When Snowflake Lies to You: Understanding False Failures in dbt Pipelines
Your pipeline failed. Your code is fine. This article will walk you through why both things can be true at the same time.
Join the DZone community and get the full member experience.
Join For FreeThe Problem Most Teams Get Wrong
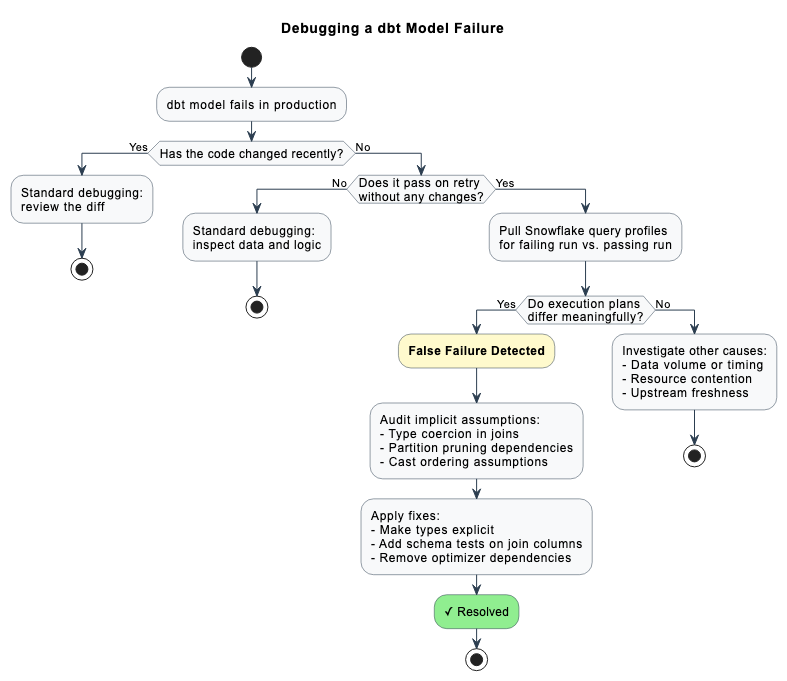
Every data engineer has lived this moment. A dbt model fails at 3 AM. You pull up the logs, see a type conversion error, and start digging through SQL. You check recent commits. Nothing changed. You inspect the upstream data. Nothing looks off. You rerun the job. It passes.
You shrug, label it a transient issue, and go back to sleep.
Then it happens again two weeks later.
I want to talk about a specific category of pipeline failure that burns more engineering hours than almost anything else I've seen. It looks real. It carries a real error message, a real stack trace, a failed model, and a timestamp you can point to in your incident log. But no matter how long you stare at the SQL, you will not find the bug.
Because there isn't one.
I call these false failures: jobs that break not because your logic is wrong, but because your query contains an implicit assumption that the execution engine has been quietly honoring until the moment it decides not to.
What This Actually Looks Like in Practice
The pattern becomes obvious once someone points it out to you. A model fails with an error referencing a specific data value. A cast that didn't work. A type mismatch. You investigate and find that the offending value has existed in the table for months. It is not new. It did not arrive in last night's load.
You rerun the job without changing anything. It passes.
This is not a flaky test. It is not Snowflake having a bad day. It is a determinism problem, and it has a precise mechanical cause.
Here's how to spot it: The failure is intermittent. It does not reproduce consistently, even in the same environment with the same data. The error references a value that has been present in the source table for a long time. A retry with zero intervention passes cleanly. And if you bother to pull up the Snowflake query profile, you'll notice the execution plan differs between the failing run and the passing one.
That last detail is the key to everything.
Why Snowflake Makes This Possible
Here is something fundamental about Snowflake that most people working with it never fully internalize: it does not guarantee a consistent execution plan between runs of the same query.
Snowflake's optimizer is adaptive. It reassesses strategy at runtime based on conditions that shift constantly. Several things influence which plan it picks:
Micro-partition metadata gets updated asynchronously after data loads. The same query issued before and after a stats refresh can follow a meaningfully different path through the data.
Warehouse size and concurrency affect parallelism thresholds. What gets broadcast-joined on an XS warehouse may be hash-joined on a Medium. The plan changes because the available compute changed.
Data volume growth pushes the optimizer across execution thresholds over time. A strategy that worked at 10 million rows may get abandoned entirely at 500 million.
Implicit type coercion is where things get dangerous. When two columns of different types meet in a join condition, Snowflake resolves the mismatch at runtime. Which side gets cast, and at what point during execution, can vary by plan.
That last one is where most false failures are born.
A Real Example: The Join That Only Breaks on Tuesdays
Here's a model I've seen variations of in at least a dozen production pipelines:
SELECT
o.*,
e.event_type
FROM orders o
LEFT JOIN events e
ON o.order_id = e.event_keyLooks harmless. But there's a mismatch hiding in plain sight. orders.order_id is typed as NUMBER. events.event_key is typed as VARCHAR.
Snowflake allows this. It resolves the mismatch by casting the VARCHAR side to a number at join time. Since the vast majority of rows in the events table contain numeric-looking keys, this works fine. Almost all the time.
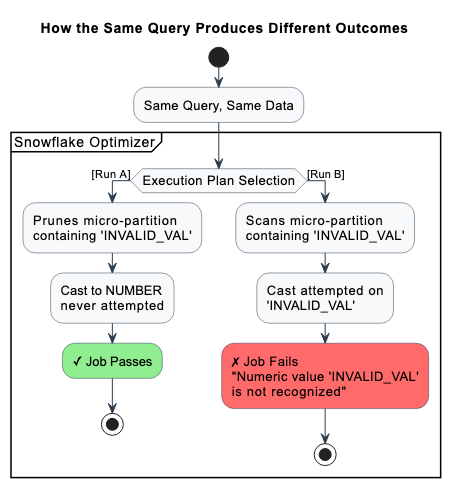
But buried somewhere in that events table is a single row where event_key = 'INVALID_VAL'. It has been there for months. Nobody noticed because it never caused a problem.
Here's why: on most runs, Snowflake's optimizer prunes away the micro-partition containing that row before the cast is ever attempted. The query completes without incident. The problematic value is never touched.
Then one day, the optimizer picks a different plan. Maybe the warehouse was busier. Maybe a stats refresh shifted the pruning boundaries. Maybe the table crossed a size threshold. Whatever the cause, that partition gets scanned first this time. The cast is attempted. And the job dies with:
Numeric value 'INVALID_VAL' is not recognizedSame query. Same data. Same code. The error is real. The bug is not.
The Diagnostic Shift That Actually Helps
The standard debugging instinct here is exactly wrong. You pull up the SQL. You check git blame. You inspect recent loads. You are anchored to the assumption that a code defect exists, and when it doesn't, you waste hours proving a negative.
A better question to ask is: what is this query assuming about how the engine will execute it, and is that assumption guaranteed?
When you approach a failing run through that lens, the investigation changes completely. Instead of reviewing business logic line by line, you open the query profile and compare the execution plan between the failing run and the last passing one. You look for differences in operator ordering, join strategies, partition pruning behavior, and the point at which type resolution happens.
This reframes the diagnosis from "what broke in my code" to "what changed in how the engine chose to run this." That is a different investigation entirely. And it leads to fixes that actually hold.
The Fix: Make the Contract Explicit
The instinctive response to an intermittent failure is to add a retry. That solves the alert. It does not solve the problem. Worse, it hides the problem by reducing the frequency of visible failures while the underlying fragility quietly grows.
The real fix is eliminating the implicit assumption. In the join example above, that means one line:
-- Before: implicit cast, optimizer decides how and when
ON o.order_id = e.event_key
-- After: explicit cast, behavior is identical across all plans
ON o.order_id::VARCHAR = e.event_keyThis is a small change with an outsized effect. The query no longer depends on the optimizer choosing a pruning strategy that avoids the bad row. Type resolution is now the query's responsibility, not the engine's. Behavior is consistent regardless of warehouse size, concurrency, or data volume.
And here's the part that might feel counterintuitive: this fix will surface the data quality issue consistently. Every run will now encounter that INVALID_VAL row and handle it predictably. If it is genuinely bad data, you want to know about it on every run, not discover it randomly once a quarter when the optimizer happens to scan the wrong partition first.
Building Pipelines That Don't Depend on Luck
Type coercion in joins is the most common source of false failures, but the principle extends further. Anywhere your SQL relies on implicit behavior, behavior the engine provides by convention rather than by contract, you have a latent failure waiting for the right conditions.
A few practices that materially reduce this risk in dbt and Snowflake environments:
Cast early and cast explicitly. Use your dbt staging models to lock down column types at the source layer. A staging model that casts event_key::VARCHAR explicitly means every downstream model inherits that contract. No one has to guess. No one has to re-cast.
Test join columns at the boundary. Add not_null, accepted_values, or custom schema tests on columns that participate in join conditions. These run before your models execute. They catch data quality problems at the source, not when they surface as cryptic execution-layer errors three models downstream.
Treat intermittent failures as debt, not noise. Any job that fails occasionally without a corresponding code change is carrying hidden technical debt. Do not normalize it with retries. Schedule a real investigation. The failure rate will increase over time as data grows and execution plans shift more aggressively.
Use the query profile before you use git blame. When a failure cannot be explained by code review, the Snowflake query profile is your next stop. Compare failing and passing runs side by side. If the plans diverge meaningfully, you are almost certainly looking at a false failure.
Why This Gets Worse Over Time
There is a scaling dimension to this problem that makes it urgent rather than merely interesting. At low data volumes, Snowflake's optimizer tends to be more consistent in its plan selection. The search space is smaller. The pruning decisions are more predictable.
As tables grow into the hundreds of millions or billions of rows, execution plans shift more aggressively and more frequently. Thresholds get crossed. Statistics change faster. The optimizer explores more alternatives. Every implicit assumption that has been quietly tolerated at small scale becomes increasingly likely to be exposed at large scale.
This means the pipeline that "works fine" today with a 2% intermittent failure rate will not stay at 2%. It will drift upward as your data grows, and by the time it becomes a serious operational problem, you will have dozens of models carrying the same class of hidden assumption.
The Mental Model Worth Adopting
Write your SQL as if the optimizer will always find the most inconvenient execution path. Assume it will scan the partition you hoped it would skip. Assume it will cast the side you didn't expect. Assume the plan will change tomorrow.
If your query breaks under those assumptions, the query needs to be more explicit. Not the optimizer more predictable.
A query that works because the optimizer happens to avoid a problematic data path is not a correct query. It is a lucky one. And luck is not an engineering strategy.
The Takeaway
False failures in dbt and Snowflake pipelines are not random. They are not gremlins. They are the predictable result of implicit assumptions meeting a dynamic execution engine that satisfies those assumptions by coincidence rather than by obligation.
Recognizing this pattern, and separating it from genuine code bugs, is one of the most valuable diagnostic skills you can develop working in modern cloud data environments.
Next time your pipeline fails and the code looks clean: stop auditing the logic. Start auditing the assumptions. Find what your query relies on implicitly. Make it explicit. Build tests that enforce it at the data layer, before the execution engine ever gets the chance to surprise you.
Your code was fine. Your contract with the engine wasn't. Now you know the difference.
Opinions expressed by DZone contributors are their own.
Comments