Aggregation Strategies for Scalable Data Insights: A Technical Perspective
This blog compares Elasticsearch aggregations: Sampler (fast), Composite (efficient), and Terms (for categories). Choose based on your data and performance needs.
Join the DZone community and get the full member experience.
Join For FreeElasticsearch is a cornerstone of our analytics infrastructure, and mastering its aggregation capabilities is essential for achieving optimal performance and accuracy. This blog explores our experiences comparing three essential Elasticsearch aggregation types: Sampler, Composite, and Terms. We’ll evaluate their strengths, limitations, and ideal use cases to help you make informed decisions.
The Power of Aggregation in Elasticsearch
Elasticsearch aggregations offer a powerful means of summarizing and analyzing data. They allow us to group documents into buckets based on specific criteria and then perform calculations on those buckets. This is essential for tasks like:
- Identifying trends: Discovering common categories or patterns in data.
- Understanding distributions: Analyzing how data is spread across different groups.
- Improving performance: Optimizing queries and reducing the amount of data processed.
Choosing the right aggregation type is critical for efficiency. Let’s examine each in detail.
Sampler Aggregation: Speed Over Precision
The Sampler aggregation is designed to improve performance by operating on a subset of your data. Instead of processing the entire dataset, it selects a sample of documents and performs aggregations on that sample.
The Engineering Backstory
Sampler aggregations are particularly effective for quickly exploring large datasets where full precision is not mandatory. In practice, these aggregations have been used to reduce the scope of queries during early-stage analysis and performance testing, especially when high latency is a concern.
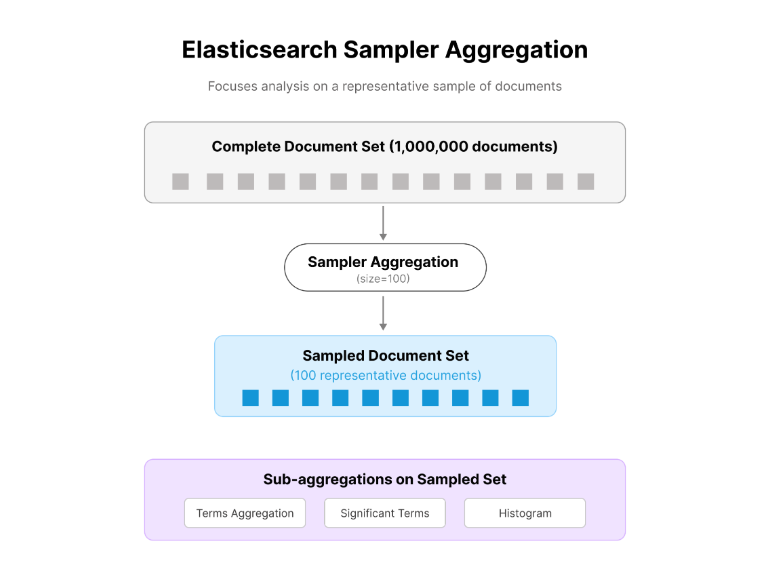
Internal Workflow in Elasticsearch Sampler Aggregation
When to Use
- Exploratory analysis: Quickly get a sense of the data without the overhead of processing everything.
- Performance optimization: When aggregations on the entire dataset run too slowly.
public void executeSamplerAggregation(ElasticsearchClient client)
throws IOException {
SearchResponse<Void> response = client.search(s -> s
.size(0)
.aggregations(“sampled_data”, a -> a
.sampler(sa -> sa.shardSize(1000)
.aggregations(“avg_reach”, avg -> avg.avg(v ->
v.field(“reach”)))))
), Void.class);
System.out.println(response.aggregations());
}Pros
- Significant performance gains: Achieved by limiting the number of documents processed.
- Useful for quick exploration: of large datasets.
Cons
- Approximate results: Since this aggregation uses only a sample, the results may not fully reflect the entire dataset.
- Reduced accuracy over large data ranges: Sampling can be less accurate when analyzing data over extended periods.
Composite Aggregation: Pagination for Massive Datasets
The Composite aggregation is built for efficient pagination of large aggregation results. Unlike the Terms aggregation, Composite allows you to iterate through buckets using the after parameter, making it ideal for handling massive datasets.
Engineering Backstory
Composite aggregation has become a preferred choice for managing large aggregations that require pagination and efficient memory usage. Composite is known to help mitigate bucket overflow issues that commonly occur with Terms aggregation, especially when handling high-cardinality fields across wide date ranges.
Internal Workflow in Elasticsearch Composite Aggregation
When to Use
- Pagination: Efficiently navigating through large aggregation result sets.
- Memory efficiency: A more memory-friendly alternative to the Terms aggregation.
public void executeCompositeAggregation(ElasticsearchClient
client) throws IOException {
SearchResponse<Void> response = client.search(s -> s
.size(0)
.aggregations(“composite_agg”, a -> a
.composite(ca -> ca.size(1000)
.sources(“source_name”, src -> src.terms(t ->
t.field(“source.name.keyword”)))
.sources(“reach”, src -> src.histogram(h ->
h.field(“reach”).interval(50)))))
), Void.class);
System.out.println(response.aggregations());
}Pros
- Efficient pagination: For large datasets.
- Uses less memory: Than the Terms aggregation.
Cons
- Complexity: Implementation can be more complex due to the need for pagination handling.
- Bucket Limit Errors: You may still hit Elasticsearch’s bucket size limits, even with smaller page sizes.
- Merging Complexity: Requires manual merging of sub-aggregation results when using nested aggregations.
Terms Aggregation: Categorical Analysis Workhorse
The Terms aggregation is one of the most common and straightforward ways to group documents based on the unique values of a field, and it is perfect for analyzing categorical data.
Engineering Backstory
In practical applications, term aggregation is often used for categorical analysis where datasets are manageable in size or have low cardinality. Issues such as bucket limit exceptions can arise with large data volumes; however, filtering and query splitting have proven effective in mitigating these challenges.
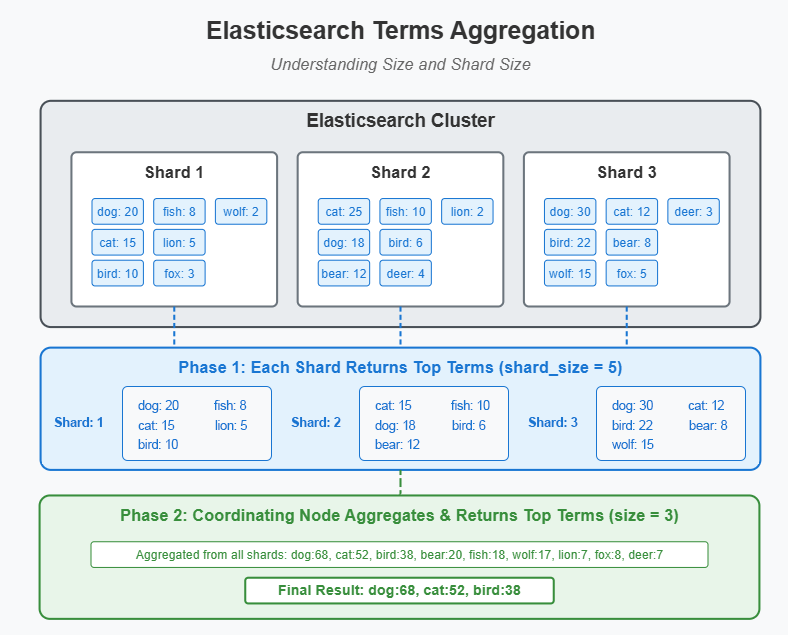
Use Case
- Categorical analysis: Finding the most frequent categories, tags, or labels.
- Distribution analysis: Understanding how data is distributed across different groups.
Example (Java – without filter)
public void executeTermsAggregation(ElasticsearchClient client)
throws IOException {
SearchResponse<Void> response = client.search(s -> s
.size(0)
.aggregations(“popular_sources”, a -> a
.terms(t -> t.field(“source.name.keyword”).size(10)))
), Void.class);
System.out.println(response.aggregations());
}Example (Java – with filter)
public void executeTermsAggregation(ElasticsearchClient client)
throws IOException {
SearchResponse<Void> response = client.search(s -> s
.size(0)
.aggregations(“filtered_terms”, a -> a
.filter(f -> f.term(t ->
t.field(“companyDetails.keyword”).value(“TechCompany”)))
.aggregations(“popular_sources”, subAgg -> subAgg
.terms(t ->
t.field(“source.name.keyword”).size(10)))))
), Void.class);
System.out.println(response.aggregations());
}Pros
- Simple and easy: to use for counting unique values.
- Effective for smaller datasets: and low-cardinality fields.
Cons
- Memory Consumption: It can consume a significant amount of memory for high-cardinality fields with many unique values.
- No Built-in Pagination: Lacks built-in pagination support, making it less suitable for huge result sets.
Lessons from Implementation
Through hands-on development, the following observations emerged:
- Composite Aggregations: When using Composite Aggregations for pagination, we encountered “Bucket Limit Errors” even with reduced page sizes. Manually merging sub-aggregation results also increased the implementation complexity.
- Sampler Aggregation: Provided fast results but lacked the accuracy we needed when aggregating over larger date ranges. The inherent approximation was a limiting factor.
- Terms Aggregation: Initially, the queries returned “Bucket Limit Errors” when requesting a month’s data. We found that reducing the size parameter and splitting large queries into multiple smaller, range-based queries resolved the issue. Adding a filter to mitigate unique terms in a high-cardinality field was helpful, and always use nested aggregation if there are nested fields.
Key Takeaways
- Composite Aggregation: This is powerful for pagination, but complex and not immune to bucket errors.
- Sampler Aggregation: Useful for quick performance gains, but sacrifices accuracy.
- Terms Aggregation: Proper tuning (smaller size, query splitting, filters) provides the best balance of accuracy and performance.
Aggregation Strategy: Cheat Sheet
| Aggregation | Best For | Advantages | Limitations |
|---|---|---|---|
| Sampler Aggregation | Sampling data for exploratory analysis | Improves performance, useful for quick insights | Results are approximate and inaccurate for large date ranges |
| Composite Aggregation | Paginating over large aggregation results | Efficient pagination, lower memory usage | Still encountered bucket limit errors and complex merging of sub-aggregations |
| Terms Aggregation | Grouping by unique values |
Simple and effective for low-cardinality fields, high accuracy | High memory usage requires tuning for large queries |
Engineering Best Practices
- Tune your queries: Adjust the size parameter and split large queries into smaller ones.
- Apply filters: Reduce the number of unique terms in high-cardinality fields.
- Test thoroughly: Validate your results and monitor performance.
By aligning your aggregation approach with your data characteristics and performance goals, you can transform aggregation from a bottleneck into a performance lever.
Final Thoughts: Build, Test, Tune
Choosing the right aggregation in Elasticsearch is crucial for efficient and accurate data analysis. Our experience highlights the importance of understanding the strengths and limitations of each type. While the Sampler aggregation can provide quick insights, it sacrifices accuracy. The Composite aggregation offers efficient pagination but introduces complexity. The Terms aggregation, when optimized, provides the best balance of accuracy and performance.
Published at DZone with permission of Navedha Sadhan. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments