AI Is Finding Bugs Faster Than Enterprises Can Patch — Here's What Data Security Teams Should Do
Three structural shifts enterprise data security teams should make in 2026, based on verifiable data and a decade of experience building protection products.
Join the DZone community and get the full member experience.
Join For FreeI have spent the better part of a decade building data protection products for global enterprises. Cloud DLP, CASB, SSPM, Behavior Threats, AI Access Security, ISPM, etc. The kinds of things that sit between a user, an agent, or an application and the sensitive data nobody wants to see in the wrong place. Every conversation I have had with a customer security architect this year eventually arrives at the same question. The threat landscape has clearly changed. What does that mean for the controls we already own?
This article is the analysis I have been sharing with security architects across industries who are evaluating how their data protection programs need to evolve. It is grounded in what is publicly documented, what it actually changes for enterprise data security, and where I would direct the next dollar of investment based on a decade of building these products at scale.
What Actually Shifted, With Sources
There are three publicly verifiable data points worth understanding before any control conversation makes sense.
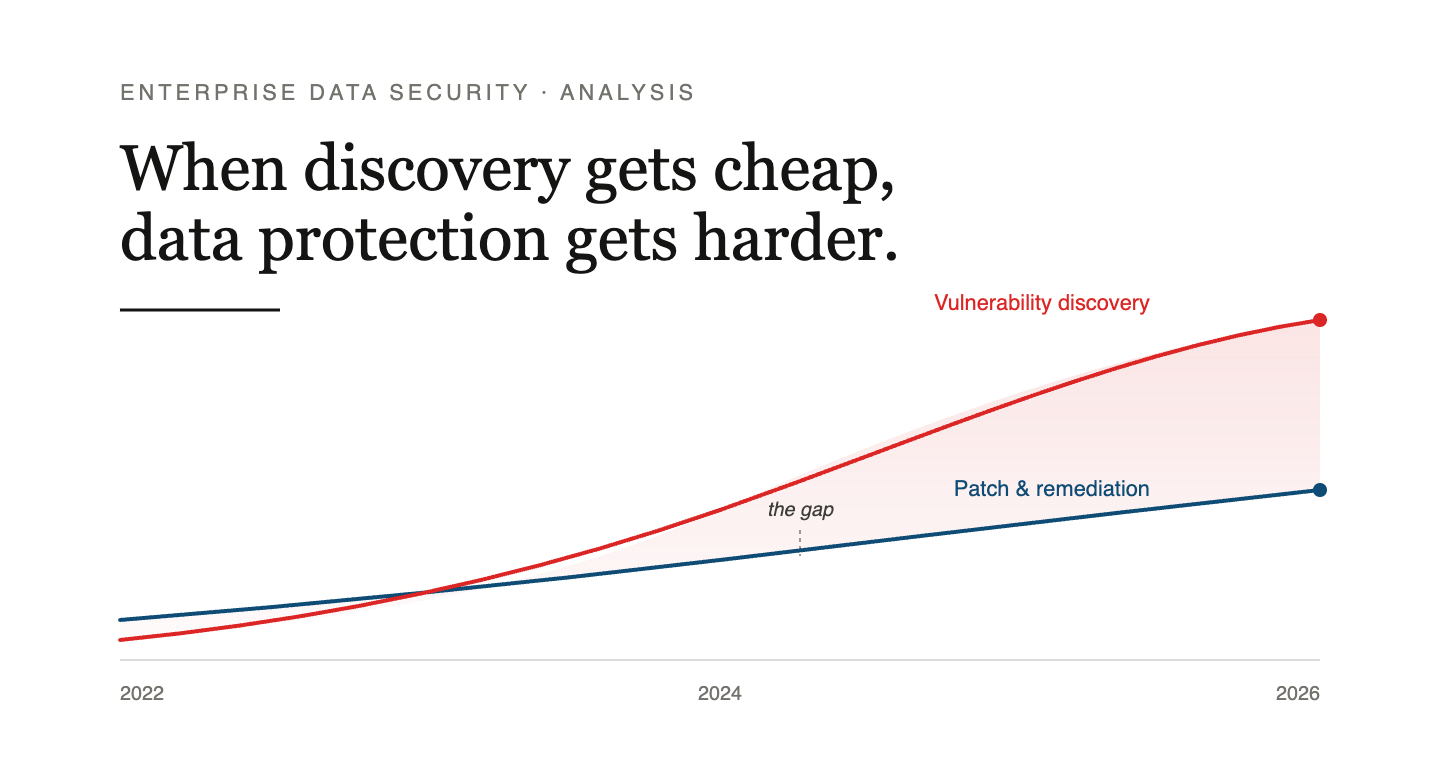
Discovery Is Becoming Inexpensive
Mozilla shipped Firefox 150 in April 2026 with two hundred and seventy-one fixes that came out of a single sweep using an early version of Anthropic’s Mythos preview model. That is roughly four times the project’s typical annual baseline, in one pass. Mozilla also added the most honest sentence I have read on this topic all year. They said they have not seen any bug in the set that an elite human researcher could not have found, given enough time. SecurityWeek covered the details: securityweek.com/claude-mythos-finds-271-firefox-vulnerabilities.
Read that caveat carefully. The thing that became automated is not novelty. It is the cost of finding a class of bugs that humans were always capable of finding. When the price of an action drops by an order of magnitude, the action gets done at scale. That is the shift, and it is the shift that matters.
Patching Is Not Getting Cheaper at the Same Rate
HackerOne paused new submissions to its Internet Bug Bounty program on March 27, 2026. The IBB is the oldest crowdsourced vulnerability reward program for open source, dating back to 2013. The pause was not a budget decision. It was an admission that the gap between AI-assisted discovery volume and the ability of volunteer maintainers to ship patches had become unbridgeable on the existing incentive model. Dark Reading’s coverage is here: darkreading.com on the IBB pause. Earlier in the year, the curl project removed bounties from its program for the same reason, after a wave of low-quality AI-generated submissions overwhelmed triage.
If the upstream open source ecosystem is struggling to keep pace with discovery, every enterprise that ships software with open source dependencies is downstream of that struggle. That is most enterprises.
Autonomous Agents Are Already Creating Real Incidents
In April 2026, the Cloud Security Alliance published two surveys that I think every data security team should read. The first study found that fifty-three percent of organizations have had AI agents exceed their intended permissions, and forty-seven percent have already experienced a security incident involving an agent in the past year. The second, published a week later, reported that eighty-two percent of enterprises have discovered previously unknown agents running in their environments, and sixty-five percent have had an agent-related incident. The most common consequence was data exposure. CSA’s findings: Enterprise AI Security Starts with AI Agents and Autonomous but Not Controlled.
Take those three threads together. Bug discovery is industrializing. The patch side is bottlenecked. And inside the enterprise, autonomous agents are already operating in places nobody fully maps. That is the operating reality, not a forecast.
Why This Matters More for Data Security Than for Any Other Function
Most of the AI security conversation is framed around vulnerabilities and exploits. I think that framing misses what is actually changing for enterprises. When a class of vulnerabilities becomes cheaper to discover, the average time between exposure and exploitation shortens. When average exposure time shortens, the probability that any given control fails inside that window goes up. When more controls fail more often, the consequence shows up at the data layer. Data is the asset. Everything else is a path to it.
The CSA finding I keep coming back to is the one that says agent incidents most often produce data exposure, not service outages. That tracks with what I see at customer sites. The blast radius of an agent compromise is determined by the data the agent had access to, the policies that were being watched, and the speed at which someone noticed. None of those three is improving on the timeline that adversaries are improving.
If an agent has access to your sensitive data, the agent is part of your data security perimeter, whether your DLP product knows it or not.
That sentence is the part of the conversation that I find most data security teams are not yet having internally. It needs to happen this quarter.
Three Things Data Security Programs Should Rethink Now
1. Stop Treating Non-Human Identities as a Hygiene Problem
CyberArk’s 2025 Identity Security Landscape, surveying 2,600 cybersecurity decision-makers globally, found that machine identities now outnumber human identities by more than 80 to 1 in the typical enterprise, up from roughly 45 to 1 in their 2024 study. GitGuardian’s State of Secrets Sprawl 2025 report found 23.8 million new secrets exposed on public GitHub in 2024 alone, a 25 percent year-over-year increase, with non-human identities flagged as the dominant credential population behind that growth. The exact ratio in any given environment is a question for the IAM team, but the order of magnitude is consistent across every serious study I have read, and it is rising fast.
Most enterprise IAM programs were designed around human users. Periodic access reviews. Quarterly attestation cycles. Manager signoff. None of that infrastructure was built for a population that is now eighty times larger, that provisions itself, and that often outlives its original use case. CSA’s research found that only 21 percent of organizations have a formal decommissioning process for AI agents. Everyone else is accumulating what the report calls retirement debt: agents who completed their task months ago and still hold credentials, tokens, and data access.
From a data security standpoint, the practical consequence is that an enterprise’s most overprivileged identity is rarely a person. It is a service account from 2022 that nobody remembers, an OAuth grant that an integration test attached to a real production scope, or a workflow agent that picked up admin-level permissions during deployment because the person setting it up did not want to debug a permission-denied error at 11 p.m. These identities are reachable by adversaries through a single credential compromise, and they often have direct access to the kinds of data that DLP policies were written to protect at the human user layer.
The remediation requires a structured non-human identity program with a named owner, a defined lifecycle covering provisioning, rotation, and decommissioning, and quarterly access reviews that apply to bots the way they apply to humans. Workload identity federation rather than long-lived secrets. Scoped service accounts. Logging that captures what each non-human identity touched, not just whether it authenticated successfully. From a tooling perspective, this work sits at the intersection of CASB, IAM, and DLP, and in most enterprises, it has no clear owner across those three functions. Establishing that ownership is the precondition for everything else.
2. Refresh Classification and Tagging for an Agentic Environment
In my own work on DLP product strategy, I have come to think of classification and tagging as the foundation that every other data control sits on. If sensitive content is correctly identified at the moment it is created or ingested, downstream policies have a fighting chance. If it is not, no amount of policy authoring downstream will catch up.
Most enterprise tagging programs were designed for documents flowing through email, endpoints, and a manageable list of SaaS applications. The current generation of AI agents and copilots flows through none of those choke points cleanly. An agent reads a corpus, generates a derivative artifact, and writes that artifact somewhere else. The original tag, if there was one, often does not survive the round trip. The derivative may contain sensitive content that was reassembled from sources that were each individually below the policy threshold.
Three practical refreshes are worth funding now.
- Treat AI-generated outputs as a first-class data class. Anything produced by an agent or copilot needs provenance metadata that travels with it: which model produced it, against which prompt, derived from which sources, with which level of human review. Most enterprise classification taxonomies do not have a slot for this yet. Add one.
- Lower the threshold for tagging at ingestion. The cost of misclassifying a sensitive document used to be that a human eventually emailed it to the wrong person. The cost now includes an agent reading it as part of a larger context and producing a derivative that lands in a SaaS workspace your DLP product does not inspect. Err on the side of more aggressive classification at the source.
- Audit your DLP coverage of LLM endpoints and agentic SaaS surfaces. Most DLP deployments I see in the field have rich coverage of email and endpoints, partial coverage of cloud applications, and almost no coverage of the LLM and agent traffic that has become a meaningful share of how sensitive data now leaves the environment. That is the coverage gap most likely to show up in a 2026 incident report.
3. Put a Model in the Pull Request Path
This is one of the few areas where the offensive shift in AI capability cuts directly in defenders’ favor, and most enterprise application security programs are not yet using it. The traditional SAST and DAST queue is where AppSec hours go to die. Thousands of unverified findings, most of them noise, validated entirely by humans on a backlog that never empties.
The newer pattern is to put a model-based reviewer in the pull request path itself. Every PR is reviewed by an automated agent for security defects before a human sees it. Findings show up as inline comments. High-confidence findings can block the merge. OpenAI publicly stated in April 2026 that its Codex Security agent has contributed to over 3,000 critical and high-severity vulnerability fixes across the ecosystem since launch, and that its Codex for Open Source program now provides free security scanning to more than 1,000 open-source projects. Anthropic, Semgrep, and several other vendors have shipped comparable capabilities. Whether you build on a commercial offering or assemble an internal pipeline, the workflow is what matters.
One nuance worth knowing about. Standard commercial models often refuse legitimate dual-use security queries by policy. Binary reverse engineering, exploit reasoning, malware analysis. If your AppSec team has been telling you that AI tools “do not work for security,” this refusal threshold is usually the reason. Both Anthropic’s Glasswing program and OpenAI’s Trusted Access for Cyber, expanded on April 14, 2026, to thousands of verified individual defenders, exist precisely to provide a lower refusal threshold for verified defensive use cases. Enterprise procurement and legal teams should start the verification paperwork now, not after a need arises.
The Supply Chain Is the Other Half of the Data Exposure Problem
Two recent incidents are worth holding in mind whenever this conversation comes up.
On September 8, 2025, eighteen widely used npm packages, including chalk, debug, and ansi-styles, were trojanized after a phishing campaign targeting the maintainer known as qix. Those eighteen packages collectively account for over 2.6 billion weekly downloads. The malicious versions were live for roughly two hours and were written to drain cryptocurrency wallets, but the same access could have been used to exfiltrate environment secrets, build credentials, or sensitive data from any CI pipeline that pulled the bad version during that window. Palo Alto Networks Unit 42 and others published detailed breakdowns: paloaltonetworks.com on the qix incident.
A week later, on September 15, 2025, the Shai-Hulud worm became the first self-propagating malware in the npm ecosystem, compromising hundreds of packages in its initial wave and continuing to evolve through follow-on campaigns into late 2025 and early 2026. The malware integrated TruffleHog to scan for secrets in compromised environments, harvested credentials from cloud instance metadata services where available, and weaponized GitHub Actions workflows for persistence. Palo Alto Networks Unit 42, ReversingLabs, Wiz, and others have continued to track variants of the same family.
The reason these matter for a data security conversation is that the attacker's objective in both cases was credentials and secrets in build environments. From there, the path to data is short. A compromised CI runner with cloud credentials can read whatever those credentials can read. A compromised GitHub token can read whatever the org allows. A compromised npm publish token can introduce a future payload that does both. Treat the build pipeline as a data security boundary, not just an engineering productivity surface. A dependency firewall that validates package provenance before installation (Sonatype Nexus Firewall, JFrog Xray, Socket.dev, or equivalents) is the highest-leverage single control I know of for closing this attack surface.
The Shadow Agent Problem Is a DLP Problem in Disguise
The single most striking statistic in the April 2026 CSA research, to me, was that eighty-two percent of organizations had discovered previously unknown AI agents in their environment over the past year, and forty-one percent had discovered them more than once. The agents most commonly emerged in internal automation and scripting environments, in custom assistants and plugins built on LLM platforms, in SaaS tools with built-in automation, and in developer-created workflows.
This is, structurally, the same problem that shadow IT was a decade ago, and the same problem that shadow SaaS became five years ago. The difference is that the average shadow agent has read access to more sensitive data than the average shadow application ever did, because agents are useful precisely in proportion to how much context they can reach. A finance team’s reconciliation agent, helpfully built in an afternoon, often ends up with broader visibility into financial data than the human who built it. A customer support copilot frequently has a service account with access to the entire ticket database, including PII. None of this is malicious. It is the path of least resistance for getting an agent to do something useful.
Three controls help close the gap, and they are mostly extensions of capabilities a mature data security team already owns.
- CASB and SSPM coverage of LLM and agent platforms. The platforms hosting these agents (custom GPTs, Copilot Studio, internal MCP servers, vendor copilots) are SaaS applications. They need posture management, sanctioned application policies, and inline data protection just as much as Salesforce or Workday do. Most CASB and SSPM deployments are still catching up here. Push your vendor.
- Inline DLP on prompt and completion traffic. The point at which sensitive data leaves the environment is increasingly the prompt itself. Inline data inspection at the LLM gateway, using the same content matchers (EDM, IDM, OCR, vector ML) you trust for email and endpoints, is the right architectural pattern. The vendors are building this, but few enterprises have it deployed.
- An agent registry, even a basic one. Until the agent population is enumerable, no policy applied to it is provable. A spreadsheet is fine to start. The goal is to be able to answer, on any given Monday, three questions: which agents exist in production, what data each one can read, and who is the human owner of each. CSA’s data shows that most enterprises cannot answer those questions today.
What I Would Actually Start on This Week
Comprehensive ninety-day plans tend to lose momentum after the first two weeks of execution. The more effective approach, which I have refined over years of operationalizing data security programs at enterprise scale, is a focused set of starting moves that can ship in two weeks and that compound into a larger program over the quarter.
- Run an inventory pass for AI agents and copilots in your environment. Spreadsheet is fine. Capture name, owner, data scope, and approval status. The goal is to convert the CSA shadow agent statistic from an industry survey number into a number you actually have for your own organization.
- Review the data scope of every service account and OAuth grant tied to an LLM, agent, or copilot platform. Most of them were sized for development convenience, not production. Tighten the ones that need tightening. Decommission the ones that are no longer in active use.
- Pilot a model-based reviewer in the pull request path of one codebase. Measure the false positive rate and developer satisfaction at week four. If the numbers are reasonable, expand. If they are not, tune and try again.
- Add provenance metadata to your data classification taxonomy. Even if the only label you can ship this quarter is “generated by an AI system,” shipping it now is more valuable than waiting for a perfect schema. Tagging at ingestion is the part of the program that compounds, and it has been undersized for the agent era at most enterprises I have seen.
- Open the verified access conversation with your AI vendors. Anthropic Glasswing, OpenAI Trusted Access for Cyber, and equivalent programs from other providers offer pathways to models with reduced refusal thresholds for legitimate defensive work. The application process involves coordination with General Counsel and procurement, which is why initiating it before an urgent need is critical. Programs of this kind will become foundational infrastructure for enterprise security teams over the next two years.
These moves represent the structural transition that enterprise data security programs need to make over the next eighteen months. Programs that begin this work now will spend that window refining the controls and integrating them across their existing security stack. Programs that delay will spend the same window writing postmortems that explain why the controls were not in place.
Conclusion
The cybersecurity industry has navigated several genuine inflection points over the past decade, and the current moment qualifies as one of them on a specific structural ground: the cost curve for finding software flaws has bent, while the cost curve for shipping patches has not. The gap between those two curves is where every enterprise security program now operates, and the consequences land first at the data layer, which is where my work has been concentrated for the past decade.
Data security teams that internalize this framing now will spend 2026 building defensible programs around a fundamentally changed threat economy. Teams that wait for a more dramatic signal will spend the same period responding to incidents that the structural shift made predictable.
Opinions expressed by DZone contributors are their own.
Comments