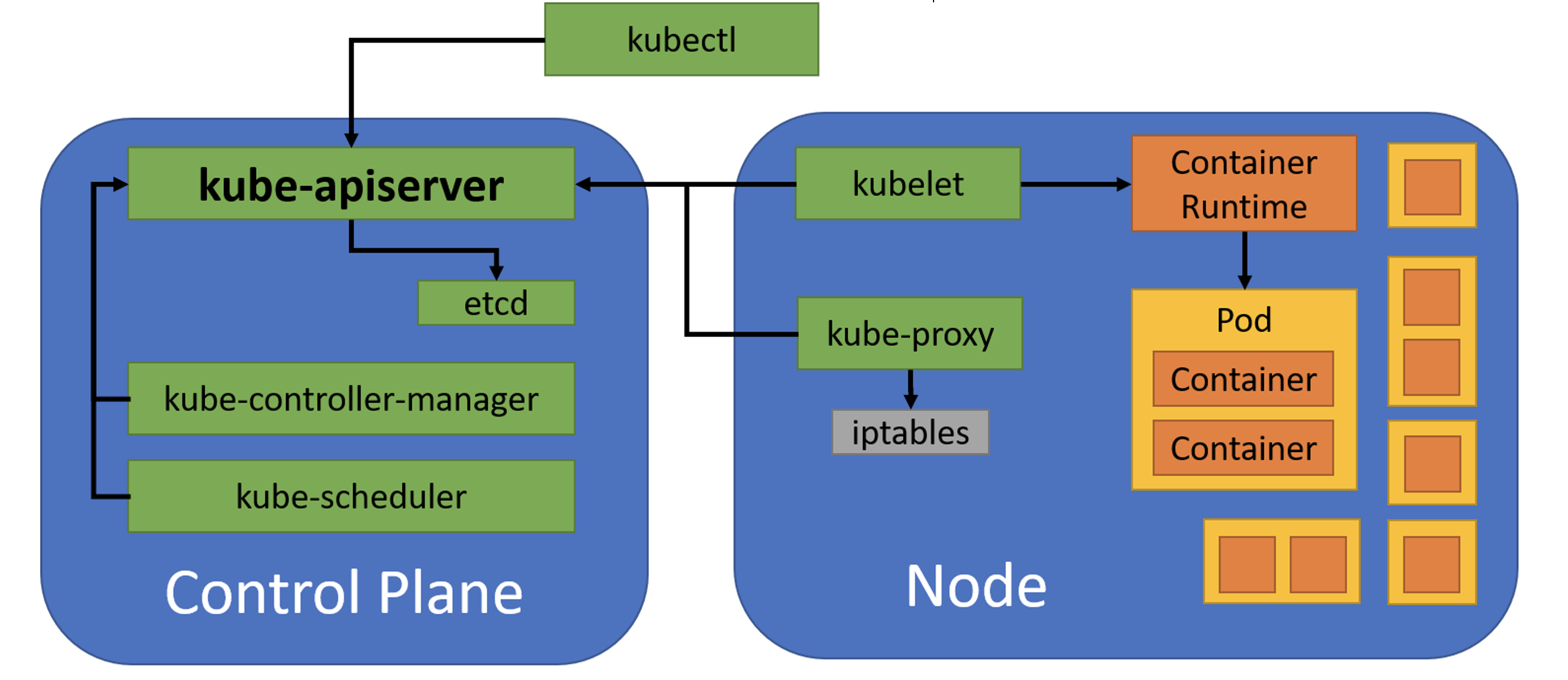
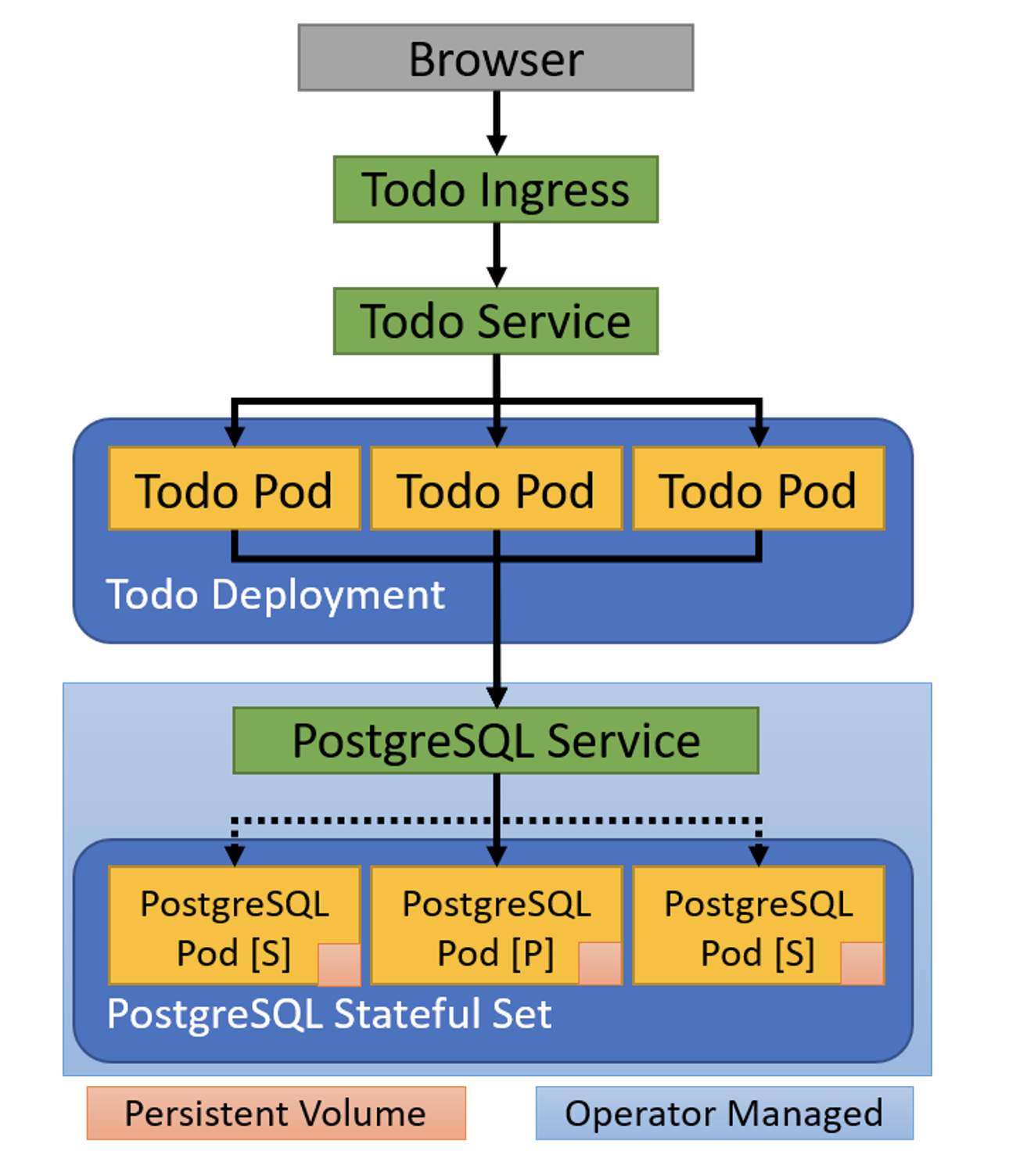
Because Kubernetes is declarative, getting started in Kubernetes mostly means understanding what resources we can create and how they are used to deploy and configure containers in the cluster. To define resources, we use YAML format. The available resources and fields for each resource may change with new Kubernetes versions, so it’s important to double-check the API reference for your version to know what’s available. It’s also important to use the correct apiVersion on each resource to match your version of Kubernetes. This Refcard uses the API from Kubernetes 1.24, released May 2022, but all resources shown are backwards compatible through Kubernetes 1.19. Lastly, the examples featured in this Refcard are available in the associated GitHub repository.
Pod
A Pod is a group of one or more containers. Kubernetes will schedule all containers for a Pod into the same host, with the same network namespace, so they all have the same IP address and can access each other using localhost. The containers in a Pod can also share storage volumes.
We don’t typically create Pod resources directly. Instead, we have Kubernetes manage them through a controller such as a Deployment or StatefulSet. Controllers provide fault tolerance, scalability, and rolling updates.
Deployment
A Deployment manages one or more identical Pod instances. Kubernetes will make sure that the specified number of Pods is running, and on a rolling update, it will replace Pod instances gradually, allowing for application updates with zero downtime. Here is an example Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.23.1-alpine
volumeMounts:
- mountPath: /usr/share/nginx
name: www-data
readOnly: true
resources:
requests:
memory: "128Mi"
cpu: "50m"
limits:
memory: "128Mi"
cpu: "50m"
initContainers:
- name: git-clone
image: alpine/git
args:
- "clone"
- "https://github.com/book-of-kubernetes/hello-world-static"
- "/www/html"
volumeMounts:
- mountPath: /www
name: www-data
volumes:
- name: www-data
emptyDir: {}
The apiVersion and kind uniquely identify the type of the resource. Deployments are in the apps API group, and here, we are specifying v1 as the version. As a result, Kubernetes knows what fields to expect in the rest of the YAML specification.
For a controller such as a Deployment, the template section specifies exactly what the created Pods should look like. Kubernetes will automatically create three Pods per the replicas field using this template. Kubernetes will monitor these Pods and automatically restart them if the container terminates. Deployments use the matchLabels selector field to determine which Pods to manage. This field must always have the same data as the metadata.labels field inside the template. The Deployment will take ownership of any running Pods that match the matchLabels selector, even if they were created separately, so keep these names unique.
The example above defines one container in the Pod and additionally defines an initContainer. The initContainer runs before the main Pod container starts. In this case, it uses Git to populate a directory. Because this directory is part of a single volume that is specified as a volumeMount in both containers, the resulting files are also mounted into the main container to be served by NGINX. This example uses an initContainer to run Git because Git runs and then exits; if Git was run as a second regular container in the Pod, Kubernetes would interpret this as a container failure and restart the Pod.
Finally, we specify requests and limits for our main container. Kubernetes uses these to ensure that each node in the cluster has enough capacity for its deployed Pods. Requests and limits are also used with quotas so that different applications and users in a multi-tenant cluster don’t interfere with each other. It is good practice to identify the resource needs of each container in a Pod and apply limits.
StatefulSet
Each new Pod in the above Deployment starts with an empty directory, but what about cases where we need real persistent storage? The StatefulSet also manages multiple Pods, but each Pod is associated with its own unique storage, and that storage is kept when the Pod is replaced.
Here is an example StatefulSet:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: postgres
spec:
serviceName: postgres
replicas: 2
selector:
matchLabels:
app: postgres
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres
env:
- name: POSTGRES_PASSWORD
value: "supersecret"
- name: PGDATA
value: /data/pgdata
volumeMounts:
- name: postgres-volume
mountPath: /data
volumeClaimTemplates:
- metadata:
name: postgres-volume
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
Like a Deployment, a StatefulSet is in the apps API group, uses a selector to discover its Pods, and uses a template to create those Pods. However, a StatefulSet also has a volumeClaimTemplates section that specifies the persistent storage provided to each Pod.
When this StatefulSet is created, it will create two Pods: postgres-0 and postgres-1. Each Pod will have associated persistent storage. If a Pod is replaced, the new Pod will have the same name and be attached to the same storage. Each of these Pods will be discoverable within the cluster using the combination of the Pod name and the serviceName. The identified Service must already exist; see below for more information about Services and see the GitHub repository for the full example.
The env field is one way to provide environment variables to containers. The PGDATA variable tells PostgreSQL where to store its database files, so we ensure those are placed on the persistent volume. We also specify the POSTGRES_PASSWORD directly; in a production application, we would use a Secret as described below.
The StatefulSet is one important resource needed to deploy a highly available PostgreSQL database server. We also need a way for the instances to find each other and a way to configure clients to find the current primary instance. In the application example below, we use a Kubernetes Operator to accomplish this automatically.
Service
A Service provides network load balancing to a group of Pods. Every time Kubernetes creates a Pod, it assigns it a unique IP address. When a Pod is replaced, the new Pod receives a new IP. By declaring a Service, we can provide a single point of entry for all the Pods in a Deployment. This single point of entry (hostname and IP address) remains valid as Pods come and go. The Kubernetes cluster even provides a DNS server so that we can use Service names as regular hostnames. Here is the Service that matches our NGINX Deployment above:
kind: Service
apiVersion: v1
metadata:
name: nginx
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
Unlike the Deployment and StatefulSet, the Service is in the “core” API group, so we only need to specify the apiVersion as v1. Like the Deployment and StatefulSet we saw above, the Service uses the selector field to discover its Pods, so it automatically stays up to date. For this reason, Services can be created before the Pods exist; this demonstrates an important advantage of the declarative Kubernetes approach.
Services rely on Kubernetes to provide a unique IP address and route traffic, so the way Services are configured can be different depending on how your Kubernetes installation is configured. The most common type of Service is ClusterIP, which is also the default. ClusterIP means the Service has an IP address accessible only from within the Kubernetes cluster, so exposing the Service outside the cluster requires another resource such as an Ingress.
It’s important to know that when network traffic is sent to a Service address and port, Kubernetes uses port forwarding to route traffic to a specific Pod. Only the declared ports are forwarded, so other kinds of traffic (like ICMP ping) will not work to communicate with a Service address, even within the cluster.
Ingress
An Ingress is one approach for routing HTTP traffic from outside the cluster. (An alternate and more advanced approach is a service mesh such as Istio.) To use an Ingress, a cluster administrator first deploys an “ingress controller”. This is a regular Kubernetes Deployment, but it registers with the Kubernetes cluster to be notified when an Ingress resource is created, updated, or deleted. It then configures itself to route HTTP traffic based on the Ingress resources.
The advantage of this approach is that only the ingress controller needs an IP address that is reachable from outside the cluster, simplifying configuration and potentially saving money.
Here is the Ingress example to go with the NGINX Deployment and Service:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nginx
spec:
rules:
- http:
paths:
- path: /
PathType: Prefix
backend:
service:
name: nginx
port:
number: 80
This example routes all traffic in the cluster to a single Service, so it is only useful for a sandbox. In a production cluster, you can use DNS wildcards to route all hostnames in a domain to the ingress controller’s IP address, and then use host rules to route each host’s traffic to the correct application.
PersistentVolumeClaim
The StatefulSet example above tells Kubernetes to create and manage persistent storage for us. We can also create persistent storage directly using a PersistentVolumeClaim.
A PersistentVolumeClaim requests Kubernetes to dynamically allocate storage from a StorageClass. The StorageClass is typically created by the administrator of the Kubernetes cluster and must already exist. Once the PersistentVolumeClaim is created, it can be attached to a Pod by declaring it in the volumes field. Kubernetes will keep the storage while the PersistentVolumeClaim exists, even if the attached Pod is deleted.
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: web-static-files
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 8Gi
For more information on the available providers for Kubernetes storage classes, and for multiple examples on configuring persistent storage, see the DZone Refcard Persistent Container Storage.
ConfigMap and Secret
In the StatefulSet example above, we specified environment variables directly in the env field. A better approach is to externalize the configuration into a separate ConfigMap or Secret. Both these resources work similarly and can be used to provide either environment variables or file content to containers. The major difference is that a Secret is base-64 encoded to simplify storage of binary content; additionally, as these are separate resources it is possible to configure cluster authorization separately so access to Secrets can be more limited.
To externalize our PostgreSQL environment variables, we’ll use both a ConfigMap and a Secret. First, the ConfigMap:
---
kind: ConfigMap
apiVersion: v1
metadata:
name: pgsql
data:
PGDATA: /data/pgdata
Then, the Secret:
---
kind: Secret
apiVersion: v1
metadata:
name: pgsql
stringData:
POSTGRES_PASSWORD: supersecret
Besides the kind, the one difference is that we use stringData with the Secret to tell Kubernetes to do the base-64 encoding for us.
To use these externalized environment variables, we replace the env field of the StatefulSet with the following:
envFrom:
- configMapRef:
name: pgsql
- secretRef:
name: pgsql
Each of the key-value pairs in the ConfigMap and Secret will be turned into environment variables for the PostgreSQL server running in the container.
Kustomize, Helm, and Operators
Managing all of these different types of resources becomes challenging, even with the ability to externalize configuration using ConfigMap and Secret. Most application components require multiple resources for deployment and often need different configuration for different environments, such as development and production. The Kubernetes ecosystem has a rich set of tools to simplify managing resources:
- Kustomize is built into Kubernetes itself. It supports applying patches to a set of base YAML resource files. The base file can contain default values, while the patches tailor the deployment to a different environment.
- Helm is a separate tool that brings templates to YAML resource files. A set of templated resources, known as a Helm chart, can be uploaded to a registry and easily used in many different clusters, with the ability to easily tailor each individual deployment by supplying a set of variables in a YAML file.
- Operators are a Kubernetes design pattern rather than a single tool. An operator runs in the Kubernetes cluster and registers a
CustomResourceDefinition (CRD). It watches the cluster for instances of that custom resource and updates the cluster accordingly. The example application below demonstrates the use of the “Postgres Operator” to rapidly deploy a highly available PostgreSQL database server.