When To Use the @DynamicUpdate With Spring Data JPA
Explore a few scenarios to use @DynamicUpdate with Spring Data JPA. Different classes of databases are highlighted, including PostgreSQL and YugabyteDB.
Join the DZone community and get the full member experience.
Join For FreeThe Spring Data JpaRepository interface comes with the save(S entity) method that is frequently used to update an entity representation on the database level. By default, the method generates an UPDATE statement that requests a change to the values of all the entity class columns. This includes the columns not touched by your application code. However, this behavior can be far from satisfactory for several reasons.
Luckily, Hibernate supports the @DynamicUpdate annotation that, once applied to an entity class, helps the save(S entity) and similar methods generate a SQL update command with columns that are actually changed.
But nothing comes for free. There is a cost to track and generate a better version of the UPDATE statement at runtime. In this article, we’ll review a few scenarios where you should use @DynamicUpdate for your entity classes.
Default Behavior
Let’s step back and remind ourselves how the save(S entity) method works by default.
Suppose you have a simple entity class to track pizza orders that has three columns: id, status, and orderTime:
@Entity
@DynamicUpdate
@TypeDef(name = "order_status", typeClass = PostgreSQLEnumType.class)
public class PizzaOrder {
@Id
private Integer id;
@Enumerated(EnumType.STRING)
@Column(columnDefinition = "post_status_info")
@Type(type = "order_status")
private OrderStatus status;
@CreationTimestamp
private Timestamp orderTime;
public enum OrderStatus {
Ordered,
Baking,
Delivering,
YummyInMyTummy
}
}
Imagine the pizzeria already has an order in the queue with id=1:
Optional<PizzaOrder> orderOptional = repository.findById(1);
PizzaOrder pizzaOrder = orderOptional.get();
System.out.println(pizzaOrder);
// Printed to the log
// PizzaOrder [id=1, status=Ordered, orderTime=2022-11-15 12:46:07.342]When the chef gets to this order, the system changes status from Ordered to Baking, and saves the order to the database:
PizzaOrder pizzaOrder = …; // an instance of the order with the status=Ordered
pizzaOrder.setStatus(OrderStatus.Baking);
repository.save(pizzaOrder);The status changed with no issues but Hibernate generated the following SQL statement for the repository.save(pizzaOrder) call above:
Hibernate:
update
pizza_order
set
order_time=?,
status=?
where
id=?As you can see, even though the application logic left the order_time column intact, Hibernate still included that column in the update list.
Behavior With @DynamicUpdate Annotation
Luckily, Hibernate is a feature-rich and flexible framework so you can change that default behavior by labeling the PizzaOrder entity with the @DynamicUpdate annotation:
@Entity
@DynamicUpdate
@TypeDef(name = "order_status", typeClass = PostgreSQLEnumType.class)
public class PizzaOrder {
// The rest of the implementation
}Once you apply the annotation and rerun the test that changes the order status from Ordered to Baking, you’ll see that Hibernate generates an optimized SQL command for the repository.save(pizzaOrder) call:
Hibernate:
update
pizza_order
set
status=?
where
id=?Hibernate no longer asks to update the order_time column. Thanks to the @DynamicUpdate annotation, your database will update the columns that are actually changed by the application.
But, as it was mentioned at the beginning of this article, nothing is free. This annotation is not the default as long as it has a performance overhead—column-level changes of an entity need to be tracked. Additionally, Hibernate needs to generate proper SQL statements based on those changes.
When should you use the @DynamicUpdate annotation, then? Let’s review three cases.
Case #1: Entity Has Way Too Many Columns
Our first case is straightforward and applies to all types of databases that Spring Data can run on.
The PizzaOrder entity has three fields. It’s not a big deal that Hibernate transfers an extra field (the order_time) to the database even though the application does not change that field. The impact is negligible.
However, your application can have entity classes with dozens of fields. Field size can range from a single byte (boolean) to thousands of bytes (Strings and Arrays). Such entities are excellent candidates for the @DynamicUpdate annotation. Otherwise, you’ll waste network, CPU, and other resources on the serialization, transportation, and deserialization of entity columns that are not modified.
Case #2: Database Supports Column-Level Locking
Our second case is less apparent than the previous above. It’s database-specific.
Usually, SQL databases such as PostgreSQL, MySQL, or Oracle use row-level locking even if you update a single column of a row.
Let’s refresh our knowledge about row-level locking using PostgreSQL as an example.
Suppose you annotated the PizzaOrder with @DynamicUpdate. Now Hibernate generates the following optimized statement whenever you change and persist a pizza status through the repository.save(S entity) method:
Hibernate:
update
pizza_order
set
status=?
where
id=?Now, imagine that transaction #1 changes the status column while transaction #2 attempts to update the order_time column concurrently.
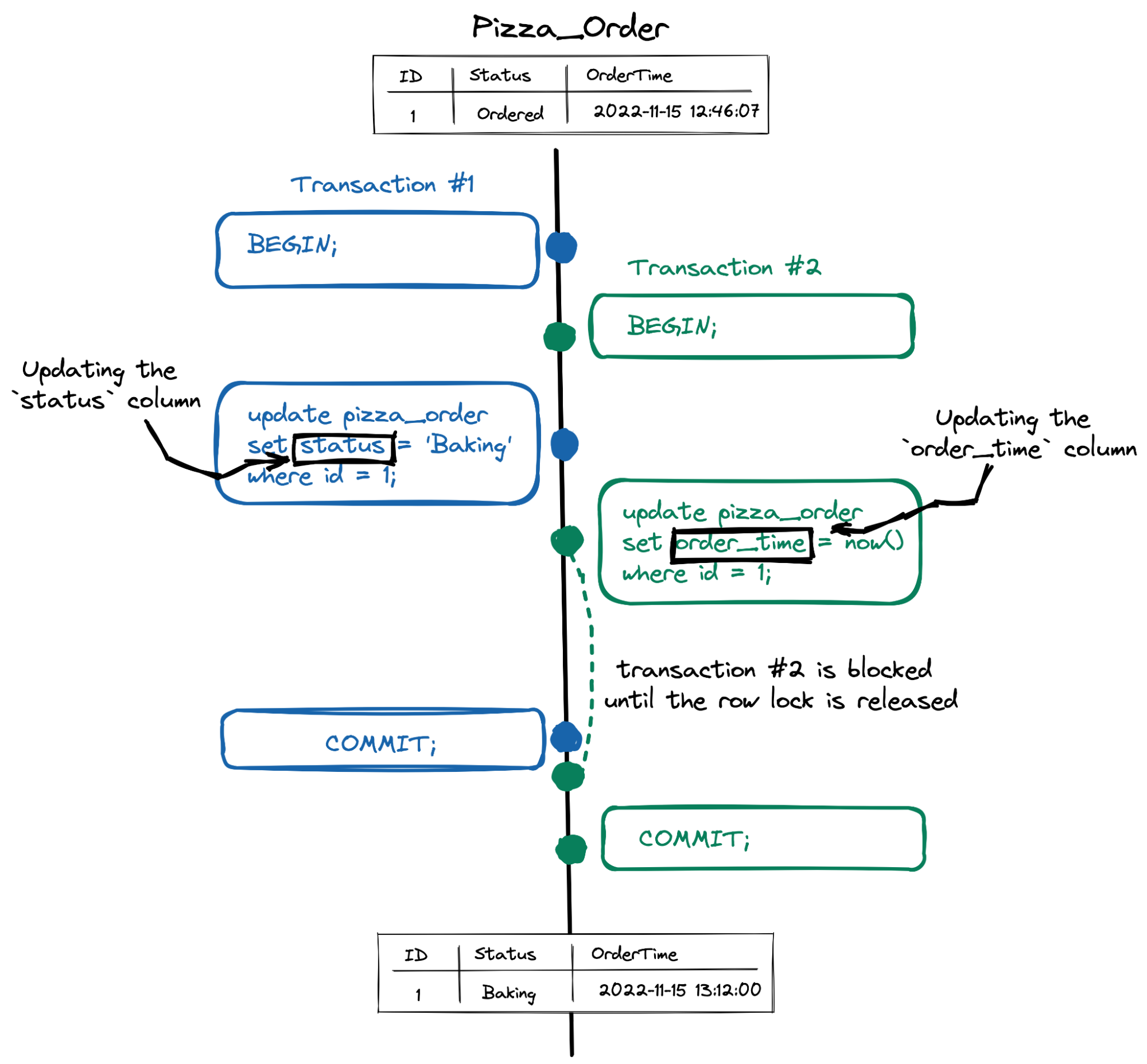
As the diagram shows, even though each transaction updates two different columns, transaction #2 still has to wait until transaction #1 releases an exclusive row-level lock.
So, from a concurrency perspective, if your database uses a row-level locking approach, the @DynamicUpdate annotation doesn’t improve the parallelism. Transaction #2, which updates the order_time column, will be blocked even when transaction #1 updates a completely different status column.
However, there is a class of databases that uses the column-level locking approach to ensure data consistency. YugabyteDB, a distributed SQL database that is built on PostgreSQL, belongs to this class.
Using this type of database, let's run the same example. Transaction #1 updates the status and transaction #2 updates the order_time for the record with id=1. Both transactions execute concurrently, and this time, not blocking each other.

Overall, using @DynamicUpdate on YugabyteDB or another database that uses column-level locking has a profound effect, even for entities with a few fields. As you know, without that annotation, Hibernate will enlist all the entity fields in the UPDATE statement, which will significantly increase the likelihood of contention between concurrent transactions. Therefore, your application will not fully benefit from the column-level locking approach. So, use @DynamicUpdate with this database type!
Case #3: Database Supports Column-level Versioning of Data
Column-level locking usually comes together with the column-level versioning of application data. The latter improves throughput and performance by minimizing contention between concurrent transactions. The former lets the database’s MVCC engine use available storage space more prudently when compared to the row-level versioning of the data.
MVCC stands for Multi-Version Concurrency Control. It lets transactions execute with as little contention as possible (preserving data consistency). To achieve this, the MVCC engine has to be able to store multiple copies of a row or a column so that several transactions can access the row/column concurrently with no impact on each other. The article How does MVCC (Multi-Version Concurrency Control) works offers a great introduction to MVCC for Java developers.
So let’s look at another example. Suppose that the PizzaOrder entity is already annotated with @DynamicUpdate:
@Entity
@DynamicUpdate
@TypeDef(name = "order_status", typeClass = PostgreSQLEnumType.class)
public class PizzaOrder {
// The rest of the implementation
}And now the application changes the order status three times from Ordered to Baking to Delivering and to YummyInMyTummy. Each time the status is changed, the modification is saved to the database:
PizzaOrder pizzaOrder = …; // an instance of the order with the status=Ordered
pizzaOrder.setStatus(OrderStatus.Baking);
repository.save(pizzaOrder); //saving to the database
pizzaOrder.setStatus(OrderStatus.Delivering);
repository.save(pizzaOrder); //saving to the database
pizzaOrder.setStatus(OrderStatus.YummyInMyTummy);
repository.save(pizzaOrder); //saving to the databaseAs long as @DynamicUpdate is used, Hibernate requests to update only the status column:
Hibernate:
update
pizza_order
set
status=?
where
id=?If the logic is executed against PostgreSQL, then, as expected, the last version of the row with status=YummyInMyTummy will be visible to all future application requests:
select * from pizza_order where id = 1;
id | status | order_time
----+----------------+-------------------------
1 | YummyInMyTummy | 2022-11-16 13:33:31.577However, the other versions of the record with status equal to Ordered, Baking, and Delivering are not gone yet. They still exist and will be garbage collected later by the vacuum process. In the meantime, you can find those versions with the pageinspect extension:
create extension pageinspect;
select lp,t_data from heap_page_items(get_raw_page('pizza_order',0));
lp | t_data
----+------------------------------------
1 | \x0100000002400000a8ae874995900200
2 | \x0100000004400000a8ae874995900200
3 | \x0100000006400000a8ae874995900200
4 | \x0100000008400000a8ae874995900200- The version of the row with
lp=1is the initial one. It was created when the application inserted the pizza order into the database with thestatuscolumn set toOrdered. - The line with
lp=2represents the row version withstatus=Bakingandlp=3is for the version withstatus=Delivering. - The version with
lp=4is for the last update. This is the version of the row your application sees when it executes theselect * from pizza_order where id = 1request.
The t_data value is used to construct a pointer to the row’s user data.
So, from the MVCC storage space usage perspective, it doesn’t really matter to PostgreSQL if your application uses the @DynamicUpdate annotation or not. Whether Hibernate requests to update just the status column (@DynamicUpdate is used) or all of the columns (@DynamicUpdate is not utilized), PostgreSQL still creates a full copy of the record with all of the fields.
Now, let’s contrast this to YugabyteDB, which supports column-level versioning of the user data.
If you execute the same logic against YugabyteDB:
PizzaOrder pizzaOrder = …; // an instance of the order with the status=Ordered
pizzaOrder.setStatus(OrderStatus.Baking);
repository.save(pizzaOrder); // saving to the database
pizzaOrder.setStatus(OrderStatus.Delivering);
repository.save(pizzaOrder); // saving to the database
pizzaOrder.setStatus(OrderStatus.YummyInMyTummy);
repository.save(pizzaOrder); // saving to the databaseThen look into its storage data files, and you’ll discover that YugabyteDB stores several copies of the status column only—with no extra copies of the order_time column:
[ColumnId(1); HT{ physical: 1668626516257082 }]) -> 4647714815446368264; intent doc ht: HT{ physical: 1668626516251693 }
[ColumnId(1); HT{ physical: 1668626516230507 }]) -> 4629700416936886278; intent doc ht: HT{ physical: 1668626516223517 }
[ColumnId(1); HT{ physical: 1668626516201335 }]) -> 4611686018427404292; intent doc ht: HT{ physical: 1668626516186782 }
[ColumnId(1); HT{ physical: 1668626516095804 w: 1 }]) -> 4575657221408440322; intent doc ht: HT{ physical: 1668626516063896 w: 1 }
ColumnId(2); HT{ physical: 1668626516095804 w: 2 }]) -> 721923716006000; intent doc ht: HT{ physical: 1668626516063896 w: 2 }- The first line with
ColumnId(1)is the initial value of thestatuscolumn (Ordered) and the next two lines for theBakingandDeliveringstatuses. - The fourth line from the top with
ColumnId(1)represents the latest value of thestatuscolumn, which isYummyInMyTummy. This is the version your application will see when it executes theselect * from pizza_order where id = 1statement next time.
The final line with ColumnId(2), stores the only version of the order_time column that the application logic never changed. Therefore, it’s important to annotate entities with @DynamicUpdate if an underlying database uses the column-level versioning for the MVCC. Without @DynamicUpdate, Hibernate would ask YugabyteDB to update the order_time column as well, and YugabyteDB would keep several copies of order_time with identical values. This wastes:
- Storage space
- The time the compaction process spends on the garbage collection of the old column versions
Wrapping Up
The @DynamicUpdate annotation is not used by default for all entity classes because some cost is associated with the changes tracking and query generation at runtime. But, the annotation was introduced to Hibernate for good reasons. We have reviewed some of those reasons in this article. Keep a note of those cases, and make sure to use @DynamicUpdate when the time is right.
Opinions expressed by DZone contributors are their own.
Comments