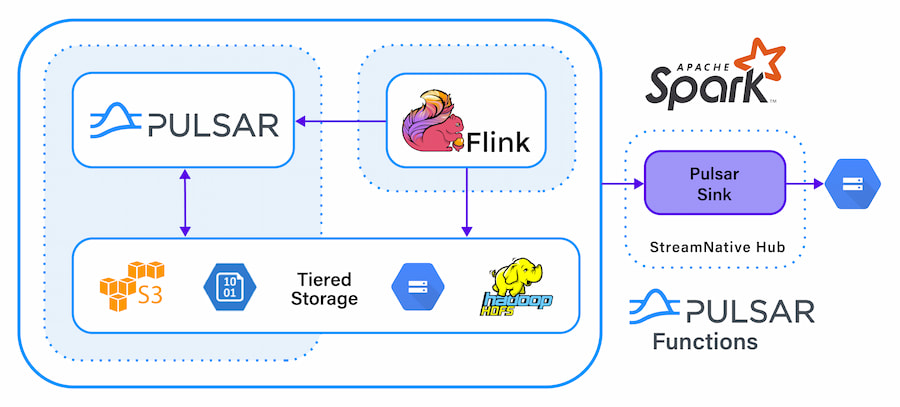
For advanced IoT solutions, we need a unified messaging and data infrastructure that can handle all the needs of a modern enterprise that is running IoT applications. In Figure 1, we can see an example of such a system that is built on scalable open-source projects that can support messaging, streaming, and all the data needs of IoT systems.
Figure 1
Messaging Infrastructure Needs
A unified platform that supports IoT messaging needs to support MQTT and multiple streaming protocols. It must be able to handle past, current, and future needs as more devices are brought into solutions. These devices will have updated operating systems, languages, networks, protocols, and data types that require dynamic IoT platforms. These unified IoT messaging platforms will need to allow for extension, frequent updates, and diverse libraries to support the constantly changing and expanding ecosystem.
There are a few key requirements for this infrastructure:
- Low latency
- Flexibility
- Multiple protocol support
- Resiliency
- Geo-replication
- Multi-tenancy
- Data smoothing
- Infinite scalability
Low Latency
In IoT, there are numerous common patterns formed around different edge use cases. For sensors, we often have a continuous stream of small events with little variation. We need the ability to configure for low latency with the option to drop messages for performance since they are mostly duplicates and we only care about the current state. A common pattern is to take samples, averages, or work against aggregates over a short time window. This can often be achieved further down the data chain in data processing via SQL.
Flexibility
A very important feature that is a minimum requirement for this IoT messaging infrastructure is support for flexibility. This flexibility is multifaceted as the system needs to allow for configurations to change important features such as persistence, message deduplication, protocol additions, storage types, replication types, and more. This may be the most important feature for IoT versus IT systems, with new vendors, devices, and requirements being added for almost every new application or use case.
New devices, sensors, networks, and data types appear from a heterogeneous group of IoT hardware vendors — we need our solution to support, adapt, and work with all of these when they become available. This can be difficult and requires our messaging infrastructure to support multiple protocols, libraries, languages, operating systems, and data subscription types. Our system will also have to be open source to allow anyone to easily extend any piece of the infrastructure for when unique hardware requires something that doesn't fit into any of our existing pathways. This flexibility is something that can be found only in open-source platforms designed to grow and change.
If you don't have the flexibility to meet new requirements based on these new devices, your system will not meet your needs. This could happen at any time. Change is the only constant in the world of IoT — be prepared.
Multiple Protocol Support
A corollary to flexibility is the support for multiple messaging protocols since no one protocol fits every device, problem, system, or language. MQTT is a common protocol, but many others can be used or requested. We need to also support protocols such as web sockets, HTTP, AMQP, and Kafka's binary messaging protocol over TCP/IP.
Resiliency
Most infrastructures for messaging are designed for some level of resiliency within some percentage of tolerance and that works fine for most use cases. This will not be adequate for IoT as workload changes, bad data, and sudden changes to networking, power, scale, demand, and data quality are to be expected. The modern IoT messaging system must bend but never break to these bursts of data and problems. Along with resiliency, our system must scale to any size required by the applications in question. With IoT, this can start with dozens of devices but then scale to millions in very minimal time. We must not set a fixed or upper limit on how large our clusters, applications, or data can be. We must scale to meet these challenges.
We also need resiliency to survive when IoT devices get hacked or have issues. We need to support as many security paradigms, protocols, and options as feasible. At a minimum, we must enable full end-to-end encryption, full SSL, or HTTPS-encrypted channels. As for encrypted payloads, these will still handle millions of messages with low latency and fast throughput. We also need to provide logging, metrics, APIs, feeds, and dashboards to help identify and prevent hacks or attacks. The system should allow for machine learning models to be deployed against queues and topics dynamically to intercept hacked messages or intrusion attempts. Security should never be an afterthought when real-time systems interacting with devices and hardware are involved.
Geo-Replication
Distributed edge computing is a fancy way of saying that we will have our IoT devices deployed and running in multiple areas in the physical and networking world. This requirement to get data to where it needs to be analyzed, transformed, enriched, processed, and stored is a key factor in choosing the right messaging platform for your use case. To achieve this, one important and required feature is support within the platform for geo-replication between clusters, networks, availability zones, and clouds. This will often require active-active two-way replication of data, definitions, and code. Our solution has no choice but to support this data routing at scale.
As users of IoT expand, they quickly start deploying across new cloud regions, states, countries, continents, and even space. We need to be able to get data around the globe and often duplicate it to primary regions for aggregations. Our messaging infrastructure needs to be able to geo-replicate messaging data without requiring new installations, closed-source additions, or coding. The system will need to replicate via configuration and allow for any number of clusters to communicate in both active-active and active-passive methods. This is not without difficulty and will require full knowledge of the systems, clouds, and security needed for all regions. Again, this is something that can only be achieved with open source.
Multi-Tenancy
If we only had one IoT application, use case, company, or group working with the system, then things would be easy, but this is not the case. We will have many groups, applications, and often companies sharing one system. We require secure multi-tenancy to allow for independent IoT applications to share one conduit for affordability, ease of use, and scale.
Data Smoothing
In some edge cases, all the data sent is time series data that needs to be captured for each time point — this could arrive out of sequence and the messaging system needs to be able to handle this. In messaging systems like Kafka or Pulsar, you may want to handle this as an exactly once messaging system so that nothing is duplicated or lost before it lands in durable permanent storage, such as an AWS S3-backed data lake. The advantage of modern data streaming systems is that missing data can be resent, waited on, or interpolated based on previous data streams. This is often done by utilizing machine learning algorithms such as Facebook's Prophet library.
Infinite Scalability
Often in IoT, we need to rapidly scale up for short periods of time and then scale down, such as for temporary use cases like deployments of many sensors at sporting events. In some instances, we may need this to happen with no notice and on demand. The ability to do this scaling without tremendous expense, difficulty, or damaging performance is a feature required by the needed infrastructure. This can often be done by using a messaging platform that runs natively on Kubernetes and has separate compute and storage of messaging.
IoT workloads can happen in large bursts as thousands of devices in the field can become active at once in, say, energy meters, and we need to be able to survive these bursts. These bursts should drive intelligent scaling, and where delays occur to infrastructure availability, we must be able to provide caching, tiered storage, and back pressure to never break in the face of massive torrents of device data. We also need to cleanly shut down and remove extra brokers when the storm has subsided, and we can reduce our infrastructure costs cleanly and intelligently.
We have gone through a very tall order on what this magical, scalable messaging system must do. Fortunately, there are open-source options that you can investigate today for your edge use cases.
Data Infrastructure Requirements
A new but important part of building IoT solutions is a modern data infrastructure that supports all the analytical and data processing needs of enterprises today. In the past, there was a great disconnect between how IoT systems data was handled and that of the rest of the IT data assets. This disconnect was driven by the differences in infrastructure used by IoT and other use cases. With a modern unified messaging infrastructure bridging the gap between systems, we no longer face those differences. Therefore, we must now update what systems our IoT data is fed into and how.
In the modern unified data infrastructure required for all use cases, including IoT, we must support some basic tenants.
Dynamic Scalability
A key factor in handling the diverse workloads and bursty nature of IoT events is the support for dynamic scalability. This usually requires that the messaging system runs on Kubernetes and allows for scaling up and down based on metrics and workloads.
Continuous IoT Data Access
As soon as each event from any device enters the messaging system, we need to be able to get access to it immediately. This allows us to run aggregates and check for alerting conditions. This is often achieved with a real-time data-processing streaming engine, such as Apache Flink, connected to the event stream. This goes with the standard requirements of robust library support for all the modern open-source data libraries such as Apache Spark, Apache NiFi, Apache Flink, and others. We also would want robust support by cloud data processing like Decodable.
SQL Access to Live Data
Along with continuous data access via a programmatic or API, we need to allow analysts and developers to utilize SQL to access these live data streams as each event enters the system. This allows for aggregates, condition checks, and joining streams. This may be the most important feature of a modern messaging system to support IoT. Without SQL, the learning curve may reduce adoption within the enterprise.
Observability
If the events don't arrive, the system slows down, or things go offline, we must know not only instantly but also preemptively that things are starting to go astray. A smart observability system will trigger scaling, alerts, and other actions to notify administrators and possibly stop potential data losses. This is often added as an afterthought, but it can be critical. We also need to be able to replay, fill in missing data, or have data rerun.
Support for Modern Cloud Data Stores and Tools
Our IoT events must stream to any of the cloud data stores that we need it to. This may be as simple as a cloud object store like AWS S3 or Apache Pinot — or as advanced as a real database — and is a minimum requirement that cannot be skipped. We need our IoT events to be in the same database as all our other main data warehouse datasets. We need to support open data formats like Apache Parquet, JSON, and Apache AVRO.
Hybrid Cloud Support
Finally, we need to be able to run our messaging architecture across various infrastructure hosting locations, including on-premises and multiple public clouds. The ability to be installed, run anywhere, and propagate messages is key.


