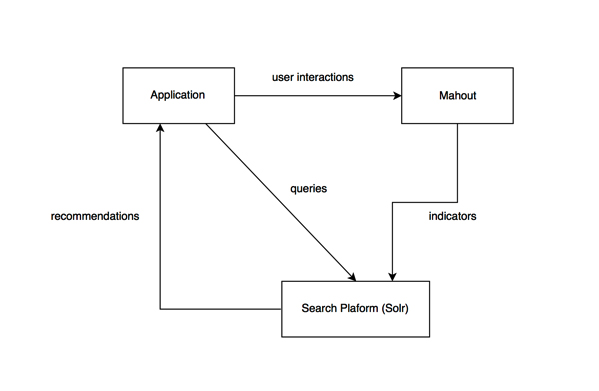
In the following example, we will use Spark as part of a system to generate recommendations for different restaurants. The recommendations for a potential diner are constructed from this formula:
recommendations_for_user = [V'V] * historical_visits_from_user
Here, V is the matrix of restaurant visits for all users and V' is the transpose of that matrix. [V'V] can be replaced with a co-occurrence matrix calculated with a log-likelihood ratio, which determines the strength of the similarity of rows and columns (and thus be able to pick out restaurants that other similar users have liked).
Example User / Restaurant Data (saved as restlog.csv)
| UserID |
Action |
Restaurant |
| user001 |
like |
Sage |
| user001 |
dislike |
Al’s_Pancake_World |
| user002 |
like |
Al’s_Pancake_World |
| user002 |
like |
Dot’s_Café |
| user002 |
like |
Waffles_And_Things |
| user003 |
dislike |
Al’s_Pancake_World |
| user003 |
like |
Sage |
| user003 |
like |
Emerald |
| user003 |
neutral |
Bugsy's |
| user004 |
like |
Bugsy's |
| user004 |
like |
Al’s_Pancake_World |
| user004 |
dislike |
Sage |
To compute the co-occurrence matrix, we issue this command:
$ MAHOUT_ROOT/bin/mahout spark-itemsimilarity
-i restlog.csv -rc 0 -ic 2 -fc 1 --filter1 like -o rec_matrix
This selects the spark-itemsimilarity module, giving input via a filename passed into the “-i" parameter (directories and HDFS URIs are also supported here). The “-rc” parameter indicates the row column of the matrix (in this case, the userID and column 0) and the -ic parameter is the column in which Mahout can find our item/restaurant. As we are attempting to find similar “liked” restaurants, we add a filter by firstly using the -fc option to tell Mahout to filter on column 1 in the .csv file, and then by using --filter1 to provide the text we are matching against (this can also be a regular expression, and up to two filters can be applied in this operation). Finally, the -o is for output, and again can be a file, directory, or HDFS URI.
Running the command produces this output:
Dot's_Café
Waffles_And_Things:4.498681156950466 Al's_Pancake_World:1.7260924347106847 Sage
Emerald:1.7260924347106847 Waffles_And_Things
Dot's_Café:4.498681156950466 Al's_Pancake_World:1.7260924347106847 Bugsy's
Al's_Pancake_World:1.7260924347106847 Emerald
Sage:1.7260924347106847 Al's_Pancake_World
Dot's_Café:1.7260924347106847 Waffles_And_Things:1.7260924347106847 Bugsy's:1.7260924347106847
Each line is a row of the collapsed similarity matrix. We can run the command with the --omitStrength parameter if we are just interested in a recommendation without ranking. We can see that users who like Dot's Café will likely also enjoy Waffles and Things (and to a lesser degree, Al's Pancake World).
This approach can be used in a real-time setting by feeding the matrix data into a search platform (e.g. Solr or ElasticSearch). The Spark-Mahout algorithm can compute co-occurrences from user interactions and update the search engine's indicators, which are then fed back into the application, providing a feedback loop.