Building AI-Driven Anomaly Detection Model to Secure Industrial Automation
Learn to build an AI model for anomaly detection in industrial automation—a case study using LSTM as a feature extractor and Decision Tree as a classification model.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
In modern industrial automation, security is a primary requirement to keep the regular operation of industrial connected devices without disruption. However, the rise of cyber risks also significantly impacts the industry’s sustainable operation. The evolving cyberattacks can affect the overall industrial systems that control industrial processes and systems. Modern attacks are more targeted and designed to evade detection by traditional defensive approaches. A proactive approach is necessary, rather than a defensive strategy, to tackle these evolving cyber threats. This article presents a use case for building an anomaly detection framework using artificial intelligence (AI). More specifically, a hybrid learning model consisting of a deep learning LSTM model for feature extraction and a machine learning (ML) classifier to detect and predict anomalous behavior in industrial automation.
The evolution of next-generation technologies, also known as Industry 4.0, has evolved to meet the challenges and requirements of optimal operations and efficient sustainability in industrial automation networks. In this modern era, the development of advanced mobile networks (5G), big data analytics, the Internet of Things (IoT), and Artificial Intelligence (AI) provides excellent opportunities for better and more optimal industrial operations. The integration of Mobile Network, for example, enables the seamless operation of millions of IIoT devices connected simultaneously with minimal bandwidth and low latency. However, apart from excellent opportunities, these technological paradigms also open a new door to cyber-criminals that can affect the sustainability and operations of industrial networks.
This article proposes building a robust module design for anomaly detection in industrial internet of things (IIoT) networks that allows end-to-end feature extraction and classification with minimal human intervention.
Methodology
This article presents a Proof-of-Concept (PoC) as a hybrid anomaly detection (AD) system that integrates a deep learning architecture, specifically an LSTM-Autoencoder, and machine learning Decision Tree classifiers. The developed and demonstrated AD model combines deep temporal learning with feature selection and rule-based classification. The combination of these features improves both performance and trust in IIoT cybersecurity systems.
Figure 1 illustrates the architecture of the anomaly detection framework. The architecture consists of LSTM autoencoders (AEs) to train patterns in the collected data and a decision tree (DT) model to identify anomalous patterns as deviations from ordinary patterns.
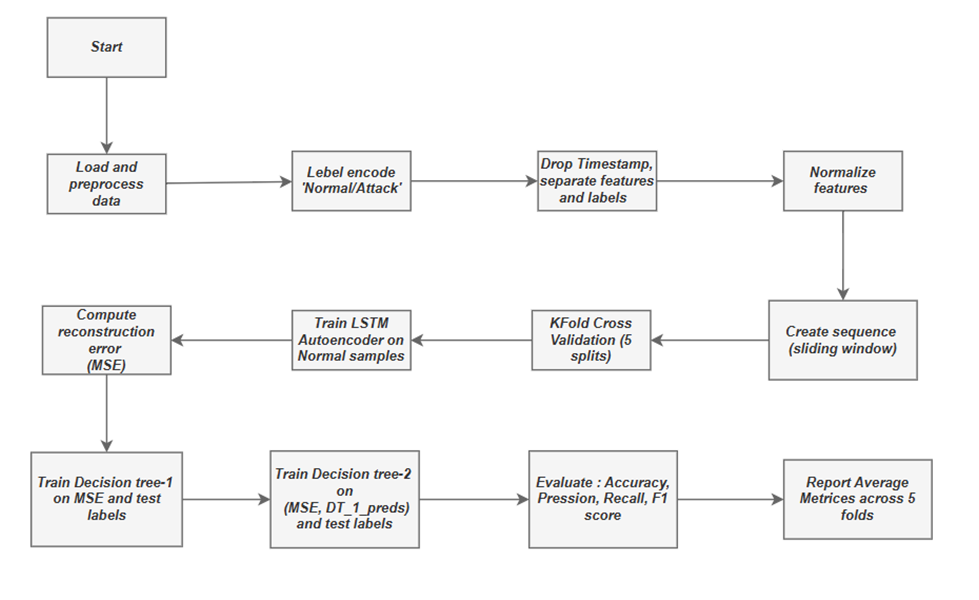
Implementation and Results
The implementation of the Anomaly Detection (AD) model uses the publicly available Secure Water Treatment testbed (SwaT) dataset. This dataset comprises 11 days of actual water plant operation, including seven days under normal conditions and four days under attack conditions. The database consists of a dataset of 26 sensors and 25 actuators, capturing snapshots every second under the specified conditions of an industrial plant.
LSTM Autoencoder + Decision Tree Ensemble for SWaT Anomaly Detection
Step 1: Import Required Libraries
Initially, the essential libraries are imported for data handling (Pandas, NumPy), preprocessing (LabelEncoder, MinMaxScaler), model building (TensorFlow/Keras), evaluation (scikit-learn metrics), and classification model (Decision Trees).
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from sklearn.model_selection import KFold
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report, accuracy_score, precision_score, recall_score, f1_score
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, LSTM, RepeatVector, TimeDistributed, DenseStep 2: Load and Preprocess Dataset
This module loads the SWaT dataset from a CSV file and encodes the labels ('Normal' and 'Attack') into numerical values (0 and 1) for model compatibility.
df = pd.read_csv("cleaned_swat_attack.csv")
le = LabelEncoder()
df["Normal/Attack"] = le.fit_transform(df["Normal/Attack"])Step 3: Label Mapping
This step prints the mapping between original string labels and encoded values for interpretability.
print("Classes:", le.classes_)
for i, label in enumerate(le.classes_):
print(f" {label} --> {i}")Step 4: Feature and Label Separation
This step separates the dataset into input features and target labels, excluding non-relevant columns such as timestamps, to provide a labeled dataset for a deep learning model.
features = df.drop(columns=["Timestamp", "Normal/Attack"])
labels = df["Normal/Attack"].valuesStep 5: Feature Normalization
The input features are scaled between 0 and 1 using "MinMaxScaler" to help neural networks train more effectively.
features_scaled = MinMaxScaler().fit_transform(features)Step 6: Create Temporal Sequences
The labeled data is transformed into sequences of time steps (e.g., 150) to allow the LSTM model to learn temporal patterns. Each sequence is associated with the label of the next time step.
def create_sequences(data, labels, time_steps=10):
X, y = [], []
for i in range(len(data) - time_steps):
X.append(data[i:i + time_steps])
y.append(labels[i + time_steps])
return np.array(X), np.array(y)
time_steps = 150
X_seq, y_seq = create_sequences(features_scaled, labels, time_steps)Step 7: LSTM Autoencoder Model Definition
This module defines an LSTM autoencoder model that compresses the input sequence (encoder) and then reconstructs it (decoder). The reconstruction error helps identify anomalies.
def build_autoencoder(time_steps, n_features, lstm_units=3):
inputs = Input(shape=(time_steps, n_features))
encoded = LSTM(lstm_units, activation='relu')(inputs)
decoded = RepeatVector(time_steps)(encoded)
decoded = LSTM(lstm_units, activation='relu', return_sequences=True)(decoded)
decoded = TimeDistributed(Dense(n_features))(decoded)
model = Model(inputs, decoded)
model.compile(optimizer='adam', loss='mse')
return modelStep 8: K-fold (K=5) Cross-Validation
The dataset is divided into five parts (K-fold validation) to train and test the Model on different subsets. The Model is trained only on 'Normal' data. Anomalies are detected based on reconstruction error using a threshold from training MSE.
kf = KFold(n_splits=5, shuffle=True, random_state=42)
metrics = {'accuracy': [], 'precision': [], 'recall': [], 'f1': []}
for fold, (train_idx, test_idx) in enumerate(kf.split(X_seq)):
print(f"\n--- Fold {fold + 1} ---")
X_train, y_train = X_seq[train_idx], y_seq[train_idx]
X_test, y_test = X_seq[test_idx], y_seq[test_idx]
X_train_norm = X_train[y_train == 0]
autoencoder = build_autoencoder(time_steps, X_seq.shape[2], lstm_units=3)
history = autoencoder.fit(X_train_norm, X_train_norm, epochs=150, batch_size=150, shuffle=True, validation_split=0.1, verbose=1)
X_test_pred = autoencoder.predict(X_test)
mse_test = np.mean(np.mean(np.square(X_test_pred - X_test), axis=2), axis=1)
X_train_pred = autoencoder.predict(X_train_norm)
mse_train = np.mean(np.mean(np.square(X_train_pred - X_train_norm), axis=2), axis=1)
threshold = np.percentile(mse_train, 95)
print(f"Threshold (95th percentile of training MSE): {threshold:.5f}")
dt1 = DecisionTreeClassifier()
dt1.fit(mse_test.reshape(-1, 1), y_test)
dt1_preds = dt1.predict(mse_test.reshape(-1, 1))
dt2_input = np.vstack([mse_test, dt1_preds]).T
dt2 = DecisionTreeClassifier()
dt2.fit(dt2_input, y_test)
final_preds = dt2.predict(dt2_input)
acc = accuracy_score(y_test, final_preds)
prec = precision_score(y_test, final_preds)
rec = recall_score(y_test, final_preds)
f1 = f1_score(y_test, final_preds)
print(f"Accuracy: {acc:.4f}")
print(f"Precision: {prec:.4f}")
print(f"Recall: {rec:.4f}")
print(f"F1 Score: {f1:.4f}")
metrics['accuracy'].append(acc)
metrics['precision'].append(prec)
metrics['recall'].append(rec)
metrics['f1'].append(f1)Step 9: Report Average Metrics
The average classification metrics over all five folds are measured and visualized to assess the model's overall performance.
print("\n=== Average Metrics across 5 folds ===")
print(f"Accuracy: {np.mean(metrics['accuracy']):.4f}")
print(f"Precision: {np.mean(metrics['precision']):.4f}")
print(f"Recall: {np.mean(metrics['recall']):.4f}")
print(f"F1 Score: {np.mean(metrics['f1']):.4f}")Conclusion
This article presents a proactive threat-hunting and anomaly detection framework that identifies anomalous patterns in Sustainable Industrial Automation systems stimulated by IoT smart devices. A combination of deep learning, i.e., LSTM-Autoencoder, and a machine learning DT algorithm, to learn proactively from the dataset and predict anomalous data, is designed. A case study is implemented using a publicly available SWaT dataset, yielding remarkable performance using a public benchmarked dataset. We believe this Proof of Concept (PoC) experiment can serve as a valuable starting point for researchers and developers to carry forward this prototype implementation for real-world industrial applications.
Opinions expressed by DZone contributors are their own.
Comments