A Bird’s-Eye View on Java Concurrency Frameworks
Learn more about popular Java concurrency frameworks — RxJava, Akka, Disruptor, and ExecutorService.
Join the DZone community and get the full member experience.
Join For FreeThe Why Question
A few years ago, when NoSQL was trending, like every other team, our team was also enthusiastic about the new and exciting stuff; we were planning to change the database in one of the applications. But when we got into the finer details of the implementation, we remembered what a wise man once said, “the devil is in the details,” and eventually, we realized that NoSQL is not a silver bullet to fixing all problems, and the answer to NoSQL VS RDMS was: “it depends.” Similarly, in the last year, concurrency libraries like RxJava and Spring Reactor were trending with enthusiastic statements, like the asynchronous, non-blocking approach is the way to go, etc. In order to not make the same mistake again, we tried to evaluate how concurrency frameworks like ExecutorService, RxJava, Disruptor, and Akka differ from one another and how to identify the right use case for respective frameworks.
Terminologies used in this article are described in greater detail here.
Sample Use Case for Analyzing Concurrency Frameworks
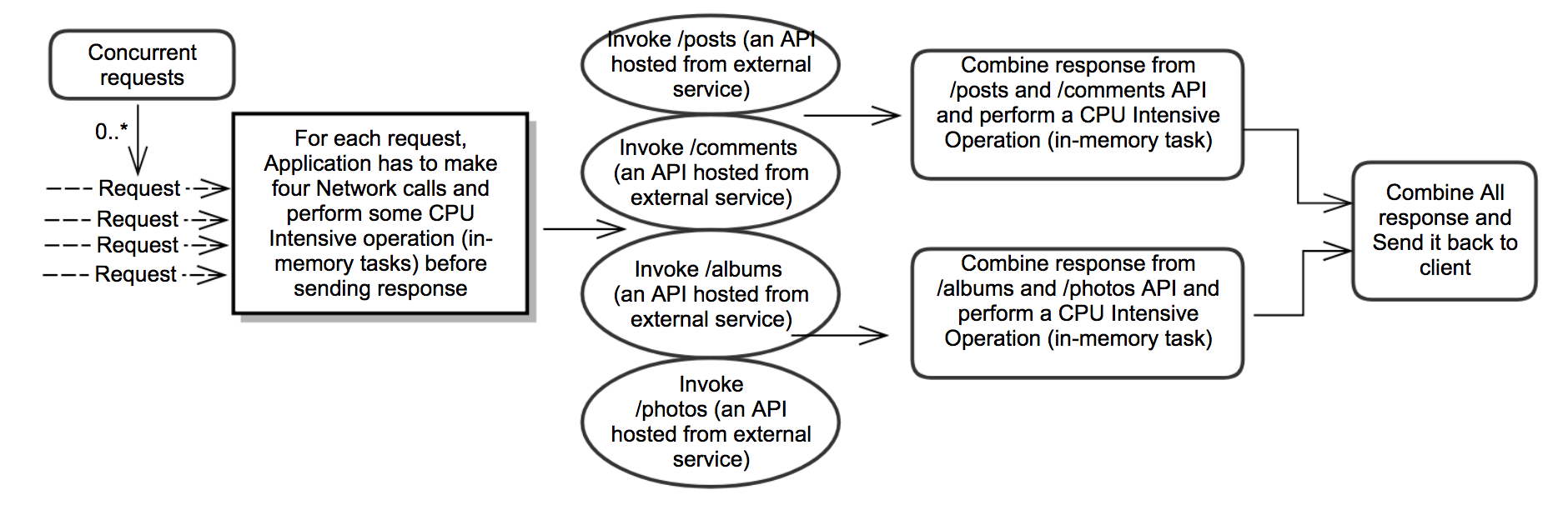
Quick Refresher on Thread Configuration
Before getting into a comparison of concurrency frameworks, let's have a quick refresher on how to configure the optimal number of threads to increase the performance of parallel tasks. This theory applies to all frameworks, and the same thread configuration has been used in all frameworks to measure performance.
- For in-memory tasks, the number of threads equals approximately the number of cores that has the best performance, though it can change a bit based on the hyper-threading feature in the respective processor.
- For example, in an 8-core machine, if each request to an application has to do four in-memory tasks in parallel, then the load on this machine should be maintained @ 2 req/sec with 8 threads in
ThreadPool.
- For example, in an 8-core machine, if each request to an application has to do four in-memory tasks in parallel, then the load on this machine should be maintained @ 2 req/sec with 8 threads in
- For I/O tasks, the number of threads configured in the
ExecutorServiceshould be based on the latency of an external service.- Unlike the in-memory task, the thread involved in the I/O task will be blocked and it will be in a waiting state until an external service responds or times out. So, when I/O tasks are involved, as the threads are blocked, the number of threads should be increased to handle the additional load from concurrent requests.
- The number of threads for I/O task should be increased in a conservative way, as many threads in the Active state bring the cost of context-switching, which will impact application performance. To avoid that, the exact number of threads and load of this machine should be increased proportionately to the waiting time of the threads involved in I/O task.
Reference: http://baddotrobot.com/blog/2013/06/01/optimum-number-of-threads/
Performance Results
Performance tests ran in GCP -> processor model name: Intel(R) Xeon(R) CPU @ 2.30GHz; Architecture: x86_64; No. of cores: 8 (Note: These results are subjective to this use-case and don’t imply one framework is better than another).
| Label | # of requests | Thread Pool size for I/O Tasks | Average Latency in ms (50 req/sec) |
| All the operations are in Sequential order | ~10000 | NA | ~2100 |
| Parallelize IO Tasks with Executor Service and use HTTP-thread for an in-memory task | ~10000 | 16 | ~1800 |
| Parallelize IO Tasks with Executor Service (Completable Future) and use HTTP-thread for an in-memory task | ~10000 | 16 | ~1800 |
Parallelize All tasks with ExecutorService and use @Suspended AsyncResponse response to send a response in a non-blocking manner |
~10000 | 16 | ~3500 |
Use Rx-Java for performing all tasks and use @Suspended AsyncResponse response to send a response in a non-blocking manner |
~10000 | NA | ~2300 |
| Parallelize All tasks with Disruptor framework (Http thread will be blocked) | ~10000 | 11 | ~3000 |
Parallelize All tasks with Disruptor framework and use @Suspended AsyncResponse response to send a response in a non-blocking manner |
~10000 | 12 | ~3500 |
| Parallelize All tasks with Akka framework (Http thread will be blocked) | ~10000 | ~3000 |
Parallelize IO Tasks With Executor Service
When to Use?
If an application is deployed in multiple nodes and if req/sec in each node is less than the number of cores available, then the ExecutorService can be used to parallelize tasks and execute code faster.
When Not to Use?
If an application is deployed in multiple nodes and if the req/sec in each node is much higher than the number of cores available, then using ExecutorService to further parallelize can only make things worse.
Performance results when the delay of external service is increased to 400 ms (request rate @ 50 req/sec in 8 core machine).
| Label | # of requests | Thread Pool size for I/O Tasks | Average Latency in ms (50 req/sec) |
| All the operations are in Sequential order | ~3000 | NA | ~2600 |
| Parallelize IO Tasks with Executor Service and use HTTP-thread for an in-memory task | ~3000 | 24 | ~3000 |
Example When all Tasks Are Executed in Sequential Order:
// I/O tasks : invoke external services
String posts = JsonService.getPosts();
String comments = JsonService.getComments();
String albums = JsonService.getAlbums();
String photos = JsonService.getPhotos();
// merge the response from external service
// (in-memory tasks will be performed as part this operation)
int userId = new Random().nextInt(10) + 1;
String postsAndCommentsOfRandomUser = ResponseUtil.getPostsAndCommentsOfRandomUser(userId, posts, comments);
String albumsAndPhotosOfRandomUser = ResponseUtil.getAlbumsAndPhotosOfRandomUser(userId, albums, photos);
// build the final response to send it back to client
String response = postsAndCommentsOfRandomUser + albumsAndPhotosOfRandomUser;
return response;
Code Example When I/O Tasks Are Executed in Parallel With the ExecutorService
// add I/O Tasks
List<Callable<String>> ioCallableTasks = new ArrayList<>();
ioCallableTasks.add(JsonService::getPosts);
ioCallableTasks.add(JsonService::getComments);
ioCallableTasks.add(JsonService::getAlbums);
ioCallableTasks.add(JsonService::getPhotos);
// Invoke all parallel tasks
ExecutorService ioExecutorService = CustomThreads.getExecutorService(ioPoolSize);
List<Future<String>> futuresOfIOTasks = ioExecutorService.invokeAll(ioCallableTasks);
// get results of I/O operation (blocking call)
String posts = futuresOfIOTasks.get(0).get();
String comments = futuresOfIOTasks.get(1).get();
String albums = futuresOfIOTasks.get(2).get();
String photos = futuresOfIOTasks.get(3).get();
// merge the response (in-memory tasks will be part of this operation)
String postsAndCommentsOfRandomUser = ResponseUtil.getPostsAndCommentsOfRandomUser(userId, posts, comments);
String albumsAndPhotosOfRandomUser = ResponseUtil.getAlbumsAndPhotosOfRandomUser(userId, albums, photos);
//build the final response to send it back to client
return postsAndCommentsOfRandomUser + albumsAndPhotosOfRandomUser;
Parallelize IO Tasks With Executor Service (CompletableFuture)
This works similar to the above case: the HTTP thread, which handles the incoming request, will be blocked, and CompletableFuture is used to handle the parallel tasks
When to Use?
Without AsyncResponse, performance is the same as the ExecutorService. If multiple API calls have to be async and if it has to be chained, this approach is better (which is similar to Promises in Node.)
ExecutorService ioExecutorService = CustomThreads.getExecutorService(ioPoolSize);
// I/O tasks
CompletableFuture<String> postsFuture = CompletableFuture.supplyAsync(JsonService::getPosts, ioExecutorService);
CompletableFuture<String> commentsFuture = CompletableFuture.supplyAsync(JsonService::getComments,
ioExecutorService);
CompletableFuture<String> albumsFuture = CompletableFuture.supplyAsync(JsonService::getAlbums,
ioExecutorService);
CompletableFuture<String> photosFuture = CompletableFuture.supplyAsync(JsonService::getPhotos,
ioExecutorService);
CompletableFuture.allOf(postsFuture, commentsFuture, albumsFuture, photosFuture).get();
// get response from I/O tasks (blocking call)
String posts = postsFuture.get();
String comments = commentsFuture.get();
String albums = albumsFuture.get();
String photos = photosFuture.get();
// merge response (in-memory tasks will be part of this operation)
String postsAndCommentsOfRandomUser = ResponseUtil.getPostsAndCommentsOfRandomUser(userId, posts, comments);
String albumsAndPhotosOfRandomUser = ResponseUtil.getAlbumsAndPhotosOfRandomUser(userId, albums, photos);
// Build final response to send it back to client
return postsAndCommentsOfRandomUser + albumsAndPhotosOfRandomUser;
Parallelize All Tasks With ExecutorService
Parallelize all tasks with the ExecutorService and use @Suspended AsyncResponse response to send a response in a non-blocking way.
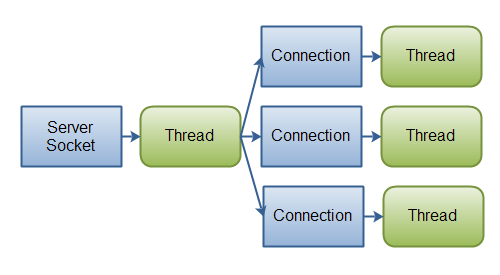 [io vs nio]
[io vs nio]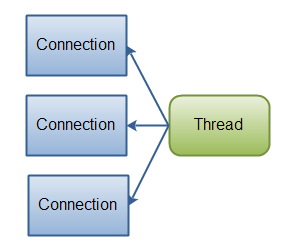
Images from http://tutorials.jenkov.com/java-nio/nio-vs-io.html
- Incoming requests will be handled via an event-pool and the request will be passed to the Executor pool for further processing, and when all tasks are done, another HTTP-thread from event-pool will send the response back to the client. (asynchronous and non-blocking).
- The reason for a drop in performance:
- In synchronous communication, though the thread involved in I/O task was blocked, the process will still be in running state as long as it has additional threads to take the load of concurrent requests.
- So, the benefit that comes from keeping a thread in a non-blocking manner is very less and the cost involved to handle the request in this pattern seems to be high.
- More often than not, using the asynchronous non-blocking approach for the use case we discussed here will bring down application performance.
When to Use?
If the use case is like a server-side chat application where a thread need not hold the connection until the client responds, then the async, non-blocking approach can be preferred over synchronous communication; in those use cases, rather than just waiting, system resources can be put to better use with the asynchronous, non-blocking approach.
// submit parallel tasks for Async execution
ExecutorService ioExecutorService = CustomThreads.getExecutorService(ioPoolSize);
CompletableFuture<String> postsFuture = CompletableFuture.supplyAsync(JsonService::getPosts, ioExecutorService);
CompletableFuture<String> commentsFuture = CompletableFuture.supplyAsync(JsonService::getComments,
ioExecutorService);
CompletableFuture<String> albumsFuture = CompletableFuture.supplyAsync(JsonService::getAlbums,
ioExecutorService);
CompletableFuture<String> photosFuture = CompletableFuture.supplyAsync(JsonService::getPhotos,
ioExecutorService);
// When /posts API returns a response, it will be combined with the response from /comments API
// and as part of this operation, some in-memory tasks will be performed
CompletableFuture<String> postsAndCommentsFuture = postsFuture.thenCombineAsync(commentsFuture,
(posts, comments) -> ResponseUtil.getPostsAndCommentsOfRandomUser(userId, posts, comments),
ioExecutorService);
// When /albums API returns a response, it will be combined with the response from /photos API
// and as part of this operation, some in-memory tasks will be performed
CompletableFuture<String> albumsAndPhotosFuture = albumsFuture.thenCombineAsync(photosFuture,
(albums, photos) -> ResponseUtil.getAlbumsAndPhotosOfRandomUser(userId, albums, photos),
ioExecutorService);
// Build the final response and resume the http-connection to send the response back to client.
postsAndCommentsFuture.thenAcceptBothAsync(albumsAndPhotosFuture, (s1, s2) -> {
LOG.info("Building Async Response in Thread " + Thread.currentThread().getName());
String response = s1 + s2;
asyncHttpResponse.resume(response);
}, ioExecutorService);
RxJava/RxNetty
- The main difference of RxJava/RxNetty combination is, it can handle both incoming and outgoing requests with an event-pool there by making the I/O tasks completely non-blocking.
- Also, RxJava gives better DSL to write code in a fluid manner, which may not be visible with this example.
- Performance is better than handling parallel tasks with
CompletableFuture
When to Use?
If the asynchronous, non-blocking approach suits a use-case, then RxJava or any reactive libraries can be preferred. It has additional capabilities like back-pressure, which can balance the load between producers and consumers.
// non blocking API call from Application - getPosts()
HttpClientRequest<ByteBuf, ByteBuf> request = HttpClient.newClient(MOCKY_IO_SERVICE, 80)
.createGet(POSTS_API).addHeader("content-type", "application/json; charset=utf-8");
rx.Observable<String> rx1ObservableResponse = request.flatMap(HttpClientResponse::getContent)
.map(buf -> getBytesFromResponse(buf))
.reduce(new byte[0], (acc, bytes) -> reduceAndAccumulateBytes(acc, bytes))
.map(bytes -> getStringResponse(bytes, "getPosts", startTime));
int userId = new Random().nextInt(10) + 1;
// Submit parallel I/O tasks for each incoming request.
Observable<String> postsObservable = Observable.just(userId).flatMap(o -> NonBlockingJsonService.getPosts());
Observable<String> commentsObservable = Observable.just(userId)
.flatMap(o -> NonBlockingJsonService.getComments());
Observable<String> albumsObservable = Observable.just(userId).flatMap(o -> NonBlockingJsonService.getAlbums());
Observable<String> photosObservable = Observable.just(userId).flatMap(o -> NonBlockingJsonService.getPhotos());
// When /posts API returns a response, it will be combined with the response from /comments API
// and as part of this operation, some in-memory tasks will be performed
Observable<String> postsAndCommentsObservable = Observable.zip(postsObservable, commentsObservable,
(posts, comments) -> ResponseUtil.getPostsAndCommentsOfRandomUser(userId, posts, comments));
// When /albums API returns a response, it will be combined with the response from /photos API
// and as part of this operation, some in-memory tasks will be performed
Observable<String> albumsAndPhotosObservable = Observable.zip(albumsObservable, photosObservable,
(albums, photos) -> ResponseUtil.getAlbumsAndPhotosOfRandomUser(userId, albums, photos));
// build final response
Observable.zip(postsAndCommentsObservable, albumsAndPhotosObservable, (r1, r2) -> r1 + r2)
.subscribe((response) -> asyncResponse.resume(response), e -> {
LOG.error("Error", e);
asyncResponse.resume("Error");
});Disruptor
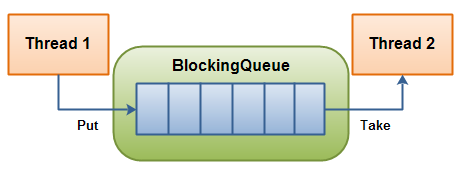
[Queue vs RingBuffer]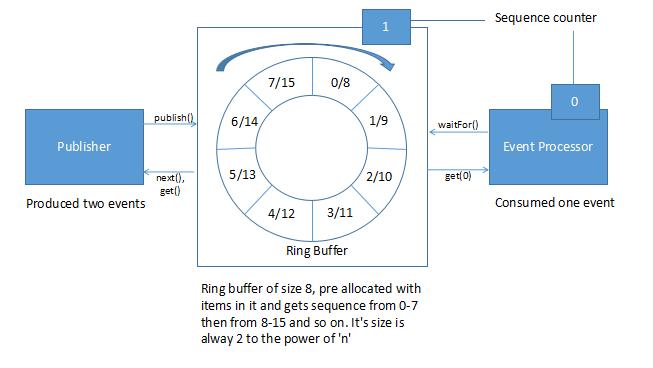
Image 1: http://tutorials.jenkov.com/java-concurrency/blocking-queues.html
Image 2: https://www.baeldung.com/lmax-disruptor-concurrency
- In this example, HTTP-thread will be blocked until the disruptor completes the tasks and a
CountDownLatchhas been used to synchronize the HTTP-thread with the threads fromExecutorService. - The main feature of this framework is to handle inter-thread communication without any locks; in
ExecutorService, the data between a producer and consumer will be passed via a Queue, and there is aLockinvolved during this data transfer between a producer and a consumer. The Disruptor framework handles this Producer-Consumer communication without anyLockswith the help of a data-structure called Ring Buffer, which is an extended version of a Circular Array Queue. - This library was not meant for use cases like the one we discuss here. It has been added just out of curiosity.
When to Use?
The Disruptor framework performs better when used with event-driven architectural patterns and when there is a single producer and multiple consumers with the main focus on in-memory tasks.
static {
int userId = new Random().nextInt(10) + 1;
// Sample Event-Handler; count down latch is used to synchronize the thread with http-thread
EventHandler<Event> postsApiHandler = (event, sequence, endOfBatch) -> {
event.posts = JsonService.getPosts();
event.countDownLatch.countDown();
};
// Disruptor set-up to handle events
DISRUPTOR.handleEventsWith(postsApiHandler, commentsApiHandler, albumsApiHandler)
.handleEventsWithWorkerPool(photosApiHandler1, photosApiHandler2)
.thenHandleEventsWithWorkerPool(postsAndCommentsResponseHandler1, postsAndCommentsResponseHandler2)
.handleEventsWithWorkerPool(albumsAndPhotosResponseHandler1, albumsAndPhotosResponseHandler2);
DISRUPTOR.start();
}
// for each request, publish an event in RingBuffer:
Event event = null;
RingBuffer<Event> ringBuffer = DISRUPTOR.getRingBuffer();
long sequence = ringBuffer.next();
CountDownLatch countDownLatch = new CountDownLatch(6);
try {
event = ringBuffer.get(sequence);
event.countDownLatch = countDownLatch;
event.startTime = System.currentTimeMillis();
} finally {
ringBuffer.publish(sequence);
}
try {
event.countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
Akka
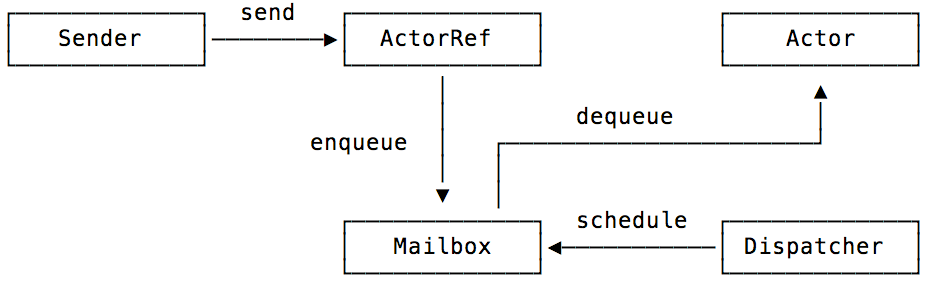 Image source: https://blog.codecentric.de/en/2015/08/introduction-to-akka-actors/
Image source: https://blog.codecentric.de/en/2015/08/introduction-to-akka-actors/
- The main advantage of the Akka library is that it has native support to build Distributed Systems.
- It runs on a system called the Actor System, which abstracts the concept of Threads, and Actors in the Actor System communicate via asynchronous messages, which is similar to the communication between a Producer and Consumer.
- This extra level of abstraction helps the Actor system provide features like Fault Tolerance, Location Transparency, and more.
- With the right Actor-to-Thread strategy, this framework can be optimized to perform better than the results shown in the above table. Though it cannot match the performance of a traditional approach on a single node, it can still be preferred for its capabilities to build Distributed and Resilient systems.
Sample Code
// from controller :
Actors.masterActor.tell(new Master.Request("Get Response", event, Actors.workerActor), ActorRef.noSender());
// handler :
public Receive createReceive() {
return receiveBuilder().match(Request.class, request -> {
Event event = request.event; // Ideally, immutable data structures should be used here.
request.worker.tell(new JsonServiceWorker.Request("posts", event), getSelf());
request.worker.tell(new JsonServiceWorker.Request("comments", event), getSelf());
request.worker.tell(new JsonServiceWorker.Request("albums", event), getSelf());
request.worker.tell(new JsonServiceWorker.Request("photos", event), getSelf());
}).match(Event.class, e -> {
if (e.posts != null && e.comments != null & e.albums != null & e.photos != null) {
int userId = new Random().nextInt(10) + 1;
String postsAndCommentsOfRandomUser = ResponseUtil.getPostsAndCommentsOfRandomUser(userId, e.posts,
e.comments);
String albumsAndPhotosOfRandomUser = ResponseUtil.getAlbumsAndPhotosOfRandomUser(userId, e.albums,
e.photos);
String response = postsAndCommentsOfRandomUser + albumsAndPhotosOfRandomUser;
e.response = response;
e.countDownLatch.countDown();
}
}).build();
}
Summary
- Decide the Executor framework’s configuration based on the load of the machine and also check if load balancing can be done based on the number of parallel tasks in the application. If optimum number of threads calculation for I/O tasks is done right, then more often than not, this approach will be the winner in Performance results.
- Using reactive or any asynchronous libraries decreases the performance for most of the traditional applications. This pattern is useful only when the use case is like a server-side chat application, where the thread need not retain the connection until the client responds.
- Performance of the Disruptor framework was good when used with event-driven architectural patterns; but when the Disruptor pattern was mixed with traditional architecture and for the use case we discussed here, it was not up to the mark. It is important to note here that the Akka and Disruptor libraries deserve a separate post on using them with event-driven architectural patterns.
The source code for this post can be found on GitHub.
Opinions expressed by DZone contributors are their own.
Comments