Apache Spark on Windows
If you were confused by Spark's quick-start guide, this article contians resolutions to the more common errors encountered by developers.
Join the DZone community and get the full member experience.
Join For FreeThis article is for the Java developer who wants to learn Apache Spark but don't know much of Linux, Python, Scala, R, and Hadoop. Around 50% of developers are using Microsoft Windows environment for development, and they don't need to change their development environment to learn Spark. This is the first article of a series, "Apache Spark on Windows", which covers a step-by-step guide to start the Apache Spark application on Windows environment with challenges faced and thier resolutions.
A Spark Application
A Spark application can be a Windows-shell script or it can be a custom program in written Java, Scala, Python, or R. You need Windows executables installed on your system to run these applications. Scala statements can be directly entered on CLI "spark-shell"; however, bundled programs need CLI "spark-submit." These CLIs come with the Windows executables.
Download and Install Spark
Download Spark from https://spark.apache.org/downloads.html and choose "Pre-built for Apache Hadoop 2.7 and later"

Unpack spark-2.3.0-bin-hadoop2.7.tgz in a directory.
Clearing the Startup Hurdles
You may follow the Spark's quick start guide to start your first program. However, it is not that straightforward, andyou will face various issues as listed below, along with their resolutions.
Please note that you must have administrative permission to the user or you need to run command tool as administrator.
Issue 1: Failed to Locate winutils Binary
Even if you don't use Hadoop, Windows needs Hadoop to initialize the "hive" context. You get the following error if Hadoop is not installed.
C:\Installations\spark-2.3.0-bin-hadoop2.7>.\bin\spark-shell
2018-05-28 12:32:44 ERROR Shell:397 - Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:379)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:394)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:387)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:80)
at org.apache.hadoop.security.SecurityUtil.getAuthenticationMethod(SecurityUtil.java:611)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:273)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:261)
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:791)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:761)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:634)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2464)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2464)
at scala.Option.getOrElse(Option.scala:121)This can be fixed by adding a dummy Hadoop installation. Spark expects winutils.exe in the Hadoop installation "<Hadoop Installation Directory>/bin/winutils.exe" (note the "bin" folder).
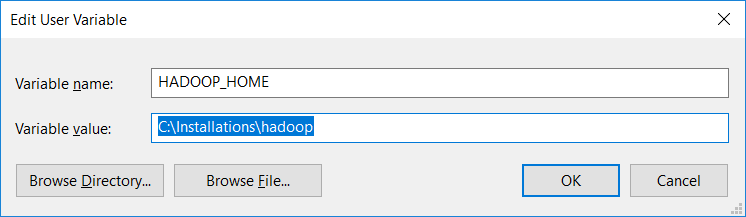
Download Hadoop 2.7's winutils.exe and place it in a directory C:\Installations\Hadoop\bin
Now set HADOOP_HOME = C:\Installations\Hadoop environment variables.
Now start the Windows shell; you may get few warnings, which you may ignore for now.
C:\Installations\spark-2.3.0-bin-hadoop2.7>.\bin\spark-shell
2018-05-28 15:05:08 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://kuldeep.local:4040
Spark context available as 'sc' (master = local[*], app id = local-1527500116728).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.3.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_151)
Type in expressions to have them evaluated.
Type :help for more information.
scala>Issue 2: File Permission Issue for /tmp/hive
Let's run the first program as suggested by Spark's quick start guide. Don't worry about the Scala syntax for now.
scala> val textFile = spark.read.textFile("README.md")
2018-05-28 15:12:13 WARN General:96 - Plugin (Bundle) "org.datanucleus.api.jdo" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/C:/Installations/spark-2.3.0-bin-hadoop2.7/jars/datanucleus-api-jdo-3.2.6.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/C:/Installations/spark-2.3.0-bin-hadoop2.7/bin/../jars/datanucleus-api-jdo-3.2.6.jar."
2018-05-28 15:12:13 WARN General:96 - Plugin (Bundle) "org.datanucleus.store.rdbms" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/C:/Installations/spark-2.3.0-bin-hadoop2.7/bin/../jars/datanucleus-rdbms-3.2.9.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/C:/Installations/spark-2.3.0-bin-hadoop2.7/jars/datanucleus-rdbms-3.2.9.jar."
2018-05-28 15:12:13 WARN General:96 - Plugin (Bundle) "org.datanucleus" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/C:/Installations/spark-2.3.0-bin-hadoop2.7/bin/../jars/datanucleus-core-3.2.10.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/C:/Installations/spark-2.3.0-bin-hadoop2.7/jars/datanucleus-core-3.2.10.jar."
2018-05-28 15:12:17 WARN ObjectStore:6666 - Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
2018-05-28 15:12:18 WARN ObjectStore:568 - Failed to get database default, returning NoSuchObjectException
org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.lang.RuntimeException: The root scratch dir: /tmp/hive on HDFS should be writable. Current permissions are: rw-rw-rw-;
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:106)
at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:194)
at org.apache.spark.sql.internal.SharedState.externalCatalog$lzycompute(SharedState.scala:114)
at org.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:102)
You may ignore plugin's warning for now, but "/tmp/hive on HDFS should be writable" should be fixed.
This can be fixed by changing permissions on "/tmp/hive" (which is C:/tmp/hive) directory using winutils.exe as follows. You may run basic Linux commands on Windows using winutils.exe.
c:\Installations\hadoop\bin>winutils.exe ls \tmp\hive
drw-rw-rw- 1 NAGARRO\kuldeep NAGARRO\Domain Users 0 May 28 2018 \tmp\hive
c:\Installations\hadoop\bin>winutils.exe chmod 777 \tmp\hive
c:\Installations\hadoop\bin>winutils.exe ls \tmp\hive
drwxrwxrwx 1 NAGARRO\kuldeep NAGARRO\Domain Users 0 May 28 2018 \tmp\hive
c:\Installations\hadoop\bin>Issue 3: Failed to Start Database "metastore_db"
If you run the same command " val textFile = spark.read.textFile("README.md") " again you may get following exception :
2018-05-28 15:23:49 ERROR Schema:125 - Failed initialising database.
Unable to open a test connection to the given database. JDBC url = jdbc:derby:;databaseName=metastore_db;create=true, username = APP. Terminating connection pool (set lazyInit to true if you expect to start your database after your app). Original Exception: ------
java.sql.SQLException: Failed to start database 'metastore_db' with class loader org.apache.spark.sql.hive.client.IsolatedClientLoader$$anon$1@34ac72c3, see the next exception for details.
at org.apache.derby.impl.jdbc.SQLExceptionFactory.getSQLException(Unknown Source)
at org.apache.derby.impl.jdbc.SQLExceptionFactory.getSQLException(Unknown Source)
at org.apache.derby.impl.jdbc.Util.seeNextException(Unknown Source)
at org.apache.derby.impl.jdbc.EmbedConnection.bootDatabase(Unknown Source)This can be fixed just be removing the "metastore_db" directory from Windows installation "C:/Installations/spark-2.3.0-bin-hadoop2.7" and running it again.
Run Spark Application on spark-shell
Run your first program as suggested by Spark's quick start guide.
DataSet: 'org.apache.spark.sql.Dataset' is the primary abstraction of Spark. Dataset maintains a distributed collection of items. In the example below, we will create Dataset from a file and perform operations on it.
SparkSession: This is entry point to Spark programming. 'org.apache.spark.sql.SparkSession'.
Start the spark-shell.
C:\Installations\spark-2.3.0-bin-hadoop2.7>.\bin\spark-shell
Spark context available as 'sc' (master = local[*], app id = local-1527500116728).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.3.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_151)
Type in expressions to have them evaluated.
Type :help for more information.
scala>Spark shell initializes a Windowscontext 'sc' and Windowssession named 'spark'. We can get the DataFrameReader from the session which can read a text file, as a DataSet, where each line is read as an item of the dataset. Following Scala commands creates data set named "textFile" and then run operations on dataset such as count() , first() , and filter().
scala> val textFile = spark.read.textFile("README.md")
textFile: org.apache.spark.sql.Dataset[String] = [value: string]
scala> textFile.count()
res0: Long = 103
scala> textFile.first()
res1: String = # Apache Spark
scala> val linesWithSpark = textFile.filter(line => line.contains("Spark"))
linesWithSpark: org.apache.spark.sql.Dataset[String] = [value: string]
scala> textFile.filter(line => line.contains("Spark")).count()
res2: Long = 20Some more operations of map(), reduce(), collect() .
scala> textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b)
res3: Int = 22
scala> val wordCounts = textFile.flatMap(line => line.split(" ")).groupByKey(identity).count()
wordCounts: org.apache.spark.sql.Dataset[(String, Long)] = [value: string, count(1): bigint]
scala> wordCounts.collect()
res4: Array[(String, Long)] = Array((online,1), (graphs,1), (["Parallel,1), (["Building,1), (thread,1), (documentation,3), (command,,2), (abbreviated,1), (overview,1), (rich,1), (set,2), (-DskipTests,1), (name,1), (page](http://spark.apache.org/documentation.html).,1), (["Specifying,1), (stream,1), (run:,1), (not,1), (programs,2), (tests,2), (./dev/run-tests,1), (will,1), ([run,1), (particular,2), (option,1), (Alternatively,,1), (by,1), (must,1), (using,5), (you,4), (MLlib,1), (DataFrames,,1), (variable,1), (Note,1), (core,1), (more,1), (protocols,1), (guidance,2), (shell:,2), (can,7), (site,,1), (systems.,1), (Maven,1), ([building,1), (configure,1), (for,12), (README,1), (Interactive,2), (how,3), ([Configuration,1), (Hive,2), (system,1), (provides,1), (Hadoop-supported,1), (pre-built,1...
scala>Run Spark Application on spark-submit
In the last example, we ran the Windows application as Scala script on 'spark-shell', now we will run a Spark application built in Java. Unlike spark-shell, we need to first create a SparkSession and at the end, the SparkSession must be stopped programmatically.
Look at the below SparkApp.Java it read a text file and then count the number of lines.
package com.korg.spark.test;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.SparkSession;
public class SparkApp {
public static void main(String[] args) {
SparkSession spark = SparkSession.builder().appName("SparkApp").config("spark.master", "local").getOrCreate();
Dataset<String> textFile = spark.read().textFile(args[0]);
System.out.println("Number of lines " + textFile.count());
spark.stop();
}
}
Create above Java file in a Maven project with following pom dependencies :
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.korg.spark.test</groupId>
<artifactId>spark-test</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>SparkTest</name>
<description>SparkTest</description>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.0</version>
</dependency>
</dependencies>
</project>Build the Maven project it will generate jar artifact "target/spark-test-0.0.1-SNAPSHOT.jar"
Now submit this Windows application to Windows as follows: (Excluded some logs for clarity)
C:\Installations\spark-2.3.0-bin-hadoop2.7>.\bin\spark-submit --class "com.korg.spark.test.SparkApp" E:\Workspaces\RnD\spark-test\target\spark-test-0.0.1-SNAPSHOT.jar README.md
2018-05-29 12:59:15 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2018-05-29 12:59:15 INFO SparkContext:54 - Running Spark version 2.3.0
2018-05-29 12:59:15 INFO SparkContext:54 - Submitted application: SparkApp
2018-05-29 12:59:15 INFO SecurityManager:54 - Changing view acls to: kuldeep
2018-05-29 12:59:16 INFO Utils:54 - Successfully started service 'sparkDriver' on port 51471.
2018-05-29 12:59:16 INFO SparkEnv:54 - Registering OutputCommitCoordinator
2018-05-29 12:59:16 INFO log:192 - Logging initialized @7244ms
2018-05-29 12:59:16 INFO Server:346 - jetty-9.3.z-SNAPSHOT
2018-05-29 12:59:16 INFO Server:414 - Started @7323ms
2018-05-29 12:59:17 INFO SparkUI:54 - Bound SparkUI to 0.0.0.0, and started at http://kuldeep.local:4040
2018-05-29 12:59:17 INFO SparkContext:54 - Added JAR file:/E:/Workspaces/RnD/spark-test/target/spark-test-0.0.1-SNAPSHOT.jar at spark://kuldeep.local:51471/jars/spark-test-0.0.1-SNAPSHOT.jar with timestamp 1527578957193
2018-05-29 12:59:17 INFO SharedState:54 - Warehouse path is 'file:/C:/Installations/spark-2.3.0-bin-hadoop2.7/spark-warehouse'.
2018-05-29 12:59:18 INFO StateStoreCoordinatorRef:54 - Registered StateStoreCoordinator endpoint
2018-05-29 12:59:21 INFO FileSourceScanExec:54 - Pushed Filters:
2018-05-29 12:59:21 INFO ContextCleaner:54 - Cleaned accumulator 0
2018-05-29 12:59:22 INFO CodeGenerator:54 - Code generated in 264.159592 ms
2018-05-29 12:59:22 INFO BlockManagerInfo:54 - Added broadcast_0_piece0 in memory on kuldeep425.Nagarro.local:51480 (size: 23.3 KB, free: 366.3 MB)
2018-05-29 12:59:22 INFO SparkContext:54 - Created broadcast 0 from count at SparkApp.java:11
2018-05-29 12:59:22 INFO SparkContext:54 - Starting job: count at SparkApp.java:11
2018-05-29 12:59:22 INFO DAGScheduler:54 - Registering RDD 2 (count at SparkApp.java:11)
2018-05-29 12:59:22 INFO DAGScheduler:54 - Got job 0 (count at SparkApp.java:11) with 1 output partitions
2018-05-29 12:59:22 INFO Executor:54 - Fetching spark://kuldeep.local:51471/jars/spark-test-0.0.1-SNAPSHOT.jar with timestamp 1527578957193
2018-05-29 12:59:23 INFO TransportClientFactory:267 - Successfully created connection to kuldeep425.Nagarro.local/10.0.75.1:51471 after 33 ms (0 ms spent in bootstraps)
2018-05-29 12:59:23 INFO Utils:54 - Fetching spark://kuldeep.local:51471/jars/spark-test-0.0.1-SNAPSHOT.jar to C:\Users\kuldeep\AppData\Local\Temp\spark-5a3ddefe-e64c-4730-8800-9442ad72bdd1\userFiles-0b51b538-6f4d-4ddd-85c1-4595749c09ea\fetchFileTemp210545020631632357.tmp
2018-05-29 12:59:23 INFO Executor:54 - Adding file:/C:/Users/kuldeep/AppData/Local/Temp/spark-5a3ddefe-e64c-4730-8800-9442ad72bdd1/userFiles-0b51b538-6f4d-4ddd-85c1-4595749c09ea/spark-test-0.0.1-SNAPSHOT.jar to class loader
2018-05-29 12:59:23 INFO FileScanRDD:54 - Reading File path: file:///C:/Installations/spark-2.3.0-bin-hadoop2.7/README.md, range: 0-3809, partition values: [empty row]
2018-05-29 12:59:23 INFO CodeGenerator:54 - Code generated in 10.064959 ms
2018-05-29 12:59:23 INFO Executor:54 - Finished task 0.0 in stage 0.0 (TID 0). 1643 bytes result sent to driver
2018-05-29 12:59:23 INFO TaskSetManager:54 - Finished task 0.0 in stage 0.0 (TID 0) in 466 ms on localhost (executor driver) (1/1)
2018-05-29 12:59:23 INFO TaskSchedulerImpl:54 - Removed TaskSet 0.0, whose tasks have all completed, from pool
2018-05-29 12:59:23 INFO DAGScheduler:54 - ShuffleMapStage 0 (count at SparkApp.java:11) finished in 0.569 s
2018-05-29 12:59:23 INFO DAGScheduler:54 - ResultStage 1 (count at SparkApp.java:11) finished in 0.127 s
2018-05-29 12:59:23 INFO TaskSchedulerImpl:54 - Removed TaskSet 1.0, whose tasks have all completed, from pool
2018-05-29 12:59:23 INFO DAGScheduler:54 - Job 0 finished: count at SparkApp.java:11, took 0.792077 s
Number of lines 103
2018-05-29 12:59:23 INFO AbstractConnector:318 - Stopped Spark@63405b0d{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
2018-05-29 12:59:23 INFO SparkUI:54 - Stopped Spark web UI at http://kuldeep.local:4040
2018-05-29 12:59:23 INFO MapOutputTrackerMasterEndpoint:54 - MapOutputTrackerMasterEndpoint stopped!
2018-05-29 12:59:23 INFO BlockManager:54 - BlockManager stopped
2018-05-29 12:59:23 INFO BlockManagerMaster:54 - BlockManagerMaster stopped
Congratulations! You are done with your first Windows application on Windows environment.
In the next article, we will talk about Spark's distributed caching and how it works with real-world examples in Java. Happy Learning!
Opinions expressed by DZone contributors are their own.
Comments