AI Agents Expose a Design Gap in Microservices Resilience Architecture
Microservices assume predictable callers. AI agents break this with non-deterministic calls, fan-out, and retries. Here are 5 core assumption breaks and fixes.
Join the DZone community and get the full member experience.
Join For FreeMost teams deploying AI agents focus their attention on prompt engineering, tool design, and LLM reliability. What receives far less attention is the microservices architecture that those agents operate against, carefully built and hardened long before any agent existed.
That architecture rests on assumptions that have held true for years. The services and clients making requests are finite and well understood. Traffic patterns are predictable. Call sequences are bounded. Retry behavior is controlled. These assumptions shaped every rate limit, every circuit breaker threshold, every idempotency decision, and every capacity plan across the system.
AI agents violate all of these assumptions simultaneously, and in most organizations, the infrastructure has not been updated to account for that.
A reasonable objection is that agents are being deployed widely, and systems appear to be running fine. The answer is twofold:
- First, most agent deployments today operate at low concurrency, where violations are invisible. Ten concurrent agent sessions generate friction that existing infrastructure absorbs without complaint, while ten thousand concurrent sessions expose the same friction as a structural failure. Load testing validates known traffic patterns, but agent-generated traffic introduces call sequences that are non-deterministic and structurally different from anything a load test written before agent deployment would have modelled.
- Second, when failures do occur, they are misdiagnosed. An agent-generated retry storm surfaces in an incident report as an unexpected traffic spike or a circuit breaker trip. The root cause gets attributed to infrastructure, not to the agent as an uncharacterized caller class.
This article is not an argument that agents and microservices are incompatible. It is an argument that the resilience infrastructure around those microservices was calibrated for a different class of caller, and that calibration needs to be updated before scale makes the update reactive rather than proactive.
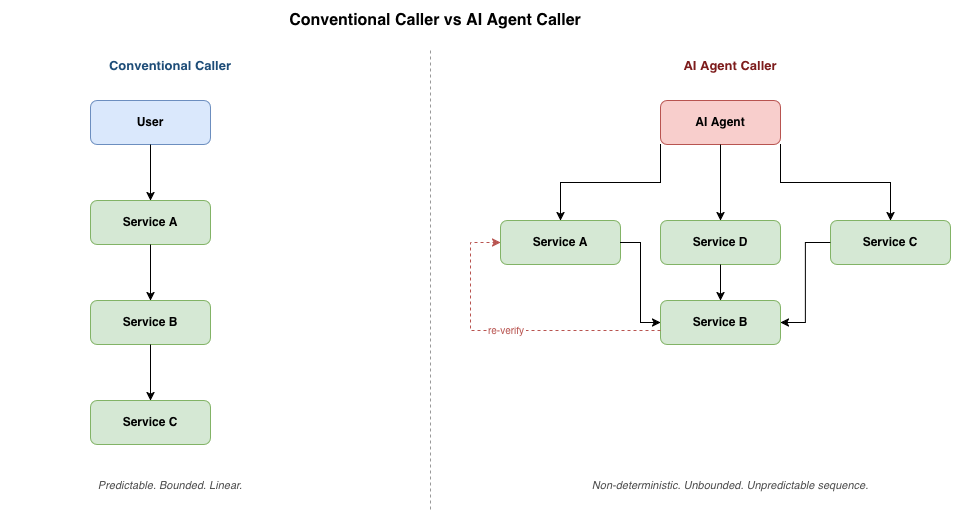
Assumption 1: Callers Are Predictable
Microservices are designed around the expectation that callers behave in known ways. A human user clicking a button triggers a defined call graph. Rate limits are tuned to match expected volumes from known clients.
An AI agent is a non-deterministic caller. To fulfill a single instruction such as "process this customer complaint and issue a refund if appropriate," an agent might call the order service, then the customer service, then the order service again to re-verify, then the refund service. The sequence changes with every invocation, depending on what the model reasons at each step. No capacity model anticipated this. No rate limit was tuned for it.
Assumption 2: Fan-Out Is Bounded
Every microservices architecture has an implicit fan-out budget. Teams know that one inbound request produces roughly N downstream calls and size their services accordingly. This budget is embedded in thread pool sizes, connection pool limits, and database connection counts.
An AI agent has no concept of a fan-out budget. A single agent session can produce dozens of downstream service calls while pursuing a goal. At a modest scale, this creates a multiplier effect that shatters the sizing assumptions baked into the infrastructure. Five hundred concurrent agent sessions, each making twenty service calls, produce ten thousand downstream requests against services sized for five hundred. The requests are legitimate, authorized, and will proceed until something breaks.
Assumption 3: Retry Behavior Is Controlled
In a well-designed system, retry behavior is explicitly defined. The team wrote the retry logic, chose the backoff strategy, and set the maximum retry count. The infrastructure knows what happens when a downstream service degrades.
AI agent frameworks introduce retry behavior that operates independently of application-level retry configuration. The agent framework retries failed tool calls. The service client retries failed HTTP calls. The API gateway retries failed upstream requests. When an agent encounters a slow downstream service, three independent retry mechanisms can fire simultaneously, none aware of the others. A single tool call that encounters a timeout can generate twenty-seven actual requests to the downstream service before any human is aware that a problem exists.
Assumption 4: Idempotency Is a Selective Design Choice
Microservices teams make deliberate decisions about which operations require idempotency. Payment creation is idempotent. Inventory reservation may or may not be, depending on the team's assessment of retry likelihood.
An AI agent does not retry only on failure. It re-executes operations as part of its reasoning process. An agent checking inventory twice in a single session is normal behavior, not an error condition. This changes idempotency from a selective design choice to a universal constraint. Every API endpoint exposed as an agent tool must be idempotent without exception, regardless of how unlikely repeated execution seemed at the time it was designed.
Assumption 5: Timeout Budgets Hold at the System Level
Microservices are built around timeout budgets. Teams design individual service timeouts so that cumulative worst-case latency across a call chain fits within an acceptable end-to-end response time.
An AI agent does not have a latency budget. It has a goal and will chain as many service calls as it determines necessary to achieve that goal. A reasoning loop involving eight service calls, each with a 500ms timeout, can accumulate four seconds of latency. Individual service timeouts remain within their configured bounds. The system-level latency contract is broken nonetheless.
Why Existing Infrastructure Is Necessary but Not Sufficient
Teams with mature service mesh and API gateway infrastructure will note that per-client rate limiting and retry budget enforcement are already available at the infrastructure level. Those capabilities are valuable but address the problem only partially.
Service mesh rate limiting operates on request volume per client identity. It does not understand agent session semantics or cumulative fan-out across multiple services. A rate limiter capping a client at 100 requests per second will allow an agent session to generate 100 calls per second to each of ten different services, producing 1,000 downstream requests per second from a single session without tripping any per-service limit.
Gateway-level retry enforcement controls retries that pass through the gateway. It does not control retries fired within the agent framework, which occur before the request reaches the gateway. The most dangerous retry amplification happens at layers that the gateway cannot see.
Existing infrastructure provides the foundation. What is missing is the agent-awareness layer built on top of it.
What Needs to Change
Addressing these violations does not require replacing existing resilience infrastructure. It requires targeted extensions.
Agent-scoped rate limiting. Rate limits must be applied at the agent session level, capping the total downstream calls a single session can generate across all services, not just per service.
Universal idempotency for agent-exposed tools. Every API endpoint registered as an agent tool must be treated as idempotent regardless of its original design. This constraint needs to be encoded in tool registration standards.
Separate circuit breaker profiles for agent traffic. Agent-generated traffic has structurally different latency and volume characteristics from human-generated traffic. Mixing the two in a single circuit breaker configuration produces thresholds that protect neither class of traffic adequately.
Session-level timeout budgets. Individual service timeouts are insufficient when the agent orchestration layer has no concept of a total time budget. The agent runtime must enforce a session-level timeout that constrains the entire reasoning loop.
Agent call graph observability. Standard distributed tracing surfaces individual spans. What is needed for agent traffic is visibility into how many downstream calls a single session generates, which services were called, and in what sequence.
Conclusion
The resilience patterns that microservices teams rely on were designed with a specific class of caller in mind. That caller was bounded, predictable, and operating within known behavioral parameters. AI agents are a fundamentally different class of caller, and the gap between their behavior and the assumptions embedded in existing infrastructure is real, consequential, and currently masked by deployment scale rather than resolved by design.
The required changes are targeted extensions to existing patterns, not rewrites. Treating AI agents as a distinct traffic class with its own rate limits, circuit breaker profiles, idempotency requirements, and observability model is what separates a resilient agent deployment from one that is waiting to fail at scale.
Opinions expressed by DZone contributors are their own.
Comments