How to Build an Agentic AI SRE Co-Pilot for Incident Response
Build an agentic SRE co-pilot using LLMs to autonomously reason, plan, and execute incident response across complex, multi-cloud infrastructure.
Join the DZone community and get the full member experience.
Join For FreeLarge-scale cloud platforms have reached a level of complexity — spanning multi-region Kubernetes clusters, streaming systems like Kafka, and heterogeneous data stores — that often exceeds human cognitive limits. Failures are no longer isolated events; they are emergent behaviors arising from tightly coupled systems where issues propagate across layers such as networking, orchestration, and data pipelines. Even with modern observability stacks, operators must manually correlate signals across dashboards, making incident response slow, inconsistent, and cognitively taxing.
Traditional approaches rely heavily on static runbooks and tribal knowledge. These mechanisms do not scale in modern distributed systems. Agentic AI introduces a fundamentally different paradigm. Rather than merely detecting anomalies (as in traditional AIOps), agentic systems use Large Language Models (LLMs) to reason, plan, and act. These systems can iteratively generate hypotheses, validate them using real data, and execute multi-step remediation workflows. The result is not just faster detection, but a closed-loop system capable of autonomous diagnosis and recovery.
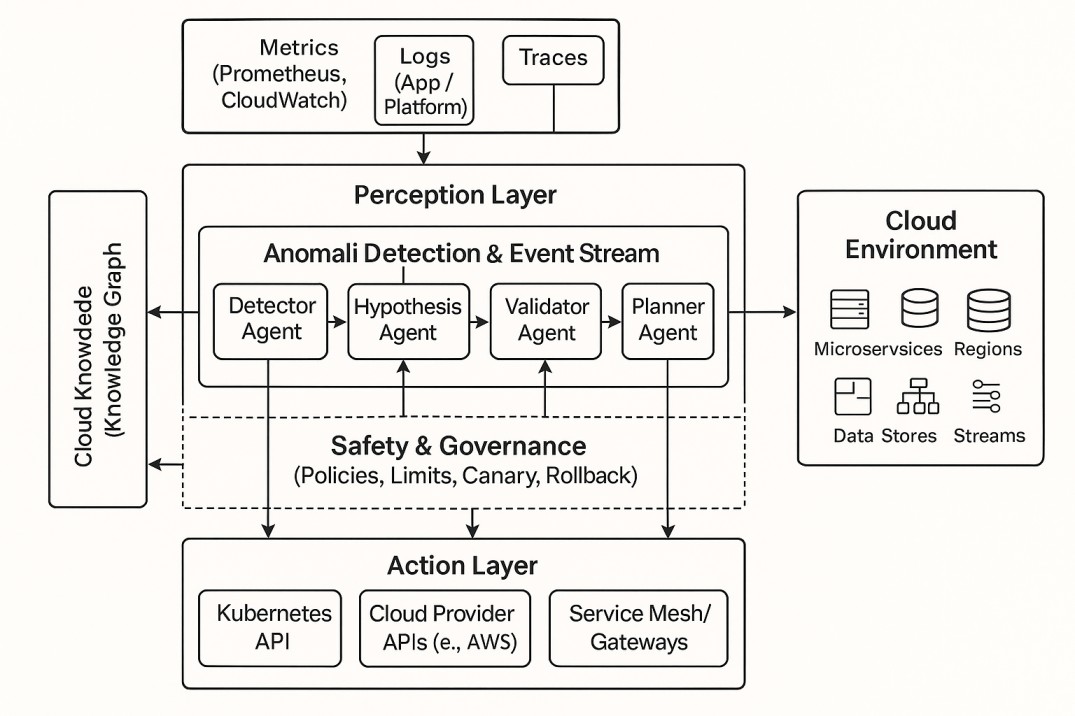
This article expands on how to architect a production-grade SRE agent that can safely and effectively automate cloud incident response. The system is organized into three layers: Perception (data ingestion), Cognition (multi-agent reasoning), and Action (guarded execution), all operating over a shared knowledge graph.
Establish a Cloud Knowledge Graph
At the core of any intelligent SRE agent is context. Raw telemetry alone is insufficient; the system must understand how components relate to each other. This is achieved through a domain-specific cloud knowledge graph.
The graph models:
- Nodes: Services, pods, clusters, regions, gateways, Kafka topics, and databases
- Edges: Traffic flows, deployment relationships, data lineage, ownership, and failover paths
- Attributes: SLOs, capacity limits, configuration history, and prior incidents
This structure transforms observability data into a causal reasoning substrate. Instead of treating metrics independently, the agent can traverse dependencies and infer propagation paths. For example, a spike in API latency can be traced through upstream gateways to downstream services and eventually to a throttled database.
This graph is not static — it evolves continuously with infrastructure changes and incident learnings. Over time, it becomes a living system model enriched with historical context, enabling better hypothesis generation and faster root-cause analysis.
In practice, maintaining graph freshness is critical. You should integrate it with service registries, deployment pipelines, and configuration management systems to ensure it reflects real-time topology.
Build the Perception Layer (Observability Pipeline)
The Perception Layer acts as the sensory system of the agent, continuously ingesting telemetry across the stack. This includes:
- Metrics: CPU, memory, I/O, network utilization, Kafka consumer lag
- Logs: Structured and semi-structured application and infrastructure logs
- Traces: End-to-end request paths across microservices
However, raw ingestion is only the first step. The real value lies in transforming this data into structured, actionable signals.
A stream-processing pipeline should:
- Normalize data across heterogeneous sources
- Detect anomalies using statistical methods and thresholds
- Emit structured events tied to entities in the knowledge graph
These events act as triggers for the Cognition Layer. Importantly, they should already be enriched with context (e.g., “Service A in region us-east-1 exceeds latency SLO”), reducing the reasoning burden on downstream agents.
A critical design consideration is balancing sensitivity and noise. Excessive alerting leads to “signal overload,” a well-known issue where operators — and agents — struggle to prioritize meaningful events . Techniques such as event deduplication, correlation, and temporal aggregation are essential to ensure high-quality inputs.
Architect a Multi-Agent Cognition Layer
Instead of using a single massive prompt, build a Cognition Layer utilizing a multi-agent LLM architecture (using GPT-5 or Claude-Opus class models) orchestrated by a control plane (e.g., a serverless orchestration layer). Assign specialized roles to different agents:
- Detector Agent: Monitors the anomaly events and groups related alerts into candidate incidents based on the knowledge graph's dependency structure.
- Hypothesis Agent: Proposes potential root causes by analyzing the graph and recent telemetry data.
- Validator Agent: Acts as the investigator by issuing targeted queries back to the observability tools and cloud APIs to confirm or reject the hypotheses based on hard evidence.
- Planner Agent: Synthesizes an actionable remediation plan. This plan should be an ordered list of operations, complete with preconditions, postconditions, and explicit rollback triggers.
- Critic (Governance) Agent: Reviews the remediation plan against organizational safety policies before execution, ensuring constraints are not violated.
Implement a Guarded Action Layer
The Action Layer is what separates an active agent from a passive AIOps recommendation engine. It executes the Planner Agent's steps via the Kubernetes API (scaling, restarting pods) and Cloud Provider APIs (toggling failovers, adjusting traffic weights).
Safety is paramount. You must wrap this layer in a strict governance framework:
- Enforce hard limits on scaling factors and failover scopes.
- Implement canary rollouts, applying changes to a single zone before expanding.
- Build auto-rollback mechanisms that trigger immediately if Service Level Objectives (SLOs) deteriorate after an action.
- Require explicit human-operator approval for high-risk operations like region-wide failovers.
Rollout and Optimization Strategies
When deploying your SRE agent, start in a "shadow" or assist mode. Allow the agent to observe incidents, propose hypotheses, and draft plans while human operators retain full control and execute the final decisions. As confidence in the system grows, gradually grant it autonomy for low-risk, routine actions.
To manage operational costs and latency:
- Optimize prompts: Externalize static system descriptions into retrieved documents.
- Caching: Cache intermediate inferences for reuse across similar recurring incidents.
- Batching: Batch non-urgent tool calls and defer low-impact infrastructure checks to background tasks.
Conclusion
Agentic AI represents a shift from reactive monitoring to proactive, autonomous operations. By combining a real-time observability pipeline, a continuously evolving knowledge graph, and a multi-agent reasoning system, you can build an SRE agent capable of end-to-end incident management.
Using this framework can significantly reduce Mean Time To Recovery, improve root-cause accuracy, and decrease reliance on human escalation — all while maintaining strict safety guarantees.
More importantly, these systems create a virtuous cycle: every incident enriches the knowledge graph, improves agent reasoning, and strengthens operational resilience. As cloud systems continue to grow in complexity, agentic SRE architectures will likely become a foundational component of modern reliability engineering.
Opinions expressed by DZone contributors are their own.
Comments