When DNS Breaks The Internet: Lessons From The Amazon Outage
AWS DNS misconfiguration crashed major services — proving resiliency needs guardrails, chaos-testing, and proactive DNS monitoring.
Join the DZone community and get the full member experience.
Join For FreeHave you ever had an “Oh boy” moment when your favorite application does not load and you assume there is a fault with your Internet connection? In October 2025, this occurred on a global scale — but in point of fact, it was not your Internet connection that failed; it was Amazon’s.
A slight misconfiguration of DNS on behalf of Amazon Web Services (AWS) caused a nationwide catastrophe on the Internet, taking with it such corporate behemoths as Fortnite, Alexa, and, not forgetting, the mobile ordering facility at McDonald’s.
The cause? Not hackers, not system overloads, but just one of those mistakes that any one of us could make with automation — the type that reminds us how fragile even the largest systems are when they can so readily break down.
However, this was not just a piece of human error on the part of Amazon; it was a lesson in resilience-by-design of systems of far greater importance, and a warning against assuming that anything ever “just works.”
Let us analyze what really happened, what made the DNS failures latent, hidden assassins, and — most important of all — what we, as developers, can learn from this incident.
The Heart of the Internet: DNS Explained Simply
Domain Name System (DNS) can be considered the telephone book for the Internet. When you enter google.com, DNS tells your computer which IP address to connect to. Simple enough? Not so easy at scale.
DNS does not merely resolve websites. DNS powers APIs, microservices, databases, authentication, monitoring systems, and virtually everything that needs to connect to something else. When DNS fails, it is akin to a complete collapse of the nervous system — the body may be intact or even healthy, but nothing communicates with anything else.
In AWS’s case, it was a race condition in DNS automation that deleted mission-critical internal DNS records. These records were essential for underlying services such as DynamoDB. Without them, thousands of dependent systems could no longer find one another.
And when systems could not connect, what did they do? They retried. Again, and again.
This led to a retry storm — overwhelming the network and cascading into a worldwide performance slowdown. Every single AWS region — even those not directly affected — felt the impact.
So yes, one badly configured DNS change can take down the whole Internet.
The Dangers of DNS Failure
When DNS fails, it usually does not cause loud, obvious problems — it causes problems with a whisper. By the time the symptoms are noticed, it is often too late. Several characteristics of DNS failures can be particularly damaging:
Centralization of Trust
Most organizations use a single DNS provider (often internal or cloud-based), creating a central point of failure.
Hidden Dependencies
Many internal systems rely on the same DNS layers as public-facing ones. Monitoring, authentication, and billing systems are often unknowingly intertwined.
Automation Risk
Because manually editing production DNS is risky and tedious, updates are automated — often without sufficient constraints. This is not unlike giving a CI/CD pipeline a chainsaw.
Limited Observability
DNS failures remain invisible until resolution fails. Monitoring tools often do not detect issues early, and soon become blind to failures until it is too late, when seconds matter.
Diagram: How a DNS Failure Ripples Through Layers
DNS misconfiguration → Service discovery fails → APIs cannot resolve → Databases unavailable → Retry storm → Network congestion → Service failure → Customer impact
See the chain? The failure is only partially technological — it is structural.
What Do We Learn from the Amazon Outage to Avoid Becoming the Next Cautionary Tale?
Here are five battle-tested lessons all engineers should heed:
Design for Redundancy (But Limited to That)
Use multi-provider and multi-regional DNS. Route intelligently so a single vendor failure does not take down your application. But remember: redundancy is not resiliency until it is proven.
Fail Gracefully
Your application must degrade — never die.
If DNS resolution fails, can your service serve cached data? Can users still access local functionality? Build systems that bend before they break.
Automate — with Guardrails
Automation is powerful, but critical DNS changes should require manual approvals. Always include rollback mechanisms so bad configurations can be reversed instantly.
Chaos-Test Dependencies
Don’t just chaos-test servers or APIs — chaos-test DNS. Simulate DNS outages and observe what breaks. You will uncover invisible dependencies you never knew existed.
Monitor the Unseen
Treat DNS as a first-class citizen in observability. Use synthetic checks to resolve key domains every few seconds. If these fail, panic before the customer does.
A Practical DNS Failover Example:
var dns = require('dns');
var cache = {};
async function resolve_host(hostname) {
var cached = cache[hostname];
if (cached && (Date.now() - cached.timestamp) < 60000) { // <--- if the cached value is less than 60 seconds old
return cached.address;
}
try {
var address = (await dns.promises.resolve4(hostname))[0];
cache[hostname] = { address: address, timestamp: Date.now() };
return address;
} catch (err) {
console.error('DNS lookup failed for ' + hostname);
if (cached) {
console.warn('Using cached IP due to DNS error');
return cached.address;
}
throw new Error('Host unreachable -- no cached DNS record available');
}
}This simple example caches successful lookups for one minute and falls back to them if DNS fails. Simple? Yes. Effective? Certainly.
Would your application survive a DNS hiccup like this? Something to think about.
Resiliency Is More Than Redundancy
Here’s the hard truth: resiliency is determined less by how many backups you have and more by what happens when systems fail.
When DNS crashed internally at AWS, many servers, regions, and microservices were functioning perfectly — but it didn’t matter. Without a “phonebook,” nothing could be used.
Resiliency is about anticipating failure, not claiming invulnerability. Ask yourself:
- What happens when my DNS server goes down?
- What is the user impact?
- How quickly can we detect, respond, and recover?
That mindset — preparation over prevention — is what separates robust systems from brittle ones.
The Larger Concept: DNS as a Design Mindset
It is easy to think of DNS as mere infrastructure. As this incident shows, it is architecture. You wouldn’t build an API without authentication or rate limiting would you? Certainly, DNS should be a part and parcel of your design reviews, failure simulations, and disaster recovery planning.
In designing distributed systems, do not think just of uptime dashboards. Think about connectivity flow. How do your services find each other? What happens when they do not? There are going to be outages. Cloud ecosystems will grow more complex. The real question is not, “How could this happen at Amazon?” but rather, “Would we survive this?”
Important Points
- DNS is not behind-the-scenes plumbing — it is the heartbeat of your system.
- Automation must be instituted with caution and governed by guardrails to prevent cascading failures.
- Chaos-test dependencies before production teaches you painful lessons.
- Redundancy does not equal resiliency — test assumptions in real time periods of stress.
- Monitor DNS as closely as CPU or memory.
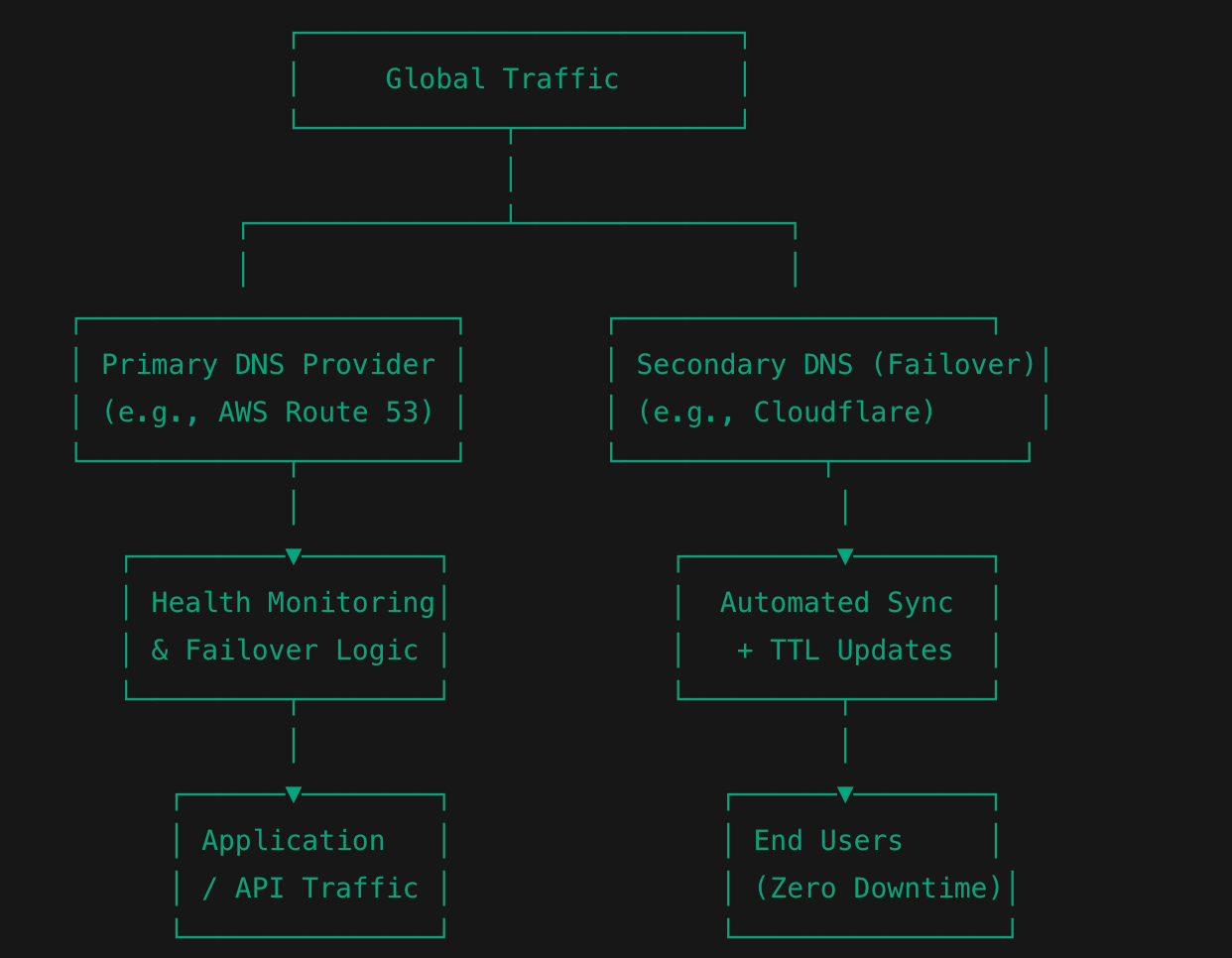
Image: Multi-Provider DNS Resilience
Two separate DNS providers can be continuously health-checked. If one fails, the other seamlessly takes over. The user never notices. This is how platforms like Netflix or Cloudflare survive while others fail.
FAQ: Common Questions
Q1: Isn’t DNS already redundant?
Yes, but single-provider redundancy is insufficient. Cross-provider configurations provide true fault tolerance.
Q2: Should DNS always be automated?
Yes — but cautiously. Always include validation, review, and rollback mechanisms. Automation without human oversight invites disaster.
Q3: How often should DNS be chaos-tested?
Quarterly. Treat it like a fire drill — rare enough to avoid disruption, frequent enough to build muscle memory.
Q4: Can DNS failures be detected early?
Absolutely. Synthetic monitoring tools (like Pingdom) or custom scripts can continuously resolve critical hostnames and detect latency or lookup failures.
Conclusion
This DNS outage is not just an AWS incident — it is a mirror held up to everyone building in the cloud.
As everything now depends, directly or indirectly, on DNS, breaking this foundation causes even the strongest systems to stumble.
So next time you assess your architecture or automate a workflow, pause and ask yourself: What is my DNS story?
Because when DNS fails, it’s not just DNS that fails — it’s our assumptions. And that is where real engineering begins.
Opinions expressed by DZone contributors are their own.
Comments