Why PostgreSQL CDC Breaks in Production
PostgreSQL CDC often fails after WAL reading: snapshot handoff gaps, unsafe checkpoints, bad ordering, and retry logic can silently corrupt replicated data.
Join the DZone community and get the full member experience.
Join For FreeKeeping two PostgreSQL databases in sync sounds simple. Until it isn’t.
At first, everything looks fine:
- Logical replication is enabled
- Changes are flowing
- The target database looks current
Then, a few days later, something is off:
- Rows are missing
- Some updates appear twice
- Replication lag jumps for no obvious reason
- A small schema change breaks the pipeline
- Restarting the job does not clearly continue from the right place
Now the problem is no longer “how do I stream changes from PostgreSQL?” The problem is proving that the target database is still correct.
That is where most PostgreSQL CDC guides stop being useful. They explain how to enable logical replication. They explain replication slots, publications, WAL, maybe Debezium.
That is useful.
But production CDC usually breaks somewhere else: in the handoff between initial load and CDC, in retries, in checkpoints, in ordering, and in the recovery paths nobody tests until something fails.
The Promise of PostgreSQL CDC
Change data capture exists for a good reason.
Instead of repeatedly querying whole tables or running batch exports, PostgreSQL can stream committed changes from its write-ahead log.
In theory, that gives you:
- Near real-time replication
- Less load on the source database
- No polling loops
- No full reload after every change
And yes, that part works.
WAL is reliable. Logical replication is mature. PostgreSQL can tell you what changed and in what order. The hard part starts after that. Because WAL is only one part of the system.
Once changes leave PostgreSQL, they usually pass through readers, queues, workers, retry logic, target writes, checkpoints, and monitoring. That is where things get interesting. Also annoying.
Where PostgreSQL CDC Actually Breaks
A simplified CDC pipeline often looks like this:
PostgreSQL WAL
|
v
CDC reader
|
v
Queue / buffer
|
v
Workers
| |
v v
Target Retry / failure handlingPostgreSQL WAL is ordered. Your pipeline may not be.
The moment you add queues, parallel workers, retries, and target writes, correctness becomes your responsibility. Not just throughput. Not just “events per second.” Correctness.
That means answering questions like:
- Did the target receive every committed change?
- Were updates applied in the right order?
- Did a retry apply the same change twice?
- Was the checkpoint saved before or after the target write?
- What happens if the job stops halfway through a large initial load?
- What happens if CDC starts after the snapshot, but not from the snapshot boundary?
Those are the questions that decide whether CDC is reliable in production.
1. Initial Load Is Not CDC
CDC starts from a point in time. It does not recreate everything that already existed before that point.
So if the target is empty, you first need a baseline copy of the existing data. Usually, this is called an initial load or snapshot.
The hard part is what happens next.
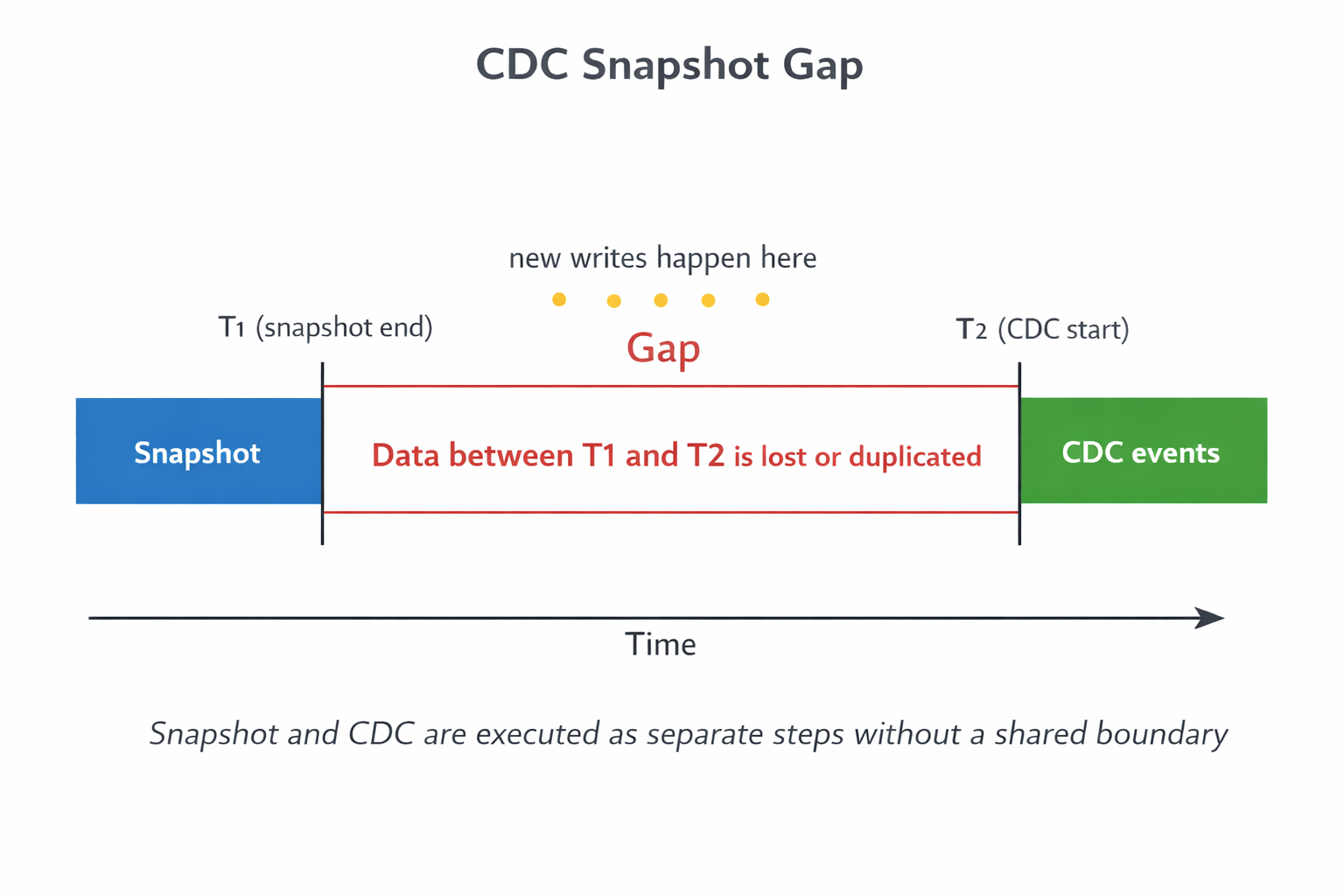
If CDC starts from the wrong position, the target may miss rows, replay rows, or apply stale updates.
This is the snapshot gap. It appears when initial load and CDC are run as separate steps without a shared WAL boundary.
snapshot + CDCis two separate operations.snapshot → CDCis a controlled handoff.
- Read a consistent snapshot
- Record the matching WAL position
- Start CDC from that position
Anything else is guessing.
2. WAL Is Ordered, But Workers Can Break Ordering
PostgreSQL emits changes in commit order. That does not mean your target receives them in a safe order.
Once a pipeline introduces parallelism, ordering can break. For example:
Event 1: update customer id = 42
Event 2: delete customer id = 42If these events are processed by different workers, the delete might reach the target first.
Or this:
Event 1: insert parent row
Event 2: insert child rowIf the child insert arrives first, the target may reject it because the parent row does not exist yet. The usual answer is controlled parallelism:
- Preserve ordering per table where needed
- Avoid unsafe reordering inside the same key/table stream
- Batch carefully
- Retry without changing event order
Parallelism is not bad. Blind parallelism is bad.
CDC systems usually fail here when they optimize for speed before defining ordering guarantees.
3. At-Least-Once Delivery Means Duplicates Are Normal
Most CDC pipelines are at least once. That means an event may be delivered more than once. This is not automatically a bug.
It is a normal recovery behavior. If the pipeline writes to the target, then crashes before saving its checkpoint, it may replay the same event after restart. That is why target writes must be idempotent.
For database-to-database replication, this usually means:
- Inserts should behave like upserts when possible
- Updates should be safe to apply more than once
- Deletes should not fail the whole stream if the row is already gone
- Primary keys matter
If the target write logic is not idempotent, retries can silently corrupt data. For example:
- Duplicate inserts
- Counters incremented twice
- Audit rows repeated
- Append-only targets growing incorrect history
CDC without idempotent target writes is fragile.
It may work in a demo.
Production will eventually find the retry path. Production has a talent for that.
4. Checkpoints Must Be Commit-Aware
Checkpointing sounds simple:
Save the last processed WAL position.
But the timing matters.
If the checkpoint is saved too early, the failure path looks like this:
- CDC reads an event at LSN X.
- Checkpoint advances to X.
- Target write fails.
- Process crashes before the failure is handled.
- Restart begins after X, so the event is skipped.
The system now believes the event was delivered. But it was never written to the target.
That is silent data loss. The safe order is:
- Read event
- Write to target
- Wait for target ACK
- Advance checkpoint
This way, if the process crashes after reading but before committing to the target, the event can be replayed. That may create duplicates if target writes are not idempotent, but it avoids skipping committed source changes.
This is the usual tradeoff:
- Checkpoint too early → data loss
- Checkpoint after commit → possible replay
- Replay + idempotency → safe recovery
A reliable CDC system must choose the boring, safe option.
5. Schema Changes Are Not Free
CDC captures data changes. It does not magically solve schema evolution. In real systems, someone eventually:
- Adds a column
- Changes a type
- Renames a table
- Drops a column
- Changes a default
- Modifies a constraint
Then the CDC pipeline has to answer:
- Does the target schema already have this column?
- Can this type be mapped safely?
- Should the pipeline stop or continue?
- What happens to old events?
- What happens to in-flight batches?
Some platforms try to automate schema evolution. That can be useful, especially in analytics pipelines.
But for database-to-database replication, automatic schema changes can also be dangerous. A production target is not always just a passive copy. It may have constraints, indexes, permissions, triggers, or application dependencies.
The safest practical answer is usually:
- Detect schema mismatch clearly
- Fail loudly when target writes are unsafe
- Let operators coordinate schema changes
- Do not silently invent a broken target schema
A CDC pipeline that keeps running incorrectly is worse than one that stops. At least a stopped pipeline is honest.
6. Long Transactions Create Hidden Lag
CDC lag is not always caused by slow networking or slow consumers. Sometimes the source transaction itself is the problem. PostgreSQL changes become safe to replicate only after the transaction commits.
So a large transaction can look quiet for a while, then suddenly release a huge batch of changes at once.
BEGIN;
UPDATE orders
SET status = 'archived'
WHERE created_at < '2024-01-01';
– this runs for several minutes
– CDC cannot treat these row changes as final yet
COMMIT;While the transaction is open, downstream replication may appear to be stuck or falling behind.
After COMMIT, all those changes become visible together. Result:
- Replication lag jumps
- Target writes arrive in a burst
- Workers suddenly have a backlog
- Monitoring graphs look haunted
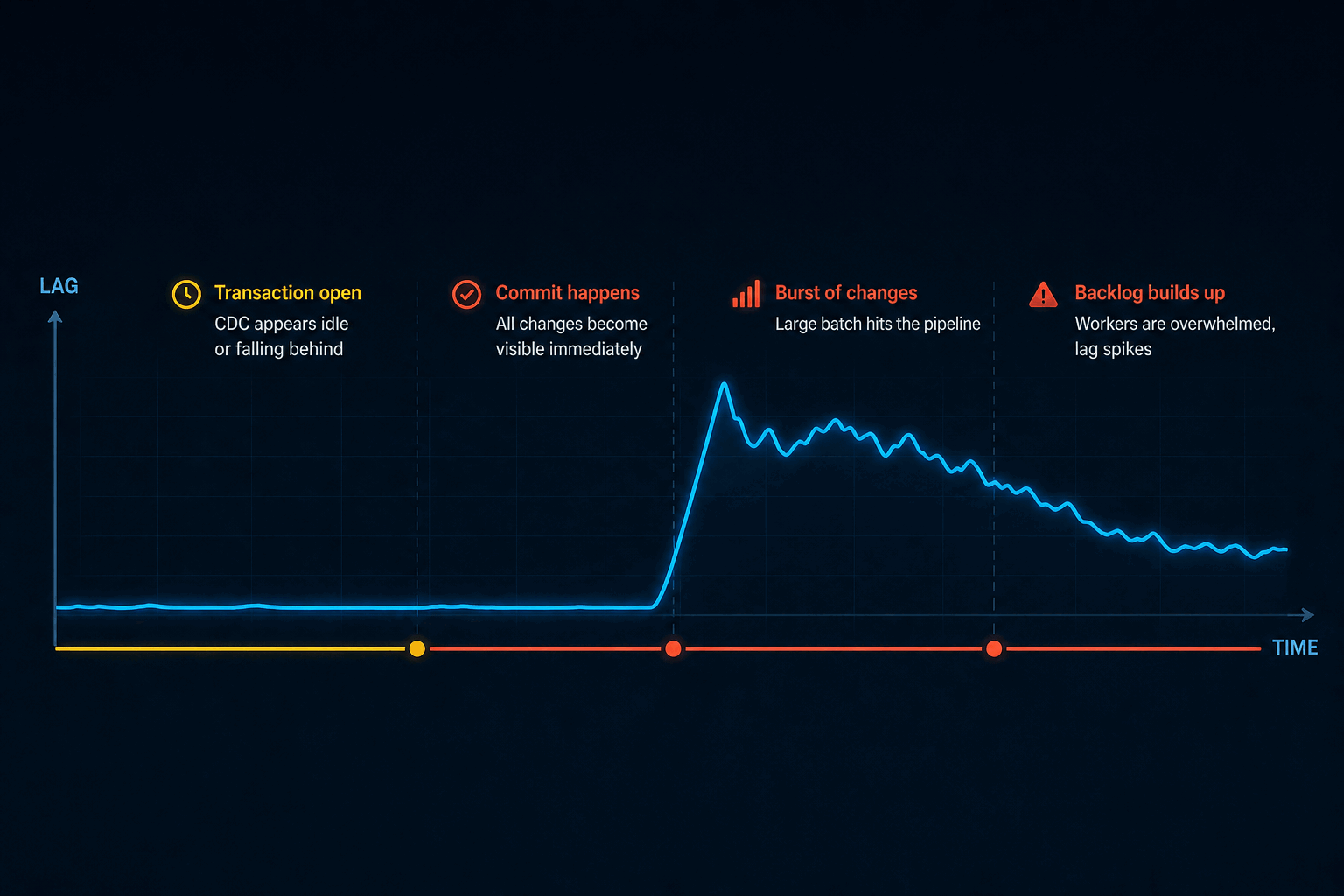
This is common during bulk updates, maintenance jobs, large imports, or application code that keeps transactions open too long.
CDC cannot remove this behavior. It can only process the changes once PostgreSQL makes them committed and visible.
7. Restarts Are Where Fake Reliability Gets Exposed
A CDC pipeline that works while everything is healthy is not enough.
The real test is what happens after:
- Service restart
- Database disconnect
- Target write failure
- Process crash
- Machine reboot
- Operator pressing "Stop"
Restart behavior must be explicit. The system should know:
- The last durable source position
- Whether the target write was acknowledged
- Whether the initial load had completed
- Whether CDC handoff had happened
- Whether a partially loaded table can continue safely
If those states are not stored durably, restart becomes guesswork. And guesswork is not a recovery strategy. Treat CDC as a workflow, not just a stream.
Most real database movement work does not start with CDC. It starts with questions:
- Which tables should be copied?
- How large are they?
- Does the target schema match?
- Can the existing data be loaded safely?
- Where is the handoff point between the initial load and CDC?
- How do we validate the initial load?
- How do we keep validating after the CDC starts?
- How do we recover if something stops?
But many setups split those steps across tools:
SQL client → export → scripts → pipeline → CDC → validationEach tool may be fine on its own. The problems live in the gaps:
- Assumptions are lost
- State is not shared
- Validation becomes manual
- Handoff points are unclear
- Restart behavior is inconsistent
That is why CDC should be treated as part of the full data movement workflow:
explore → load → validate → replicate → keep validatingNot because workflows look nice on a diagram, but because the correctness problems happen between those steps.
What a Reliable CDC System Needs
A production CDC system should handle failure and recovery paths deliberately:
- Pure CDC without initial load: target writes must be idempotent, and checkpoints must be durable.
- Initial load → CDC: CDC must start from the snapshot boundary.
- Restart after stop: checkpoints must advance only after successful target writes.
- Interrupted large load: the system must know what was already copied.
- Delayed CDC after snapshot: the system must not start blindly from “now.”
- Schema mismatch: the system should fail clearly, not silently corrupt data.
These scenarios look boring. They are also where many CDC implementations fail.
Not because PostgreSQL is unreliable. Because the workflow around PostgreSQL CDC is incomplete.
When Debezium + Kafka is the right answer
A common production CDC architecture looks like this:
PostgreSQL → Debezium → Kafka → consumer → target databaseThis can be the right architecture. Especially when you need:
- Kafka as the central event backbone
- Multiple independent consumers
- Event-driven services
- Very high throughput
- Existing Kafka operations
Debezium is a serious CDC tool. Kafka is not the villain. The problem starts when the architecture is much bigger than the job.
If the goal is simply PostgreSQL → PostgreSQL replication, the stack becomes a distributed system around a relatively direct task.
Now every issue has several possible owners:
- PostgreSQL WAL
- Replication slot state
- Debezium connector config
- Kafka topic lag
- Consumer retry logic
- Rarget database writes
- Schema handling between all of the above
When lag appears, where is it? When a row is missing, who skipped it? When an event replays, was it Debezium, Kafka, the consumer, or the checkpoint? When the target schema changes, which layer owns the fix?
Nothing here is impossible. But it changes the problem. You are no longer just moving data. You are operating a multi-component CDC platform.
That may be worth it. But it should be a conscious tradeoff, not the default answer for every sync job. Kafka did not break. The architecture became heavier than the job required.
Where DBConvert Streams Fits
DBConvert Streams keeps the risky parts of PostgreSQL CDC in one workflow:
load → handoff → replicate → resume → validateThat does not remove the hard parts of CDC. It makes them explicit.
Instead of stitching together a snapshot job, a CDC process, retry logic, checkpoints, and validation queries by hand, the workflow is visible in one place.
What Changed in DBConvert Streams 2.1
DBConvert Streams 2.1 focuses on several of these recovery paths:
- Initial load → CDC now hands off automatically from a saved position.
- CDC resumes from the last durable checkpoint after Stop or restart.
- Eligible large load runs can continue from saved progress instead of starting again from zero.
- Schema changes are still not handled automatically and need coordination.
These are workflow changes, not new WAL magic. That is the point.
What DBConvert Streams Does Not Solve Automatically
DBConvert Streams 2.1 does not automatically handle:
- Schema evolution
- Exactly-once delivery across source, pipeline, and target
- Lag caused by long PostgreSQL transactions
- Target repair after manual changes or divergence
These are still operational boundaries.
When CDC Is the Wrong Solution
CDC is not always the answer.
Use something simpler if:
- Data changes rarely
- Latency does not matter
- A nightly reload is acceptable
- The target can be rebuilt cheaply
- Correctness matters more than freshness
Batch jobs are boring.
But boring is not an insult.
Boring systems often fail in predictable ways.
A full reload that takes 10 minutes and is easy to verify may be better than a CDC pipeline nobody fully understands. CDC is worth it when freshness matters, and the source cannot be repeatedly reloaded.
Otherwise, do not add moving parts just to feel enterprise. PostgreSQL will not be impressed. The important part is that they are explicit, not hidden behind a “CDC just works” promise.
Final Thought
PostgreSQL CDC is not hard because WAL is unreliable.
It is hard because a real CDC system has state:
- Snapshot state
- WAL position
- Checkpoint state
- Target commit state
- Retry state
- Schema state
If that state is implicit, CDC breaks in strange ways. If it is explicit, CDC becomes boring. And boring is exactly what production replication should be.
DBConvert Streams 2.1 handles this as one controlled workflow: initial load, CDC handoff, checkpointing, resume, and monitoring.
Published at DZone with permission of Dmitry Narizhnykh. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments