Agentic AI with Bedrock and DynamoDB Integration
This article walks through how to build an Agentic AI customer service agent using Amazon Bedrock, DynamoDB, and AWS Lambda via Boto3.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
Modern banking is rapidly moving toward intelligent, context-aware automation. Instead of relying solely on static rule-based chatbots or hard-coded APIs, today’s systems need to understand intent, reason across multiple data sources, and deliver personalized insights in real time. This is where Agentic AI — autonomous systems capable of planning, reasoning, and taking action — is transforming customer interactions.
In this article, we’ll explore how to build a customer service agent that leverages Amazon Bedrock and Amazon DynamoDB, powered by Boto3, to deliver dynamic responses such as:
- Retrieving personalized banking offers from a knowledge base.
- Detecting duplicate transactions or anomalies across accounts.
- Maintaining contextual memory across multi-turn conversations for continuity.
While AWS Bedrock provides secure access to foundation models such as Claude 3 and Titan Text for reasoning and natural language understanding, DynamoDB serves as the agent’s persistent memory layer, storing query context, session history, and transaction summaries. Together, they enable the agent to recall previous interactions, infer intent, and execute logic-driven decisions — the key pillars of Agentic AI.
In the sections that follow, we’ll walk through how to:
- Connect to Bedrock and DynamoDB using Boto3.
- Design an Agentic AI loop that queries a knowledge base, interprets results, and reasons over them.
- Persist and retrieve conversation state for memory-driven behavior.
- Implement practical use cases such as checking duplicate transactions and fetching bank offers with minimal latency.
By the end, you’ll have a working prototype of a Bedrock-powered AI agent that can think, remember, and respond like a human banking assistant — securely deployed on AWS and ready for enterprise-scale integration.
Abstract
This article presents a practical implementation of an Agentic AI system powered by Amazon Bedrock. It integrates a Bedrock base model (Titan) with Amazon DynamoDB to handle real-time data. The solution is showcased through a lightweight Streamlit UI, leveraging LangChain capabilities to enable context-aware conversations.
System Architecture:
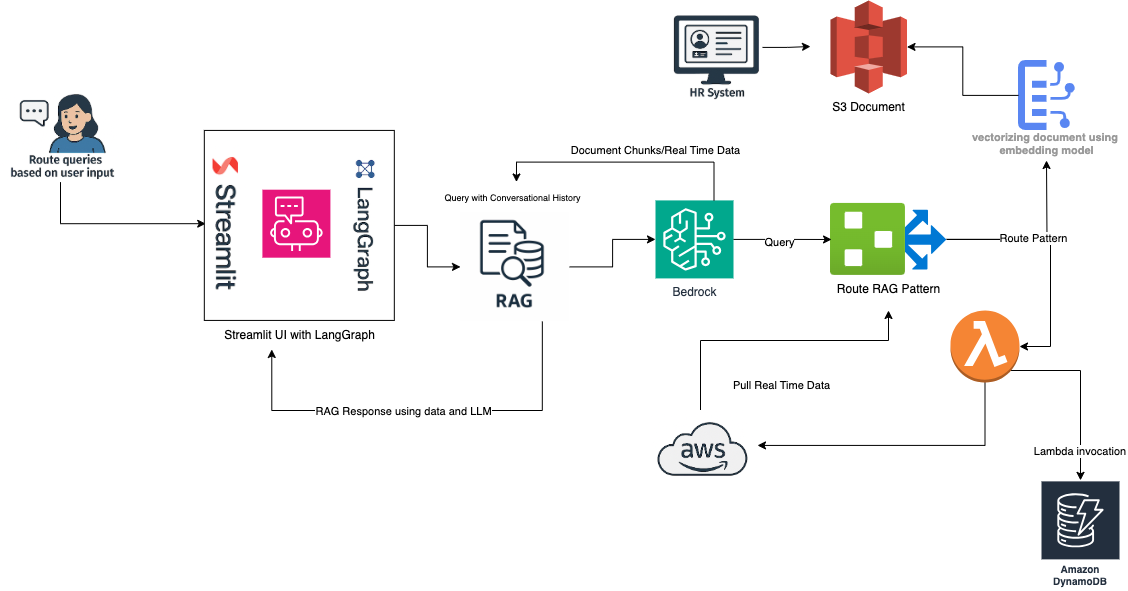
Fig. 1: Detailed Implementation using RAG, LangGraph implementation.
Built using Boto3, the official AWS SDK for Python, this system demonstrates how to combine foundation AI models with real-time backend data and make a contextually aware chatbot to enable intelligent, responsive behavior. Key components include:
- Amazon Bedrock for invoking advanced LLMs like Claude and Titan with secured, managed infrastructure.
- Amazon routing agents to support Retrieval Augmented Generation (RAG), allowing the agent to ground its responses in relevant, structured knowledge.
- Amazon DynamoDB to ingest and serve real-time operational data, which the agent references during task execution.
- Streamlit for a simple yet powerful UI that lest users interact with the agent and observe real-time data usage.
- LangChain to simplify the development and deployment of LLM-powered applications.
This architecture enables the development of a responsive AI agent that can access up-to-date information during conversation or task execution — making it suitable for use cases like a support bot, monitoring dashboard, or operational assistance.
Tags: AI, AgenticAI, Bedrock, Langchain, DynamoDB
Architecture Overview
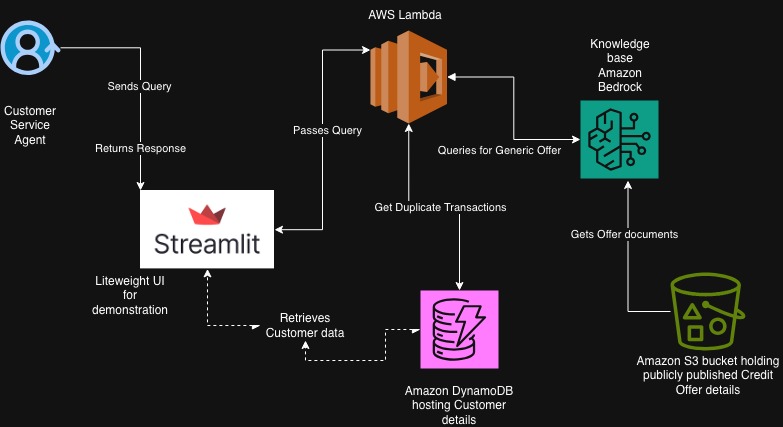
Fig.2: Use Case we are building.
The architecture showcases how a Customer Service Agent interacts with a cloud-native Agentic AI system built using Amazon Bedrock, DynamoDB, AWS Lambda, and Streamlit. The design focuses on enabling intelligent, real-time responses to customer queries such as “What credit offers are available for me?” or “Do I have duplicate transactions this month?”
The workflow follows a modular and event-driven design, ensuring scalability, low latency, and contextual continuity.
1. Customer Service Agent Interface (Streamlit UI)
The Streamlit component acts as a lightweight, browser-based UI for demonstration.
- The agent or end-user enters a natural-language query — e.g., “Check duplicate transactions for customer ID 12345.” Streamlit sends the request to a backend Lambda function via a REST API call.
- When the AI finishes reasoning, Streamlit shows the structured response (such as offers, flags, or recommended actions).
This layer is intentionally simple for prototyping, but can be replaced with an internal CRM interface, chatbot, or voice assistant in production.
2. AWS Lambda — Orchestration and Reasoning Layer
AWS Lambda acts as the central orchestrator connecting multiple AWS services.
- It receives the request from Streamlit, parses the intent, and dynamically decides the query type — offer inquiry or duplicate check.
- For offer lookups, Lambda queries Amazon Bedrock’s Knowledge Base (see below) to retrieve contextually relevant marketing or credit-card offers.
- For duplicate-transaction checks, Lambda queries Amazon DynamoDB to retrieve and compare customer transaction data.
- The reasoning loop (plan → query → respond) is managed entirely in Python using Boto3, allowing fine-grained control over Bedrock prompts and DynamoDB queries.
This serverless pattern removes the need for long-running backend servers and scales automatically with incoming traffic.
3. Amazon Bedrock — Reasoning and Knowledge-Retrieval Engine
Amazon Bedrock provides the LLM reasoning core of the architecture.
-
The Lambda function calls a Bedrock model such as Claude 3 Sonnet or Titan Text Express through the Boto3 SDK.
-
Bedrock’s Knowledge Base feature is configured to index and embed offer-related documents (for example, credit-card reward summaries, APR policies, or limited-time promotions).
- When a query like “Show me the best cashback offers for my profile” is received, Bedrock retrieves the top relevant chunks from its knowledge base and generates a natural-language summary that the agent can directly relay to the customer.
This combination provides contextual retrieval + generative reasoning, enabling fact-driven yet conversational responses.
4. Amazon DynamoDB — Agent Memory and Customer Data Store
DynamoDB stores all customer-specific data, such as profile details, transaction logs, and session history.
- It enables the AI agent to persist memory between conversations — critical for the Agentic AI loop.
- For duplicate-transaction detection, Lambda runs DynamoDB queries to fetch recent transactions for a given customer_id and then compares timestamps, amounts, and merchant codes to identify potential duplicates.
- This memory layer can also hold session context (e.g., “Customer asked for offers 5 minutes ago”) to personalize responses.
DynamoDB’s low-latency read/write performance ensures near real-time responsiveness even under heavy query loads.
5. Amazon S3 — Knowledge Base Document Source
Amazon S3 acts as the document repository for Bedrock’s Knowledge Base.
- Banking and marketing teams can upload offer PDFs, product sheets, and promotional documents into a designated bucket.
- Bedrock continuously indexes these documents and converts them into embeddings for semantic search.
- When a user requests an offer summary, Bedrock pulls the relevant vector embeddings from S3-backed content and crafts the response.
This approach provides a secure, easily maintainable knowledge source that non-technical teams can update without redeploying code.
6. Data Flow Summary
Customer Service Agent (Streamlit) sends a query.
- Lambda receives it, detects intent, and routes accordingly.
- For offer queries => Lambda invokes Bedrock Knowledge Base, which fetches relevant offer content from S3.
- For duplicate-transaction queries => Lambda queries DynamoDB for the customer’s recent records and uses Bedrock to summarize the analysis.
The final structured response is returned to Streamlit, completing the reasoning loop.
Advantages of This Architecture:
- Serverless scalability: Fully event-driven through Lambda.
- Persistent memory: DynamoDB retains agent state and customer data.
- Knowledge grounding: Bedrock KB ensures responses are sourced from verified documents.
- Rapid prototyping: Streamlit provides an instant front-end for demonstrations.
- Separation of concerns: Reasoning (Bedrock), orchestration (Lambda), and data (DynamoDB + S3) are cleanly decoupled.
Example Scenario:
- A customer asks, “Can you show me current credit-card offers and check if I’ve been charged twice for the same merchant?”
- The agent UI forwards the query to Lambda, which invokes Bedrock to retrieve promotional data from its knowledge base and concurrently checks DynamoDB for duplicate transaction patterns. The combined response — validated offers plus a transaction check summary — is sent back instantly to the agent dashboard.
Implementation
1. ** Prerequisites **
AWS Services: Bedrock (knowledge base enabled), DynamoDB, S3, Lambda
Python 3.9 + and dependencies
pip install boto3 streamlit
IAM Permissions
bedrock:InvokeModel
bedrock:Retrieve
dynamodb:PutItem / GetItem / Query
s3:GetObject
2. Initialize Boto3 Clients
import boto3
region = "us-east-1"
bedrock = boto3.client("bedrock-runtime", region_name=region)
dynamodb = boto3.resource("dynamodb", region_name=region)
table = dynamodb.Table("transactions")
s3 = boto3.client("s3", region_name=region)
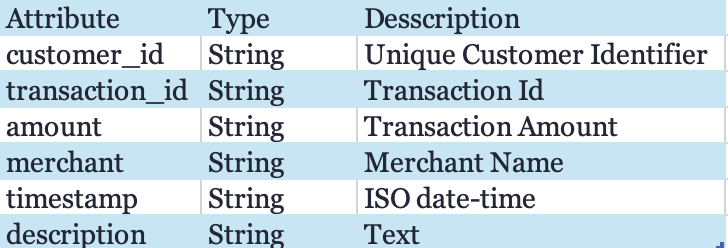
3. DynamoDB Schema Design:
Table Name: CustomerTransactions
Partition Key: customer_id (String)
Sort Key: txn_id (String or UUID)
4. Querying DynamoDB:
from boto3.dynamodb.conditions import Key
def find_duplicate_txns(customer_id: str, amount: float, merchant: str):
response = table.query(
KeyConditionExpression=Key('customer_id').eq(customer_id)
)
txns = response['Items']
duplicates = [
t for t in txns
if t['merchant'] == merchant and abs(t['amount'] - amount) < 0.01
]
return duplicates
5. Retrieve Offer via Bedrock Knowledge Base
def query_bedrock_offers(customer_profile: str, query: str):
body = {
"input": query,
"knowledgeBaseId": "kb-1234567890", # your KB ID
"retrievalConfiguration": {"type": "VECTOR"},
"modelId": "anthropic.claude-3-sonnet"
}
response = bedrock.invoke_model(body=body, modelId="anthropic.claude-3-sonnet")
answer = response["body"].read().decode("utf-8")
return answer6. Combine Reasoning and Data — Lambda
import json
def lambda_handler(event, context):
body = json.loads(event['body'])
query = body.get('query')
customer_id = body.get('customer_id')
if "offer" in query.lower():
response_text = query_bedrock_offers(customer_id, query)
elif "duplicate" in query.lower():
duplicates = find_duplicate_txns(customer_id, amount=200.0, merchant="Amazon")
response_text = f"Found {len(duplicates)} potential duplicate transactions."
else:
response_text = "Sorry, I couldn't recognize or interprit your query."
return {
"statusCode": 200,
"body": json.dumps({"response": response_text})
}
7. Streamlit Frontend
import requests
import streamlit as st
st.title("AI-Powered Banking Customer Service Agent")
customer_id = st.text_input("Customer ID", "CUST123")
query = st.text_area("Enter query", "Show me available credit offers")
if st.button("Ask"):
payload = {"customer_id": customer_id, "query": query}
resp = requests.post("https://aws-lambda-api-url", json=payload)
st.success(resp.json()["response"])Example:
-
The agent enters: “Check for duplicate transactions for CUST123.”
-
Streamlit sends the query to Lambda.
-
Lambda detects intent → runs
find_duplicate_txns()→ returns summary. -
The agent asks: “Now show available credit offers.”
-
Lambda invokes
query_bedrock_offers()→ Bedrock retrieves context from KB → returns offer list. -
Streamlit displays the final response in seconds.
Conclusion
Agentic AI marks a new phase of intelligent automation in the financial industry — moving from simple chatbots to autonomous reasoning systems that understand intent, retrieve verified data, and deliver actionable insights.
By combining Amazon Bedrock for language reasoning, DynamoDB for persistent agent memory, and AWS Lambda for orchestration, developers can create stateful AI agents capable of handling real-world banking scenarios like offer recommendations, duplicate transaction checks, or contextual financial insights.
This architecture is:
Scalable — serverless compute and on-demand storage
Secure — AWS-native IAM and encryption controls
Extensible — ready for multi-agent or event-driven workflows
As cloud-native AI continues to evolve, the integration of reasoning (Bedrock), memory (DynamoDB), and knowledge grounding (S3 + Bedrock KB) will form the backbone of next-generation AI-driven customer service platforms — empowering agents to think, remember, and respond with true contextual intelligence.
Opinions expressed by DZone contributors are their own.
Comments