A Detailed Introduction to the Apache Access Log
This article aims to demystify the Apache access log, and how to use it to see where spam comes from (and more) by learning to read the logs.
Join the DZone community and get the full member experience.
Join For Freewhat is the apache access log? well, at the broadest level, it's a source of information about who is accessing your website and how.
but as you might expect, a lot more goes into it than just that. after all, people visiting your website aren't like guests at your wedding, politely signing a registry to record their presence. they'll visit for a whole host of reasons, stay for seconds or hours, and do all sorts of interesting and improbable things. and some of them will passively (or even actively) thwart information capture.
so, the apache access log has a bit of nuance to it. and it's also a little...complicated at first glance.
but don't worry - demystifying it is the purpose of this post.
apache access log: the why
i remember starting my first blog years and years ago. i paid for hosting and then installed a (much younger) version of wordpress on it.
for a while, i blogged into the void with nobody really paying attention. then i started to get some comments: a trickle at first, and then a flood. i was excited until i realized that they were all suspiciously vague and often non-sequiturs. "super pro info site you have here, opps, i hitted the capslock key." and these comments tended to link back to what i'll gently say weren't the finest sites the internet had to offer.
yep. comment spam.
somewhere between manually deleting these comments and eventually installing a wordpress plugin to help, i started to wonder where these comments were all coming from. they all seemed to magically appear in the middle of the night and they were spammy, but i was interested in patterns beyond that.
this is a perfect use case for the apache access log. you can use it to examine a detailed log of who has been to your website. the information about visitors can include their ip address, their browser, the actual http request itself, the response , and plenty more.

apache access log: the what and where
having established the value proposition, let's get a little more specific about some things.
apache is a widely used piece of software called a web server. the definition of "server" is always a little fuzzy since we use it to describe two related but different concepts: an actual computer (or virtual computer) and a piece of software running on that computer. both exist to wait for and respond to requests, but they exist at different levels of abstraction.
apache is a server of the software variety. specifically, it's a web server . this means that it lives to take in http requests and give back http responses . put more plainly, it gives you web pages.
as any piece of complex software should, apache leaves a lot of log files in its wake. the access log is one of those files. it simply has a list of all inbound requests, formatted to allow you to consume them easily (and probably with automated tooling).
the overwhelming majority of the time you see it in the wild, apache runs on linux. (you can port it to windows , but that's not common.) and you'll usually find the apache access log in the /var/log/apache/ directory, called access.log. this is not universal, though, because you can configure apache to store the log wherever you want, and conventions may vary by linux distribution. you can read about locating the log file in more detail here .
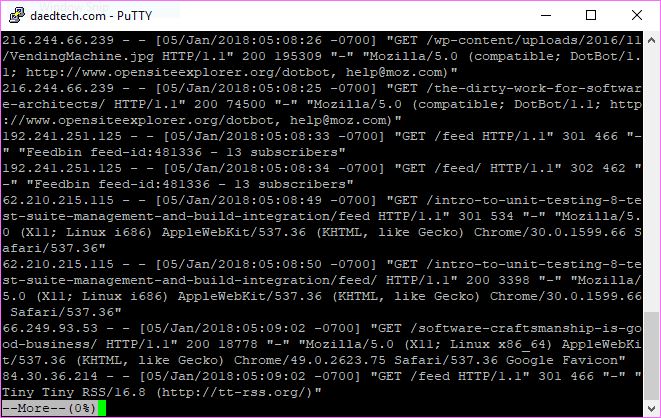
how to read the access log
when you look at the screenshot above of an access log, it may seem intimidating. part of that is viewing it through the ssh shell with the text wrapping around. but there's legitimately a whole lot of information packed in there, making it daunting at first.
really, though, it's just a series of log entries recorded one entry per line. each piece of information per entry is separated by a space. my log, in particular, is in the so-called "combined" format , meaning it contains the following information, in order:
- remote host (client ip address)
- user identity, or dash, if none (often not used)
- username, via http authentication, or dash if not used
- timestamp of when apache received the http request
- the actual request itself from the client
- the status code apache returns in response to the request
- referrer header , or dash if not used (in other words, did they click a url on another site to come to your site)
- user agent (contains information about the requester's browser/os/etc)
so if you were to parse the access log, you would first tokenize it by line and then by spaces into a series of entries. or, to think of it another way, consider that it would be pretty straightforward to import the apache access log to excel and view it there.
searching the log
okay, so now you understand the conceptual formatting of the access log and how to read it. but i'm guessing you're probably not going to grab a cup of coffee, sit down, and start reading it like a newspaper.
so, how do you work with this thing? how do you interpret it?
probably the most common way you're going to use it, especially at first, is with simple search. in the past, i've written a guide to searching files with grep and regex , and these access logs make an excellent candidate for that. for instance, you might do a search for all lines containing 404 to see all instances of users requesting non-existent pages.
if that's not sufficient, you can also open the logs with a text editor or with excel. this is a little more involved and may suffer when your files are particularly large, though.
and finally, you might also consume these logs via a more sophisticated, broader log management strategy by folding them into a log aggregation scheme . conceptually, this is somewhat like the aforementioned "put it into excel" concept. you leverage tooling that parses the logs for you and puts them into easily digestible formats, potentially including dashboards and graphs.
 customizing the access log format
customizing the access log format
you also have options beyond just how you consume the log file. if you want (and have the correct permissions to change settings in apache), you can also customize the information recorded in the file.
consider the “combined” format. i’ve described it in narrative fashion, but you can also represent it like this:
"%h %l %u %t \"%r\" %>s %b \"%{referer}i\" \"%{user-agent}i\""each of those represents a variable to the log formatting utility. in your apache configuration files , you can specify the variables you want to see in the access log. a detailed treatment of these configuration options is beyond the scope of this post, but you can see here the different options available to you .
as you can see, this is powerful stuff. you can get an awful lot of information about requests to your site and the people making them.
understand the opportunity here
how you handle access to all of this information should go beyond just satisfying simple curiosity. this information helps form the backbone of a good production strategy, and you should take advantage of it directly or indirectly.
you can mine the access log for all sorts of information. are you seeing an unusual number of errors or improper requests? is there a particular site referring a lot of traffic your way? this is just a tiny sampling of the sorts of questions you can answer.
so take a look through the apache access log and get comfortable with it. then, once you're comfortable with it, i suggest you develop a strategy for making use of the information it contains.
Published at DZone with permission of . See the original article here.
Opinions expressed by DZone contributors are their own.
Comments