Writing to a CSV File From Multiple Threads
We look at how to write metadata to CSV files from multiple threads in parallel using concurrent queues.
Join the DZone community and get the full member experience.
Join For FreeI was writing document and metadata exporter that reads data from SharePoint and writes it to multiple files. I needed to boost up performance of my exporter and I went with multiple threads pumping out the data from SharePoint. One problem I faced — writing metadata to CSV files from multiple threads in parallel. This blog post shows how to do it using concurrent queues.
This posting uses CsvHelper library to write objects to CSV-files. Last time I covered this library in my blog post Generating CSV-files on .NET.
Problem: Writing to a File From Multiple Threads
I have multiple threads that traverse a document library on SharePoint and I need to generate some reports on the fly. I have no option to add data to some buffer and flush it to files at the end of the project as the server memory is limited.
What I need is some thread-safe list I can read from another thread and where worker threads can add their DTOs.
I had some considerations:
- I don't want to bind the code too tight to some logging framework that can do the job.
- I need some point in the code where I can control the reading and writing of data.
- Instead of primitive custom code with thread locking I prefer something provided by a framework.
With these ideas in mind I started building my solution.
Using ConcurrentQueue<T>
I solved the problem using ConcurrentQueue<T>. Threads that gather data from the SharePoint document library add Data Transfer Objects (DTOs) to a concurrent queue. Now I don't have to worry about threading issues, which is why concurrent queues were created. I also added a thread that reads from a concurrent queue and writes DTOs to a CSV file.
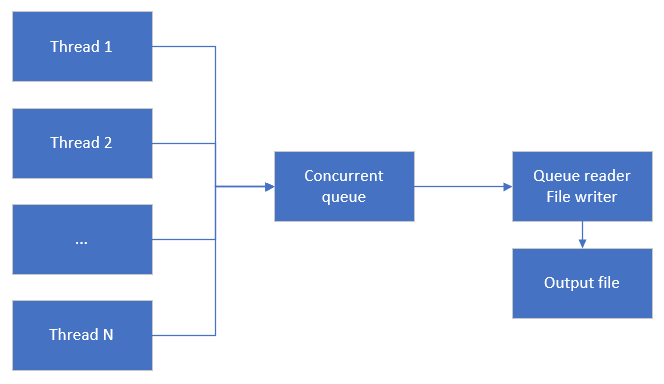
I wrote an example console application to illustrate my solution. It's easy to try out. Sorry for messy code.
class Product
{
public int Id { get; set; }
public string Name { get; set; }
public double Price { get; set; }
}
class Program
{
private static ConcurrentQueue<Product> _products = new ConcurrentQueue<Product>();
static void Main(string[] args)
{
var source = new CancellationTokenSource();
var token = source.Token;
Task.Run(() => {
var conf = new Configuration();
conf.Encoding = Encoding.UTF8;
conf.CultureInfo = CultureInfo.InvariantCulture;
using (var stream = File.OpenWrite("products.txt"))
using (var streamWriter = new StreamWriter(stream))
using (var writer = new CsvWriter(streamWriter, conf))
{
writer.WriteHeader<Product>();
writer.NextRecord();
while (true)
{
if(token.IsCancellationRequested)
{
streamWriter.Flush();
return;
}
Product product = null;
while(_products.TryDequeue(out product))
{
writer.WriteRecord(product);
writer.NextRecord();
}
}
}
}, token);
var task1 = Task.Run(() =>
{
foreach(var number in Enumerable.Range(1, 10))
{
var product = new Product
{
Id = number,
Name = "Product " + number,
Price = Math.Round((10d * number) / DateTime.Now.Second, 2)
};
_products.Enqueue(product);
Task.Delay(150).Wait();
}
});
var task2 = Task.Run(() =>
{
foreach (var number in Enumerable.Range(11, 10))
{
var product = new Product
{
Id = number,
Name = "Product " + number,
Price = Math.Round((10d * number) / DateTime.Now.Second, 2)
};
_products.Enqueue(product);
Task.Delay(150).Wait();
}
});
Task.WaitAll(task1, task2);
Console.WriteLine(Environment.NewLine);
Console.WriteLine("Press any key to exit ...");
Console.ReadKey();
source.Cancel();
}
}This code does its job well in my case. Here's the CSV file with the product information.

Although I went with default settings it's easy to configure CsvWriter to use the settings one needs.
What if SpinWait Is too Agressive?
Some of my dear readers might point out one thing — isn't a concurrent queue reading too aggressive? Well, there's no better answer than the usual "it depends." Internally, ConcurrentQueue<T> uses SpinWait and this should be enough in my case. Still, when it runs empty it consumes 25% of CPU. SpinWait is okay when items are added to the queue frequently.
If SpinWait in the concurrent queue is too agressive then it's possible to calm it down a little bit when the queue is empty. I added a 500 millisecond delay.
Task.Run(async () => {
var conf = new Configuration();
conf.Encoding = Encoding.UTF8;
conf.CultureInfo = CultureInfo.InvariantCulture;
using (var stream = File.OpenWrite("products.txt"))
using (var streamWriter = new StreamWriter(stream))
using (var writer = new CsvWriter(streamWriter, conf))
{
writer.WriteHeader<Product>();
writer.NextRecord();
while (true)
{
if(token.IsCancellationRequested)
{
streamWriter.Flush();
return;
}
Product product = null;
while(_products.TryDequeue(out product))
{
writer.WriteRecord(product);
writer.NextRecord();
}
// No data, let's delay
await Task.Delay(500);
}
}
}, token);In my case. this calmed the concurrent queue reading down. Instead on 25% of tge CPU it stays near 3% when the concurrent queue is empty.
Wrapping Up
Instead of inventing custom mechanisms to handle concurrent writes to a file from multiple threads we can use already existing classes and components. CsvHelper is great library with excellent performance. The ConcurrentQueue<T> class helped us to take control of file writing to tune the CPU usage during data exports. In the end we have simple and easy to extend solution we can also use in other projects.
Published at DZone with permission of Gunnar Peipman. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments