State, memory, and security produce the most production incidents in agent systems, and are the most commonly deferred until after launch. The decisions in this section affect your testing strategy, deployment model, and incident response when something goes wrong.
Short-Term vs. Long-Term Memory
Memory in an agent system means two things: where information lives between steps right now, and whether it survives the session. Too little persistence and the agent cannot complete multi-turn tasks; too much and you carry compliance risk and retrieval latency you did not plan for.
Short-term memory stores in the context window or a TTL-keyed store, and it is the right default for most tasks. Do not reach for long-term memory until you have a concrete reason to, at which point more than a database is required. You need a schema, indexing strategy, retrieval mechanism, deletion path, and retention policy reviewed with your legal team before you write the first row.
The table below summarizes when to use each type and which backends fit each scope.
| Aspect |
Short-Term Memory |
Long-Term Memory |
| Scope |
Current session only |
Cross-session, durable |
| Best for |
Single-turn and multi-step tasks in one session |
User preferences, past decisions, semantic retrieval |
| Cleared when |
Session ends |
Explicit deletion or policy |
| Key requirement |
TTL or window management |
Schema, indexing, retention policy, deletion path |
| Example tools |
Redis with TTL, LangGraph checkpoints, or in-memory dict |
Vector store such as Chroma |
Checkpointing Long-Running Tasks
An agent running a 20-step task can fail at step 14. Without a checkpoint, the entire job restarts, burning tokens and quota on work already done. Write agent state to a durable store after each significant step, tagged with a step identifier and timestamp. On restart, load the latest checkpoint and continue from there.
The Six Threats Specific to Agent Systems
Agents process content from the outside world and act on it, creating an attack surface that standard security checklists do not fully address. The following six threats require specific mitigations at the architecture level.
| Threat |
How it Happens |
What to Do |
| Prompt injection |
Hostile content in tool output rewrites agent’s planned action |
Treat all external content as untrusted; sanitize before it enters the context window |
| Tool abuse |
Agent calls tool with wrong arguments or fires far more than expected |
Validate arguments against a strict schema; enforce step and call budgets per run |
| Data exfiltration |
Agent leaks sensitive data through output or external API calls |
Apply output filtering before responses leave; enforce network egress allowlists on containers |
| Privilege escalation |
Agent accesses tool or resource outside its assigned role |
Use explicit per-role allowlists at runtime, not denylists; audit every tool call |
| Runaway execution |
Agent loops indefinitely or fires hundreds of tool calls |
Set hard limits on steps, tokens, and wall-clock time; return an error, not a continuation |
| LLM-generated code |
Agent executes code that may access unintended resources |
Sandbox all generated code with no network access and a read-only filesystem |
Implementing Configurable Agent Guardrails
Guardrails enforced at the platform layer cannot be reached by attacks that can subvert prompt-level instructions. Each agent role needs a declarative, version-controlled allowlist specifying which tools it can call, which data it can read, and which arguments it can pass. Enforcement happens at runtime, below the agent logic, so the system cannot exceed its mandate, even if its instructions are tampered with.
Human-in-the-Loop Gates
Deleting records, sending messages outside the organization, triggering payments, and making infrastructure changes all require human confirmation before execution. Build gates as named, explicit objects in your system that are straightforward to add and impossible to bypass accidentally. Log every gate trigger, approval, rejection, and the time each decision took.
Security Layers
Security in an agent system is a stack of independent layers, each failing separately. A compromise in one layer should not grant access to the capabilities controlled by the layers above it.
Figure 3: Security layers
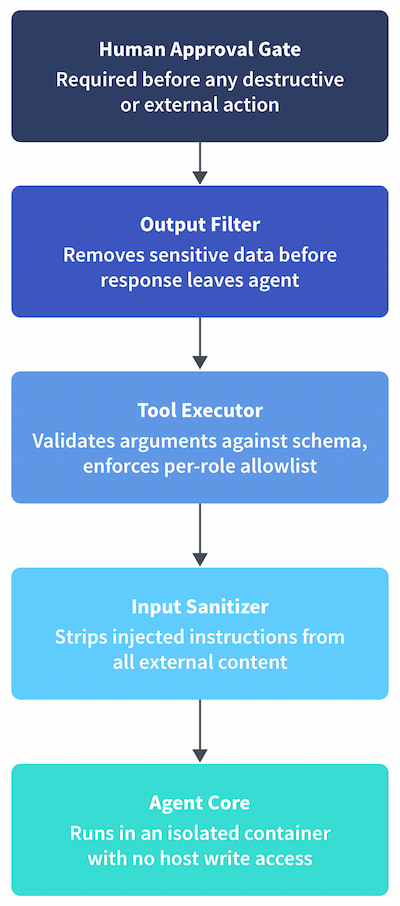
Each layer is enforced independently. A bypass in one does not open the others.
Human-in-the-loop gates are not optional for actions that delete data, send external messages, or trigger payments. Wire them in at project start, not after the first incident.