Why Set Is Better Than List in @ManyToMany
In this article, we'll highlight the performance penalties involves by using List or Set in @ManyToMany relationships.
Join the DZone community and get the full member experience.
Join For FreeIn this article, we'll highlight the performance penalties involves by using List or Set in @ManyToMany relationships. We use Spring Data JPA with the default persistence provider, therefore with Hibernate JPA.
First of all, keep in mind that Hibernate deals with @ManyToMany relationships as two unidirectional @OneToMany associations. The owner-side and the child-side (the junction table) represents one unidirectional @OneToMany association. On the other hand, the non-owner-side and the child-side (the junction table) represent another unidirectional @OneToMany association. Each association relies on a foreign key stored in the junction table.
In the context of this statement, the entity removal (or reordering) results in deleting all junction entries from the junction table and reinserts them to reflect the memory content (the current Persistence Context content).
Using List
Let’s assume that Author and Book involved in a bidirectional lazy @ManyToMany association are mapped via java.util.List, as shown here (only the relevant code is listed):
x
public class AuthorList implements Serializable {
...
(cascade = {CascadeType.PERSIST, CascadeType.MERGE})
(name = "author_book_list",
joinColumns = (name = "author_id"),
inverseJoinColumns = (name = "book_id")
)
private List<BookList> books = new ArrayList<>();
...
public void removeBook(BookList book) {
this.books.remove(book);
book.getAuthors().remove(this);
}
}
xxxxxxxxxx
public class BookList implements Serializable {
...
(mappedBy = "books")
private List<AuthorList> authors = new ArrayList<>();
...
}
Further, consider the data snapshot shown in the figure below:

The goal is to remove the book called One Day (the book with the ID of 2) written by the author, Alicia Tom (the author with ID 1). Considering that the entity representing this author is stored via a variable named alicia, and the book is stored via a variable named oneDay, the deletion can be done via removeBook() as follows:
xxxxxxxxxx
alicia.removeBook(oneDay);
The SQL statements triggered by this deletion are:
xxxxxxxxxx
DELETE FROM author_book_list
WHERE author_id = ?
Binding: [1]
INSERT INTO author_book_list (author_id, book_id)
VALUES (?, ?)
Binding: [1, 1]
INSERT INTO author_book_list (author_id, book_id)
VALUES (?, ?)
Binding: [1, 3]
So, the removal didn’t materialize in a single SQL statement. Actually, it started by deleting all junction entries of alicia from the junction table. Further, the junction entries that were not the subject of removal were reinserted to reflect the in-memory content (Persistence Context). The more junction entries reinserted, the longer the database transaction.
Using Set
Consider switching from List to Set as follows:
x
public class AuthorSet implements Serializable {
...
(cascade = {CascadeType.PERSIST, CascadeType.MERGE})
(name = "author_book_set",
joinColumns = (name = "author_id"),
inverseJoinColumns = (name = "book_id")
)
private Set<BookSet> books = new HashSet<>();
...
public void removeBook(BookSet book) {
this.books.remove(book);
book.getAuthors().remove(this);
}
}
public class BookSet implements Serializable {
...
(mappedBy = "books")
private Set<AuthorSet> authors = new HashSet<>();
...
}
This time, calling alicia.removeBook(oneDay) will trigger the following SQL DELETE statement:
xxxxxxxxxx
DELETE FROM author_book_set
WHERE author_id = ?
AND book_id = ?
Binding: [1, 2]
The source code is available on GitHub. This is much better since a single DELETE statement is needed to accomplish the job.
Preserving the Order of the ResultSet
It’s a well-known fact that java.util.ArrayList preserves the order of inserted elements (it has precise control over where in the list each element is inserted), while java.util.HashSet doesn’t. In other words, java.util.ArrayList has a predefined entry order of elements, while java.util.HashSet is, by default, unordered.
There are at least two ways to order the result set by the given columns defined by JPA specification:
- Use
@OrderByto ask the database to order the fetched data by the given columns (appends theORDER BYclause in the generated SQL query to retrieve the entities in a specific order) and Hibernate to preserve this order. - Use
@OrderColumnto permanently order this via an extra column (in this case, stored in the junction table).
This annotation (@OrderBy) can be used with @OneToMany/@ManyToMany associations and @ElementCollection. Adding @OrderBy without an explicit column will result in ordering the entities ascending by their primary key (ORDER BY author1_.id ASC). Ordering by multiple columns is possible as well (e.g., order descending by age and ascending by name, @OrderBy("age DESC, name ASC"). Obviously, @OrderBy can be used with java.util.List as well.
Using @OrderBy
Consider the data snapshot from the below figure:
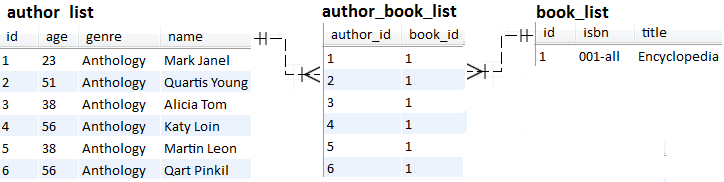
There is a book written by six authors. The goal is to fetch the authors in descending order by name via Book#getAuthors(). This can be done by adding @OrderBy in Book, as shown here:
xxxxxxxxxx
(mappedBy = "books")
("name DESC")
private Set<Author> authors = new HashSet<>();
When getAuthors() is called, the @OrderBy will:
- Attach the corresponding
ORDER BYclause to the triggered SQL. This will instruct the database to order the fetched data. - Signal to Hibernate to preserve the order. Behind the scenes, Hibernate will preserve the order via a
LinkedHashSet.
So, calling getAuthors() will result in a Set of authors conforming to the @OrderBy information. The triggered SQL is the following SELECT containing the ORDER BY clause:
xxxxxxxxxx
SELECT
authors0_.book_id AS book_id2_1_0_,
authors0_.author_id AS author_i1_1_0_,
author1_.id AS id1_0_1_,
author1_.age AS age2_0_1_,
author1_.genre AS genre3_0_1_,
author1_.name AS name4_0_1_
FROM author_book authors0_
INNER JOIN author author1_
ON authors0_.author_id = author1_.id
WHERE authors0_.book_id = ?
ORDER BY author1_.name DESC
Displaying Set will output the following (via Author#toString()):
xxxxxxxxxx
Author{id=2, name=Quartis Young, genre=Anthology, age=51},
Author{id=6, name=Qart Pinkil, genre=Anthology, age=56},
Author{id=5, name=Martin Leon, genre=Anthology, age=38},
Author{id=1, name=Mark Janel, genre=Anthology, age=23},
Author{id=4, name=Katy Loin, genre=Anthology, age=56},
Author{id=3, name=Alicia Tom, genre=Anthology, age=38}
The source code is available on GitHub.
Using @OrderBy with HashSet will preserve the order of the loaded/fetched Set, but this is not consistent across the transient state. If this is an issue, to get consistency across the transient state as well, consider explicitly using LinkedHashSet instead of HashSet. So, for full consistency, use:
xxxxxxxxxx
(mappedBy = "books")
("name DESC")
private Set<Author> authors = new LinkedHashSet<>();
If you liked this article then you'll my book containing 150+ performance items - Spring Boot Persistence Best Practices. This book helps every Spring Boot developer to squeeze the performances of the persistence layer.

Conclusion
When using the @ManyToMany annotation, always use a java.util.Set. Do not use the java.util.List. In the case of other associations, use the one that best fits your case. If you go with List, do not forget to be aware of the HHH-58557 issue that was fixed starting with Hibernate 5.0.8.
Opinions expressed by DZone contributors are their own.
Comments