProfile Configuration.
xxxxxxxxxx
import jakarta.nosql.document.DocumentCollectionManager;
import org.eclipse.microprofile.config.inject.ConfigProperty;
import javax.enterprise.context.ApplicationScoped;
import javax.enterprise.inject.Disposes;
import javax.enterprise.inject.Produces;
import javax.inject.Inject;
class DocumentManagerProducer {
(name = "document")
private DocumentCollectionManager manager;
public DocumentCollectionManager getManager() {
return manager;
}
public void destroy( DocumentCollectionManager manager) {
manager.close();
}
}
Once this is done, we create a connection class that makes a DocumentCollectionManager instance available to CDI, thanks to the method annotated with Produces.
The database configuration is ready to run locally. For this application beyond the CRUD, let’s create three more queries:
- Find all Heroes
- Find Heroes older than a certain age
- Find heroes younger than a certain age
- Find Heroes by the name, the id
- Find Heroes by the power
We have several ways to create this query into Jakarta NoSQL. Let’s introduce the first way with DocumentTemplate. The template classes execute operations into NoSQL database in the Mapper layer, so there’s a template class for each NoSQL type that Jakarta NoSQL supports: DocumentTemplate for document, KeyValueTemplate for key-value database, and so on.
Even with Document Template, we have two paths to consult information into NoSQL databases. The first one is programmatically. The API has a fluent way to create a DocumentQuery instance.
x
import jakarta.nosql.document.DocumentDeleteQuery;
import jakarta.nosql.document.DocumentQuery;
import jakarta.nosql.mapping.document.DocumentTemplate;
import com.google.common.collect.Sets;
import javax.enterprise.context.ApplicationScoped;
import javax.inject.Inject;
import java.util.Optional;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import static jakarta.nosql.document.DocumentDeleteQuery.delete;
import static jakarta.nosql.document.DocumentQuery.select;
import static java.util.Arrays.asList;
public class FluentAPIService {
private DocumentTemplate template;
public void execute() {
Hero iron = new Hero("Iron man", 32, Sets.newHashSet("Rich"));
Hero thor = new Hero("Thor", 5000, Sets.newHashSet("Force", "Thunder", "Strength"));
Hero captainAmerica = new Hero("Captain America", 80, Sets.newHashSet("agility",
"Strength", "speed", "endurance"));
Hero spider = new Hero("Spider", 18, Sets.newHashSet("Spider", "Strength"));
DocumentDeleteQuery deleteQuery = delete().from("Hero")
.where("_id").in(Stream.of(iron, thor, captainAmerica, spider)
.map(Hero::getName).collect(Collectors.toList())).build();
template.delete(deleteQuery);
template.insert(asList(iron, thor, captainAmerica, spider));
//find by id
Optional<Hero> hero = template.find(Hero.class, iron.getName());
System.out.println(hero);
//query younger
DocumentQuery youngQuery = select().from("Hero")
.where("age").lt(20).build();
//query seniors
DocumentQuery seniorQuery = select().from("Hero")
.where("age").gt(20).build();
//query powers
DocumentQuery queryPower = select().from("Hero")
.where("powers").in(Collections.singletonList("Strength"))
.build();
Stream<Hero> youngStream = template.select(youngQuery);
Stream<Hero> seniorStream = template.select(seniorQuery);
Stream<Hero> strengthStream = template.select(queryPower);
String yongHeroes = youngStream.map(Hero::getName).collect(Collectors.joining(","));
String seniorsHeroes = seniorStream.map(Hero::getName).collect(Collectors.joining(","));
String strengthHeroes = strengthStream.map(Hero::getName).collect(Collectors.joining(","));
System.out.println("Young result: " + yongHeroes);
System.out.println("Seniors result: " + seniorsHeroes);
System.out.println("Strength result: " + strengthHeroes);
}
}
To talk about the ‘find all heroes’ query, we’ll create a specific class because when we talk about returning all information in a database, we need to avoid an impact on performance. Given a database might have more than one million information points, it doesn’t make sense to bring all this information at the same time (in most cases).
xxxxxxxxxx
import jakarta.nosql.document.DocumentDeleteQuery;
import jakarta.nosql.document.DocumentQuery;
import jakarta.nosql.mapping.document.DocumentTemplate;
import com.google.common.collect.Sets;
import javax.enterprise.context.ApplicationScoped;
import javax.inject.Inject;
import java.util.Arrays;
import java.util.Optional;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import static jakarta.nosql.document.DocumentDeleteQuery.delete;
import static jakarta.nosql.document.DocumentQuery.select;
import static java.util.Arrays.asList;
public class FluentAPIFindAllService {
private DocumentTemplate template;
public void execute() {
Hero iron = new Hero("Iron man", 32, Sets.newHashSet("Rich"));
Hero thor = new Hero("Thor", 5000, Sets.newHashSet("Force", "Thunder"));
Hero captainAmerica = new Hero("Captain America", 80, Sets.newHashSet("agility",
"strength", "speed", "endurance"));
Hero spider = new Hero("Spider", 18, Sets.newHashSet("Spider"));
DocumentDeleteQuery deleteQuery = delete().from("Hero")
.where("_id").in(Stream.of(iron, thor, captainAmerica, spider)
.map(Hero::getName).collect(Collectors.toList())).build();
template.delete(deleteQuery);
template.insert(Arrays.asList(iron, thor, captainAmerica, spider));
DocumentQuery query = select()
.from("Hero")
.build();
Stream<Hero> heroes = template.select(query);
Stream<Hero> peek = heroes.peek(System.out::println);
System.out.println("The peek is not happen yet");
System.out.println("The Heroes names: " + peek.map(Hero::getName)
.collect(Collectors.joining(", ")));
DocumentQuery querySkipLimit = select()
.from("Hero")
.skip(0)
.limit(1)
.build();
Stream<Hero> heroesSkip = template.select(querySkipLimit);
System.out.println("The Heroes names: " + heroesSkip.map(Hero::getName)
.collect(Collectors.joining(", ")));
}
}
Also, the API has the pagination feature that easily accommodates pagination and functions with large sets of data.
xxxxxxxxxx
import jakarta.nosql.document.DocumentDeleteQuery;
import jakarta.nosql.document.DocumentQuery;
import jakarta.nosql.mapping.Page;
import jakarta.nosql.mapping.Pagination;
import jakarta.nosql.mapping.document.DocumentQueryPagination;
import jakarta.nosql.mapping.document.DocumentTemplate;
import com.google.common.collect.Sets;
import javax.enterprise.context.ApplicationScoped;
import javax.inject.Inject;
import java.util.Arrays;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import static jakarta.nosql.document.DocumentDeleteQuery.delete;
import static jakarta.nosql.document.DocumentQuery.select;
public class FluentAPIPaginationService {
private DocumentTemplate template;
public void execute() {
Hero iron = new Hero("Iron man", 32, Sets.newHashSet("Rich"));
Hero thor = new Hero("Thor", 5000, Sets.newHashSet("Force", "Thunder"));
Hero captainAmerica = new Hero("Captain America", 80, Sets.newHashSet("agility",
"strength", "speed", "endurance"));
Hero spider = new Hero("Spider", 18, Sets.newHashSet("Spider"));
DocumentDeleteQuery deleteQuery = delete().from("Hero")
.where("_id").in(Stream.of(iron, thor, captainAmerica, spider)
.map(Hero::getName).collect(Collectors.toList())).build();
template.delete(deleteQuery);
template.insert(Arrays.asList(iron, thor, captainAmerica, spider));
DocumentQuery query = select()
.from("Hero")
.orderBy("_id")
.asc()
.build();
DocumentQueryPagination pagination =
DocumentQueryPagination.of(query, Pagination.page(1).size(1));
Page<Hero> page1 = template.select(pagination);
System.out.println("Page 1: " + page1.getContent().collect(Collectors.toList()));
Page<Hero> page2 = page1.next();
System.out.println("Page 2: " + page2.getContent().collect(Collectors.toList()));
Page<Hero> page3 = page1.next();
System.out.println("Page 3: " + page3.getContent().collect(Collectors.toList()));
}
}
A fluent API is amazing and safe to write and reads queries for a NoSQL database, but how about query by text? While a fluent API is safer, it’s sometimes verbose. You know what, though? Jakarta NoSQL has support to query by text that includes PrepareStatement where, as a Java Developer, you can set the parameter dynamically.
xxxxxxxxxx
import jakarta.nosql.mapping.PreparedStatement;
import jakarta.nosql.mapping.document.DocumentTemplate;
import com.google.common.collect.Sets;
import javax.enterprise.context.ApplicationScoped;
import javax.inject.Inject;
import java.util.Arrays;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class TextService {
private DocumentTemplate template;
public void execute() {
Hero iron = new Hero("Iron man", 32, Sets.newHashSet("Rich"));
Hero thor = new Hero("Thor", 5000, Sets.newHashSet("Force", "Thunder"));
Hero captainAmerica = new Hero("Captain America", 80, Sets.newHashSet("agility",
"strength", "speed", "endurance"));
Hero spider = new Hero("Spider", 18, Sets.newHashSet("Spider"));
template.query("delete from Hero where _id in ('Iron man', 'Thor', 'Captain America', 'Spider')");
template.insert(Arrays.asList(iron, thor, captainAmerica, spider));
//query younger
PreparedStatement prepare = template.prepare("select * from Hero where age < @age");
prepare.bind("age", 20);
Stream<Hero> youngStream = prepare.getResult();
Stream<Hero> seniorStream = template.query("select * from Hero where age > 20");
Stream<Hero> powersStream = template.query("select * from Hero where powers in ('Strength')");
Stream<Hero> allStream = template.query("select * from Hero");
Stream<Hero> skipLimitStream = template.query("select * from Hero skip 0 limit 1 order by _id asc");
String yongHeroes = youngStream.map(Hero::getName).collect(Collectors.joining(","));
String seniorsHeroes = seniorStream.map(Hero::getName).collect(Collectors.joining(","));
String allHeroes = allStream.map(Hero::getName).collect(Collectors.joining(","));
String skipLimitHeroes = skipLimitStream.map(Hero::getName).collect(Collectors.joining(","));
String powersHeroes = powersStream.map(Hero::getName).collect(Collectors.joining(","));
System.out.println("Young result: " + yongHeroes);
System.out.println("Seniors result: " + seniorsHeroes);
System.out.println("Powers Strength result: " + powersHeroes);
System.out.println("All heroes result: " + allHeroes);
System.out.println("All heroes skip result: " + skipLimitHeroes);
}
}
What do you think? Too complex? Don’t worry, we can simplify it for you with a Repository. A repository abstraction is here to significantly reduce the amount of boilerplate code required to implement data access layers for various persistence stores.
xxxxxxxxxx
import jakarta.nosql.mapping.Page;
import jakarta.nosql.mapping.Pagination;
import jakarta.nosql.mapping.Repository;
import java.util.stream.Stream;
public interface HeroRepository extends Repository<Hero, String> {
Stream<Hero> findAll();
Page<Hero> findAll(Pagination pagination);
Stream<Hero> findByPowersIn(String powers);
Stream<Hero> findByAgeGreaterThan(Integer age);
Stream<Hero> findByAgeLessThan(Integer age);
}
import jakarta.nosql.mapping.Page;
import jakarta.nosql.mapping.Pagination;
import com.google.common.collect.Sets;
import javax.enterprise.context.ApplicationScoped;
import javax.inject.Inject;
import java.util.Optional;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import static java.util.Arrays.asList;
public class RepositoryService {
private HeroRepository repository;
public void execute() {
Hero iron = new Hero("Iron man", 32, Sets.newHashSet("Rich"));
Hero thor = new Hero("Thor", 5000, Sets.newHashSet("Force", "Thunder", "Strength"));
Hero captainAmerica = new Hero("Captain America", 80, Sets.newHashSet("agility",
"Strength", "speed", "endurance"));
Hero spider = new Hero("Spider", 18, Sets.newHashSet("Spider", "Strength"));
repository.save(asList(iron, thor, captainAmerica, spider));
//find by id
Optional<Hero> hero = repository.findById(iron.getName());
System.out.println(hero);
Stream<Hero> youngStream = repository.findByAgeLessThan(20);
Stream<Hero> seniorStream = repository.findByAgeGreaterThan(20);
Stream<Hero> strengthStream = repository.findByPowersIn("Strength");
Stream<Hero> allStream = repository.findAll();
String yongHeroes = youngStream.map(Hero::getName).collect(Collectors.joining(","));
String seniorsHeroes = seniorStream.map(Hero::getName).collect(Collectors.joining(","));
String strengthHeroes = strengthStream.map(Hero::getName).collect(Collectors.joining(","));
String allHeroes = allStream.map(Hero::getName).collect(Collectors.joining(","));
System.out.println("Young result: " + yongHeroes);
System.out.println("Seniors result: " + seniorsHeroes);
System.out.println("Strength result: " + strengthHeroes);
System.out.println("All heroes result: " + allHeroes);
//Pagination
Pagination pagination = Pagination.page(1).size(1);
Page<Hero> page1 = repository.findAll(pagination);
System.out.println("Page 1: " + page1.getContent().collect(Collectors.toList()));
Page<Hero> page2 = page1.next();
System.out.println("Page 2: " + page2.getContent().collect(Collectors.toList()));
Page<Hero> page3 = page1.next();
System.out.println("Page 3: " + page3.getContent().collect(Collectors.toList()));
}
}
This concludes the first part of our post, introducing the concept behind Jakarta and NoSQL, and the document API with MongoDB. In part two, we’ll talk about cloud-native, and how to easily move this application to the cloud using Platform.sh. If you’re curious and don’t mind a spoiler, you can take a look at the sample code on your repository.
Further Reading
Published at DZone with permission of Otavio Santana. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments