Processing of Streaming Data: Kappa vs Lambda Architectures
In today’s Big Data landscape, Lambda architecture is a new archetype for handling a vast amount of data. How does it compare to Kappa architecture?
Join the DZone community and get the full member experience.
Join For FreeData is quickly becoming the new currency of the digital economy, but it is useless if it can’t be processed. The processing of data is essential for subsequent decision-making or executable actions either by the human brain or various devices/applications, etc. There are two primary ways of processing data: namely, batch processing and stream processing. Typically batch processing has been adopted for very large data sets and projects where there is a necessity for deeper data analysis. On the other side, stream processing is used for speed and quickness as soon as data gets generated at the source. In stream processing, a data point or “micro-batch” is inserted directly into the analytical system bit-by-bit as soon as it is generated and processed subsequently to produce key insights in near real-time. By leveraging platforms/frameworks like Apache Kafka, Apache Flink, Apache Storm, or Apache Samza, we can make decisions quickly and efficiently from generated key insights after processing the streaming of data. (In my previous post "Crafting a Multi-Node Multi-Broker Kafka Cluster- A Weekend Project," read more on how to install Apache Kafka.)
Before developing a system or new infrastructure at the enterprise level for data processing, the adoption of efficient architecture is mandatory to ensure software/frameworks are flexible and scalable enough to handle the massive volume of data with an open design principle. In today’s Big Data landscape, the Lambda architecture is a new archetype for handling the vast amount of data. This architecture can be adopted for both batches as well as stream processing of data as it is a combination of three layers namely batch layer, speed or real-time layer, and service layer. Each layer in the Lambda Architecture relay on various software components.
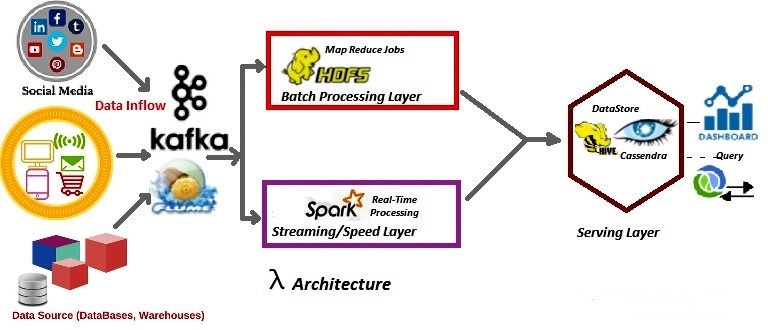
The batch or batch processing layer is responsible to process in a batch-wise manner when data is at rest and ideally software components like Apache Hadoop and its ecosystems are deployed here. In a nutshell, data at rest means to store data in a database, data warehouse, or data lake. A massive volume of data regardless of any data format gets persisted in HDFS or data lake and subsequently processed in a batch-wise manner using the Map-Reduce framework on demand. For responding to queries demanded by various dashboards/BI teams eventually, the service layer takes the inputs from processed data in the batch layer.
To achieve the processing when data is in motion, software components like Apache Flink, Apache Storm, Apache Spark, etc. are deployed in the speed layer and eventually fed to the service layer for querying. Unlike the batch layer, the components in the speed layer will read the data while traveling over the wire after generation at the source point and transform it into the analyzable format. This layer makes recent data quickly available for end-user queries via the service layer.
Multiple concerns are surfacing with Lambda architecture even though it supports batch as well as speed or real-time processing together for the massive volume of data generated at lightning speed. The concerns or issues can be bulleted as:
- Two different infrastructures, monitoring, and logs as supports are required separately for each type of data processing.
- Separate algorithms to maintain consistent data quality
- Two different code bases and subsequently coordinated releases when changes/enhancements and modifications occur in each code base; besides, it must be maintained and kept in sync so that processed data produces the same result from both paths.
- Introduces complexity when toggling to support what to read when
- The operational infrastructure becomes more complex and increases the cost and maintenance while implementing the Lambda architecture to support many Big Data frameworks.
To replace the major bottleneck of managing two separate code bases, reducing complex infrastructures, etc. in the Lambda architecture, a single technology stack has been adopted in the Kappa architecture to perform both real-time and batch processing, especially for analytics.
The Kappa architecture is event-based and able to handle all data at all scales in real time for transactional as well as analytical workloads. In this architecture, an incoming series of data is first stored in a message engine like Apache Kafka, Amazon Kinesis, etc., and then fed into a streaming computation system like Apache Flink, Kafka Streams, etc. where the reading of data and transformation would take place and eventually store it into an analytics database or business applications (Servicing Layer) for end users to query.
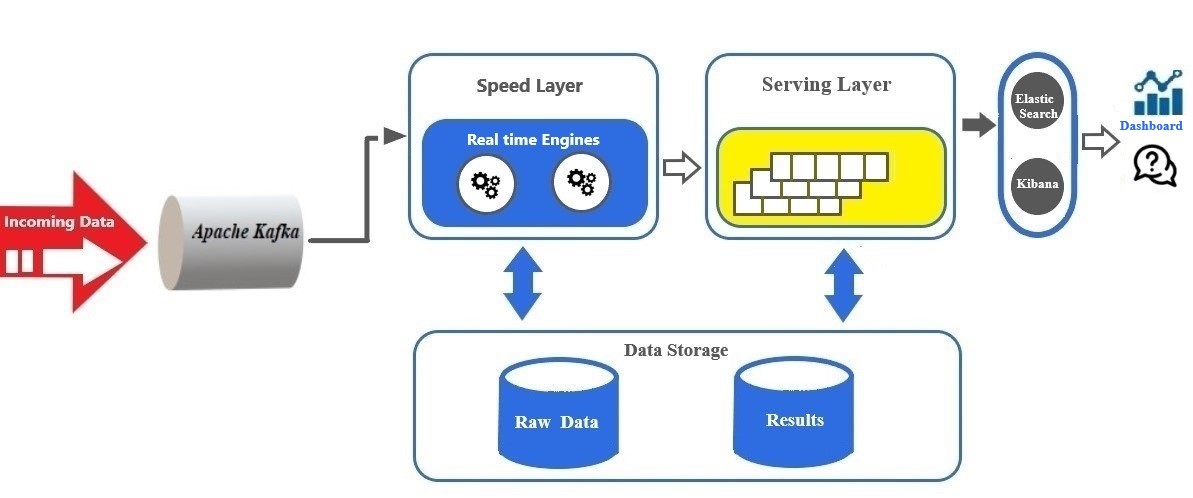
As Hazelcast's article "What Is the Kappa Architecture?" highlights, using Kappa architecture, we can build a stream processing application to handle real-time data, and if we desire to modify the output, update/modify the codebase and then run it again over the data in the messaging engine in a batch manner. Unlike the Lambda architecture, there is no separate technology required to handle batch processing.
There are multiple uses that the Kappa architecture is offering:
- One set of infrastructure and technology
- Only one code base that is always in sync
- With single architecture, can handle all the use cases related to streaming, RPC, batch, etc.
- Can eliminate re-architect for new use cases
- Single processing framework for both real-time and batch systems
By integrating a high-speed stream processing engine with Apache Kafka, the Kappa architecture can be developed. At present in many deployments, Apache Kafka ideally acts as the pool/accumulation for streaming data, and then multiple stream processors act on the data subsequently stored in Kafka to produce multiple outputs.
We can’t completely rely on an event streaming platform to build the Kappa architecture as additional databases and analytical tools are mandatory for some use cases. For example, Apache Kafka with Kafka streams is not sufficient alone to execute complex SQL queries and joins to achieve meaningful results on the processed streaming records without another additional database. In a real-time scenario, there is a major problem in the Kappa architecture for storing the vast volume of data inside the components of the event streaming platform. The scalability issues and the cost factor were other additional bottlenecks when Kappa architecture was adopted for processing data volume at the terabyte or petabyte scale. However, the concept of tiered storage in the event streaming platform started acting as a fulcrum to boost the efficiency of the Kappa architecture. In a nutshell, the tiered storage manages the storage without a performance impact on real-time consumers and allows for decoupling of storage from computing in platforms such as Apache Kafka. So finally we can say, tiered storage is revolutionary for Kafka architectures.
Just two points to emphasize before I wrap up while adopting Kappa architecture over Lambda architecture to deploy big data processing.
- The only requirement is to efficiently process the distinct events that are occurring or producing at numerous active data sources or IoT devices in order to take instant action.
- Be skeptical about spending more revenue to build or maintain expensive infrastructure/hardware for retaining data in the data lake for future use as well as implementing machine learning models.
Hope you have enjoyed this read. Please like and share if you feel this composition is valuable.
Published at DZone with permission of Gautam Goswami. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments