A Review of DataWeave 2.0 Selectors
Selecting data for data transformation in Mule 4
Join the DZone community and get the full member experience.
Join For FreeIntroduction
With the introduction of Mule 4, MuleSoft has significantly revamped its functional data transformation language DataWeawe (DW for short), making it even more central to Mule development by having it replace the Mule Expression Language (MEL). The switch from version 1.0 to 2.0 of DW has brought about many new features without changing the language structure.
While it is true that non-trivial DW transforms will make use of operators that do structural message transformations on arrays and objects (map, mapObject, pluck, flatten, groupBy), it remains essential to select the right input data for these powerful operators to work on. This is the purpose of data selectors.
By reviewing the latest DataWeave 2.x documentation on this matter again the corresponding older DW 1.0 documentation, it is clear how functionality has been added.
This tutorial will focus on the most important selectors:
- Single value (.) selector
- Multi-value selector (.*)
- Index ([<i>]) and Range ([<m> to <n>]) selectors
- Descendant selector (..)
- Filter selector ([?()]
- XML attribute (.@) selector
Sample Input
For this tutorial, I will use a sample XML document and WorldCities.xml and an equivalent JSON document WorldCities.json as input payloads, which all can be found at the linked Github public gists.


It is always good practice to define a metadata type in Anypoint Studio for every significant type of structured data in the scope of our Mule application (right-click on Studio project —> Mule —> Manage Metadata Types…, see Metadata Editor documentation).
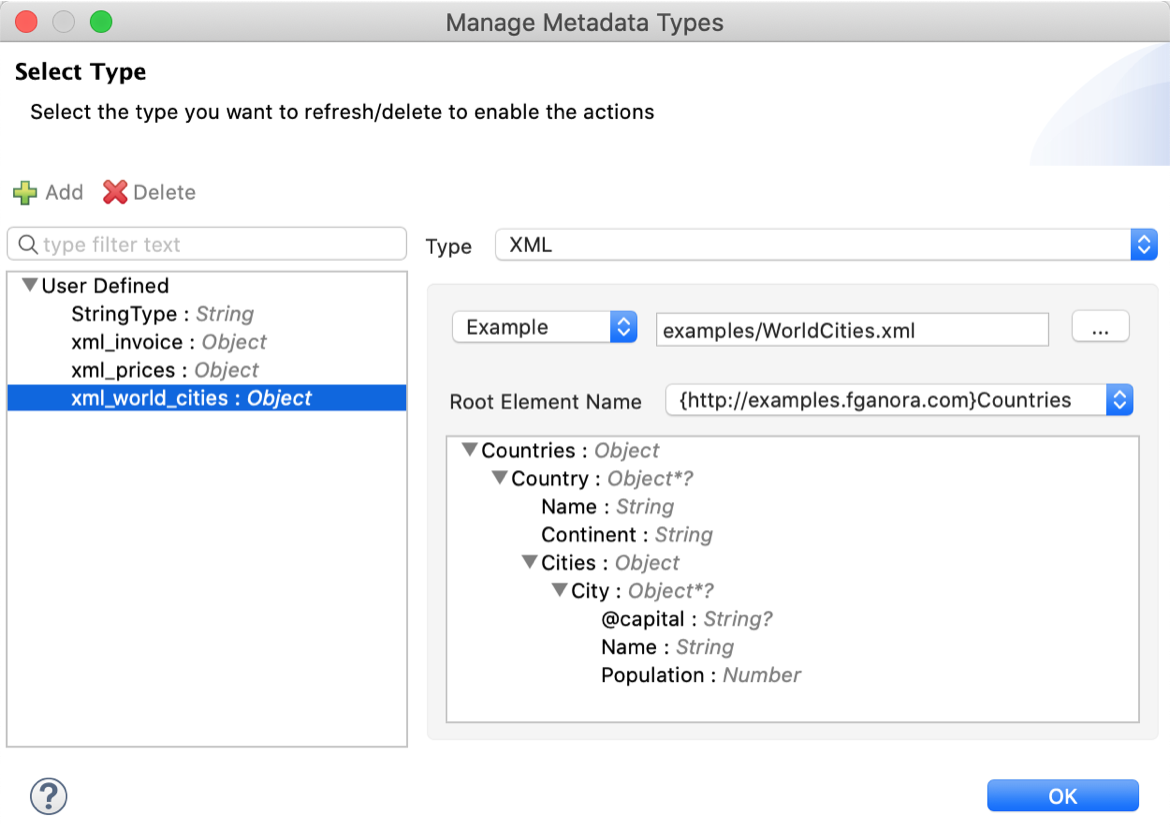
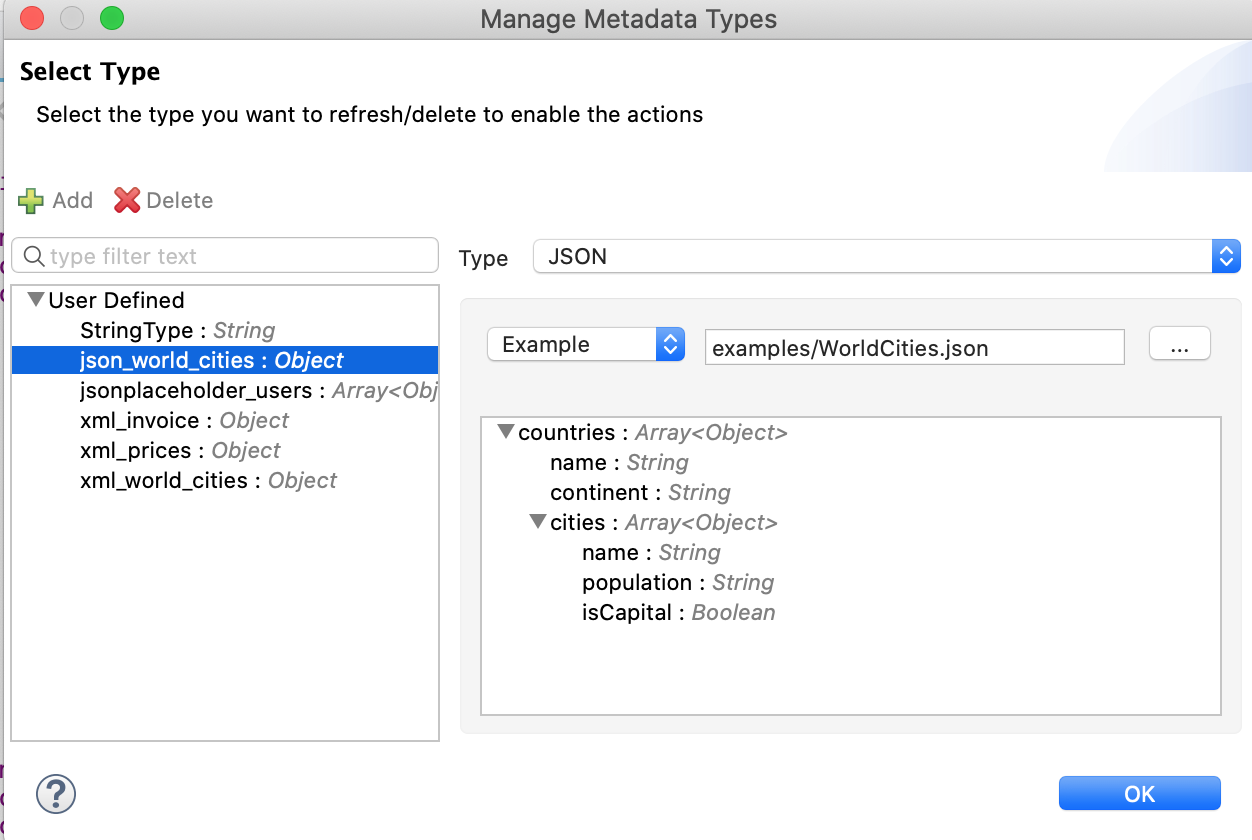
The sample files should be part of the project and will be used as sample data in the Transform Message component so we can incrementally test our DW script while we build and refactor it, without the need of running the project.
Regarding the XML input, let us bear in mind that whenever DW parses XML, repeated elements are parsed as repeated object key/value pairs and NOT grouped in an array, as can be seen when showing the canonical internal representation (output type application/dw ) of the input payload:

Applying the Selectors
Let us now start using our selectors on the source payload.
Single-Value Selector
The single-value selector uses the familiar “dot notation” (i.e. <object>.<field>) to navigate objects and extract the first matching value on a given “hierarchical path”. For example, to extract the same of the first country from WorldCities.xml, we would use expression payload.Countries.Country.Name
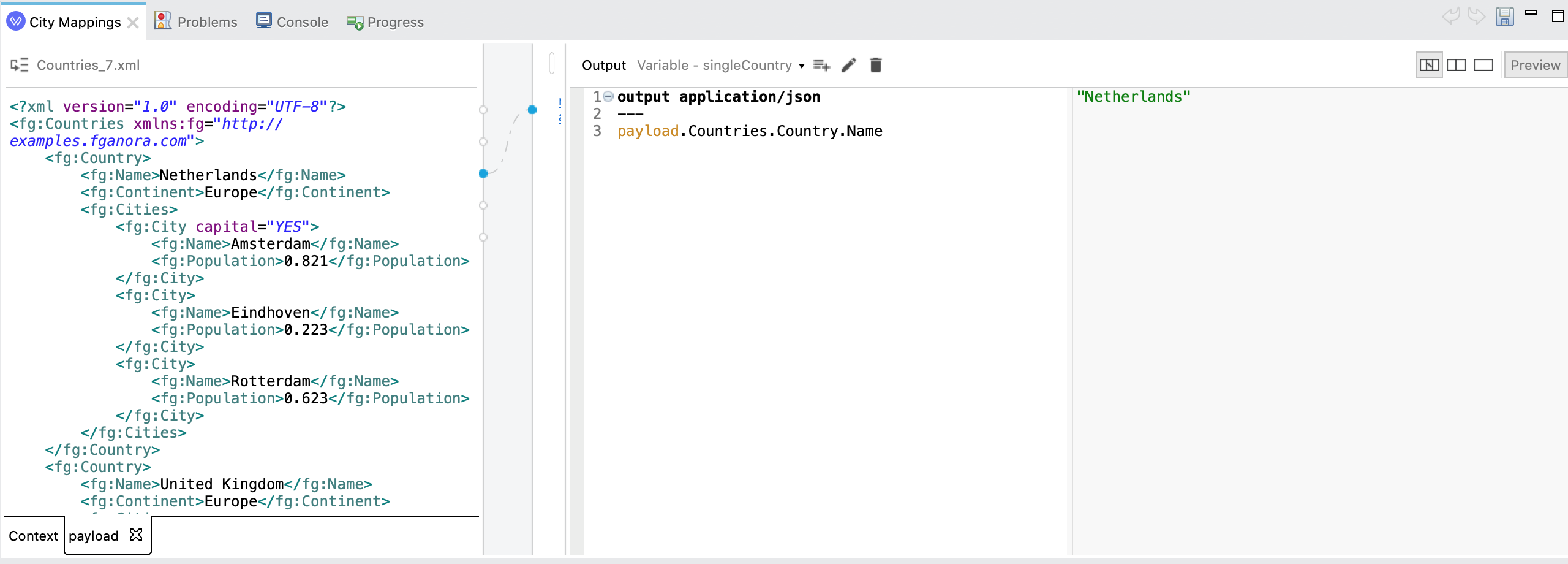
Note that the extraction works even without a namespace declaration.
Declaring the namespace fg and using it in the selection path via the fg# prefix gets the same result since DW is able to operate from the internal DW representation of the document (parsed from XML) independently of the namespace prefix.
However, it is important to be aware that a similar selection on the JSON source would produce an array of country names:
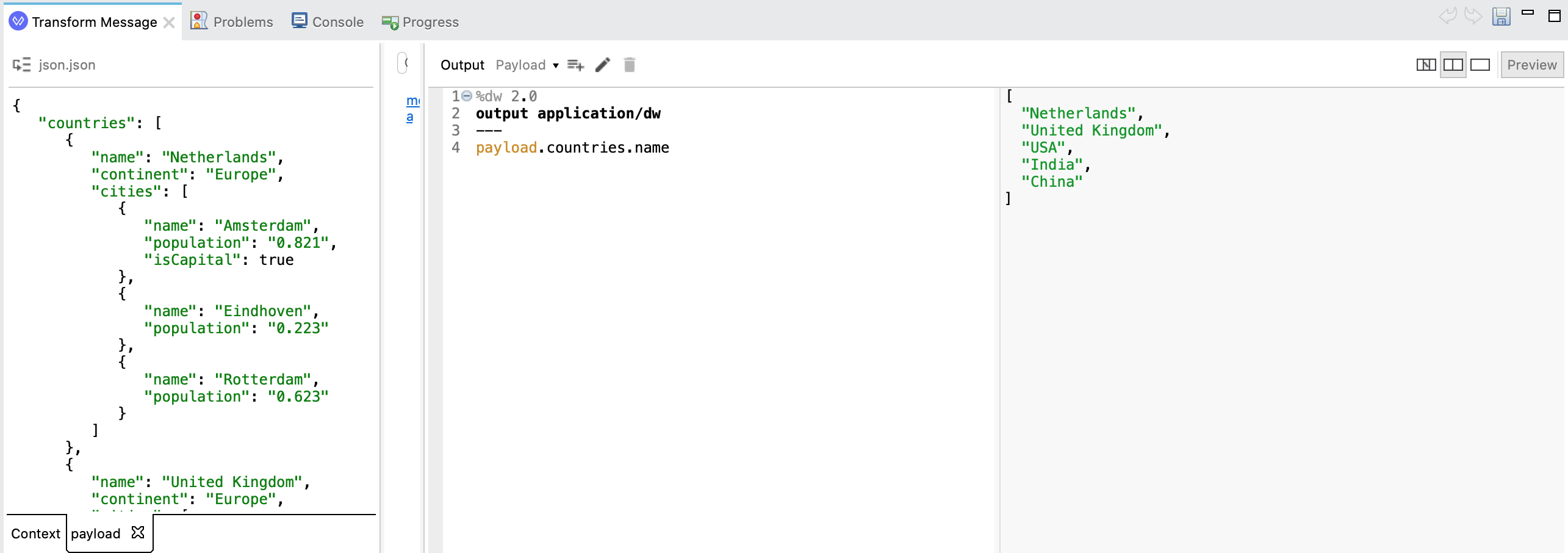
The reason is that the source XML is parsed purely as nested DW objects, which JSON arrays are parsed as equivalent DW array. Since countries from the JSON input is an array, the selector applies to all object values inside it. This behavior is mentioned in the Mulesoft documentation. This trivial example shows how valuable the Preview functionality of the Transform Message component to check what the actual output is going to be.
Multi-Value Selector
The multi-value selector is expressed via an asterisk (*) character immediately in front of the the element for which we want to extract an array of values. In case there are indeed multiple values in the input for that element, the length of the array will be > 1, if there is a single value we will still get an array but with length 1.
The expression payload.Countries.*Country.Namewill give as output an array of country names from our WorldCities.xml , rather that just the name of the first country:
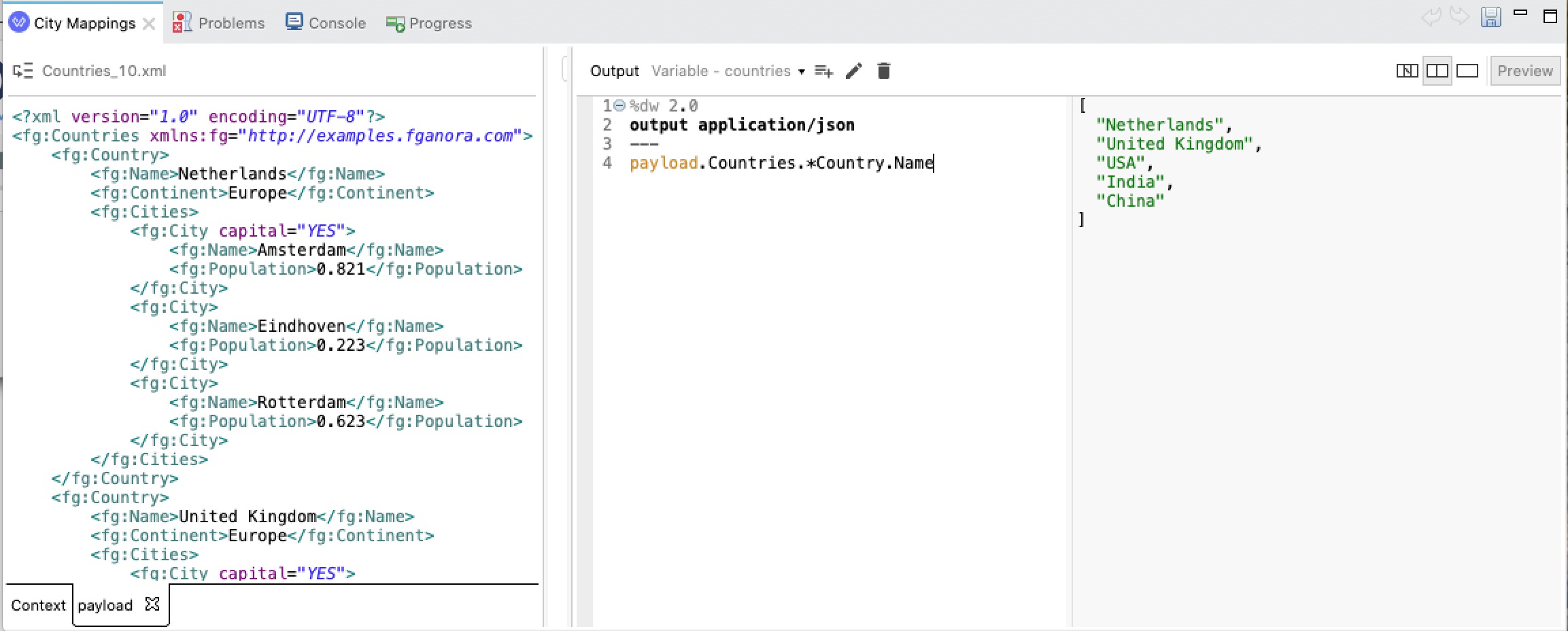
The use of the multi-value selector has produced from the XML input the same result, as we got above from the JSON input, which already contained an array of countries.
Index and Range Selectors
Once the have an array, using the familiar index notation with square brackets ( [] ) to select an element at a particular index (zero-based). This is called quite predictably index selector. For example, since India is the Country element with index 3 in the XML input payload, we produce an array of Indian city names as follows by combining indexing with multi-value selectors:
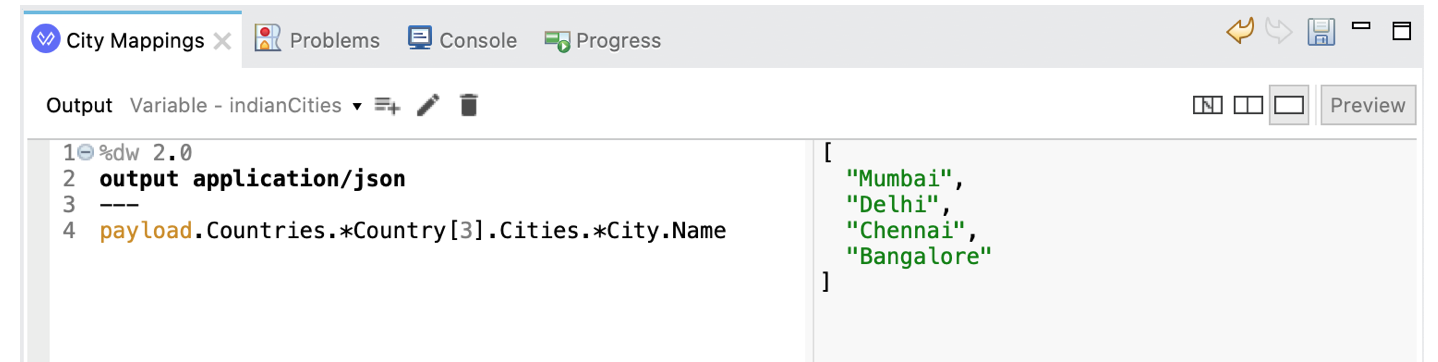
If we omitted the [3] index selector from the above (i.e., we write payload.Countries.*Country.Cities.*City.Name) we would have got an array with the names of all cities across all countries in the source payload.
A Range selector (with syntax [<start index> to <end index>] ) is also available, so we can for example select the names of the countries with indexes 2 to 3:
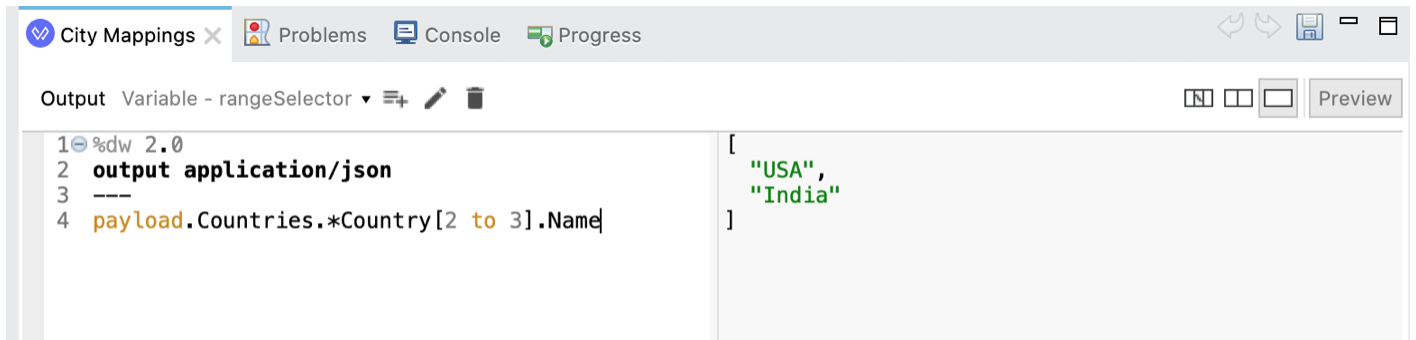
We have to say that in practice the index and range selector are only useful when our input contains arrays or sequences in which the order of the elements carries some predefined semantics. For example, if we previously ordered a sequence according to some criteria, we can then use the range selector [0 to 2] to select the "top three" elements in this ranking.
Descendant Selector
Using the combination of single- and multi-value selector to navigate through a complex message structure can lead to long expressions like for example what we saw to select a list (array) of city namespayload.Countries.*Country.Cities.*City.Name
DataWeave lets us make the same selection using a shorter expression via the descendant selector, which is represented by two consecutive periods (..).
This powerful selector selects all matching elements even deep into a document hierarchy, without the need of specifying the intermediate levels, like this: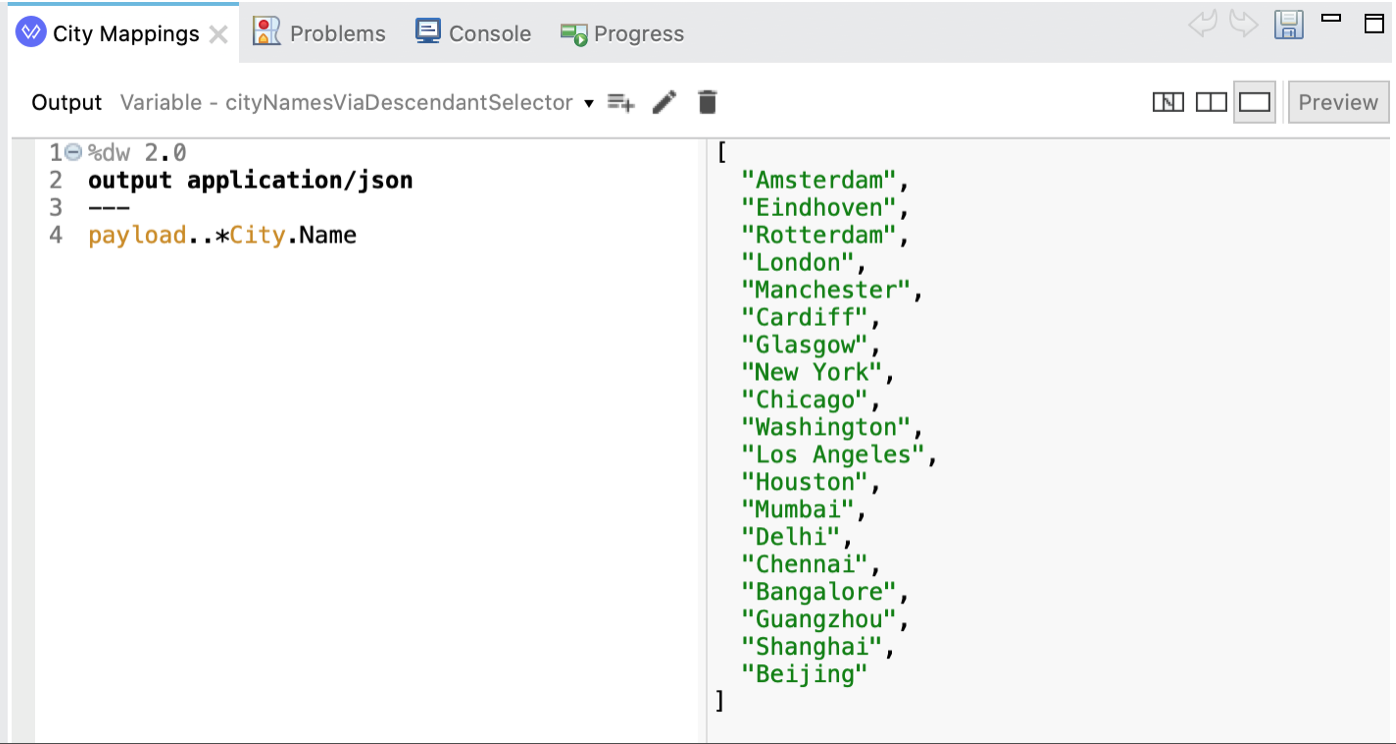
Note that the multi-value selector ( * ) is still necessary to make sure an array of City elements is extracted (from which to select the Name value for each). If we omit the multi-value selector for City (i.e. we write payload..City.Name), we get one one city per Country, which is probably not what we want.
Filter Selector
For DataWeave selectors to have an expressing power equivalent to language like XPath (the latter is anyway limited to XML data) it needs to have some form of conditional selection, i.e. bein able to selecting only elements in the input that meet certain conditions.
This is achieved with the filter selector, which has the syntax [?(<conditional expression>)] and must immediately follow a multi-value selector.
The <conditional expression> is applied to every array element extracted by the multi-value selector and only those elements for which the condition evaluates to true are retained in the produced array. This selector may be used as alternative to the DW filter function in the cases when the conditional expression is simple.
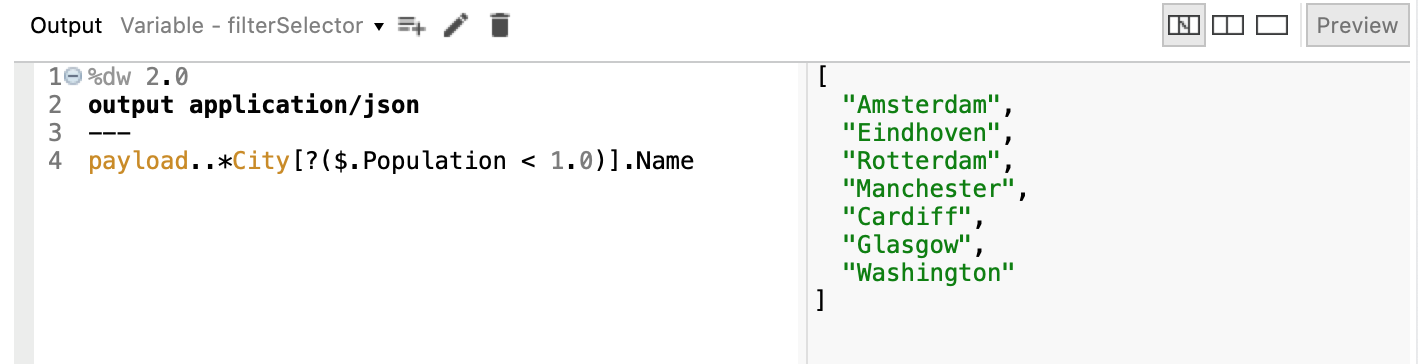
To make its usage concrete, suppose we want to extract a string list (array) containing the names of cities that have less than one million inhabitants. The list of all cities is given by: payload..*City.Name. Then, we want to insert the filter condition after the *City selector payload..*City[?( <condition> )].Name, but how to correctly express <condition> in the above selector?
Without going into the way in which the Mule DW engine actually operates internally (which is by streaming Java collections and applying lambda functions), we can imagine that as the *City array is being generated a variable holds the “current” city (a kind of loop variable if you really need to put it in procedural terms), and this variable can be referenced via the dollar ($) character, so $.Population represents the population (in millions) of the current city. Therefore, our expression becomespayload..*City[?($.Population < 1.0)].Name and yields the correct, expected result:
A slightly more complex example is the following, which extracts the cities in either UK or USA which have more than 3M inhabitants:

In this case, two filter selectors are applied, the first to the *Country array, and the second to the *City array.
XML Attribute Selector
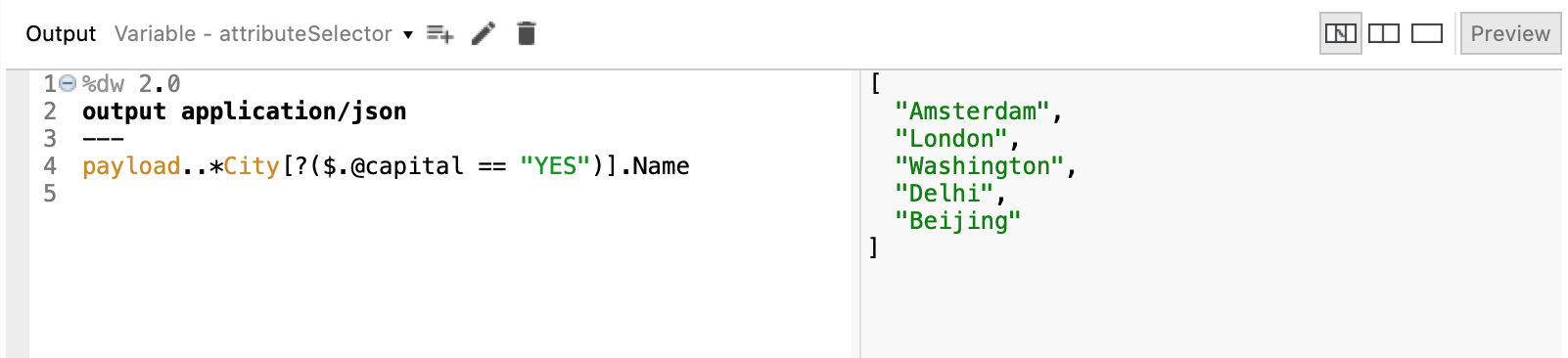
Finally, if our input is an XML document that includes attributes, we can select the values of these XML attributes via the attribute selector (attribute name prefixed by .@). As an example, let us use this selector in conjunction with the filter selector seen above to extract a list with the names of the cities, which are the capitals of their country (corresronding to City elements with attribute capital="YES")
Conclusion
Selectors are really very basic elements of DataWeave, but they must be understood well in order to apply the more "fancy" transformation functions that make use of lambdas. It is key to "serve" the right input to a transformation function via the appropriate selector so that the function can be effective and concise.
Opinions expressed by DZone contributors are their own.
Comments