8 Core LLM Development Skills Every Enterprise AI Team Must Master
Learn all about the eight essential LLM development skills every enterprise AI team must master for production-ready, scalable, and auditable AI systems.
Join the DZone community and get the full member experience.
Join For FreeWhen organizations talk about adopting large language models, the conversation usually starts with model choice. GPT versus Claude. Open source versus proprietary. Bigger versus cheaper. In real enterprise systems, that focus is misplaced.
Production success with LLMs depends far more on architecture discipline than on the model itself. What separates a fragile demo from a resilient, governable system is mastery of a small set of core engineering skills. These skills shape how models are instructed, grounded, deployed, observed, and evolved over time.
In this article, I am going to discuss eight such skills from the perspective of building real systems, not experimenting in notebooks. Each section explains why the skill matters, when it should be applied, and how it fits into a clean enterprise architecture.
Prompt Engineering
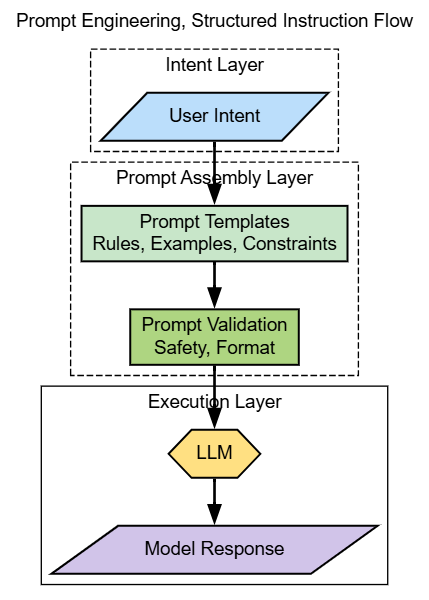
Prompt engineering is the foundation layer of any LLM system. It translates human intent into precise, structured instructions that a model can execute reliably. In production environments, prompts are not handwritten strings. They are assembled programmatically using templates, roles, constraints, examples, and safety rules.
Strong prompt engineering reduces hallucinations, improves consistency, and often delays the need for more complex approaches such as fine-tuning or agents. Poor prompts, on the other hand, amplify variability and force teams to compensate with brittle downstream logic.
In mature systems, prompts are versioned, tested, and reviewed just like application code. This discipline is what allows teams to change models without rewriting business logic.
Context Engineering
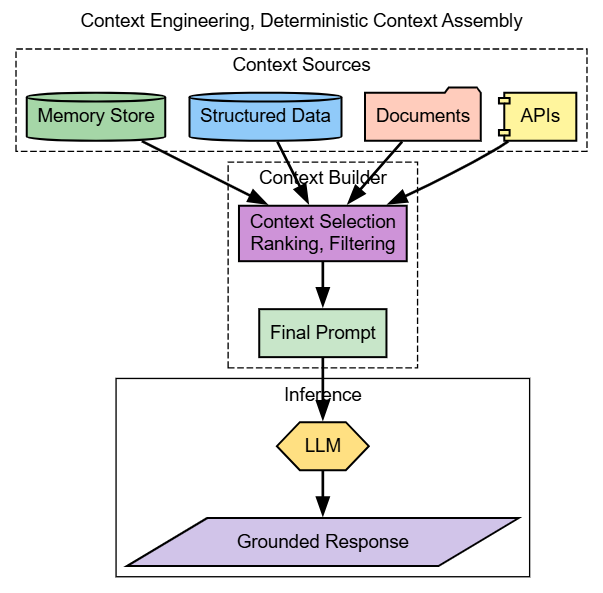
Context engineering determines what information the model sees at inference time. Instead of overloading a single prompt with everything, systems dynamically assemble relevant context from memory stores, structured databases, documents, and APIs.
This is where enterprise reliability truly begins. Context engineering is deterministic and auditable. You can explain why a model responded the way it did because you know exactly what data it was given.
Teams that skip this step often rely on the model to infer missing information. That approach may work in demos but fails under regulatory scrutiny or operational scale. Context engineering turns LLMs from probabilistic guessers into controlled reasoning components.
Fine-Tuning
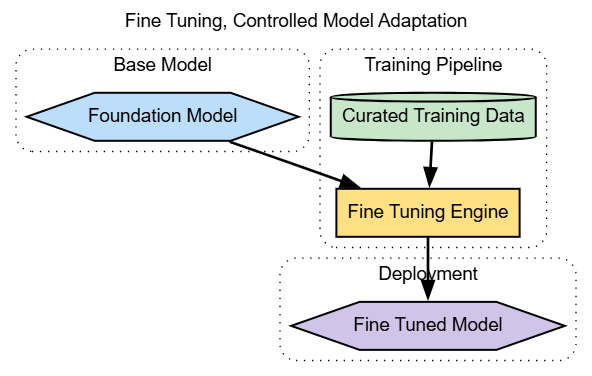
Fine-tuning modifies the model itself so that the desired behavior is internalized rather than instructed repeatedly. This approach is most effective when the same task repeats at scale, such as classification, extraction, or domain-specific reasoning.
The tradeoff is flexibility. Fine-tuned models are harder to change and require disciplined data governance. Training data must be curated, versioned, and reviewed for bias and drift.
In enterprise settings, fine-tuning should be a deliberate optimization step, not the default starting point. Many teams fine-tune prematurely when prompt and context engineering would have been sufficient.
Retrieval-Augmented Generation
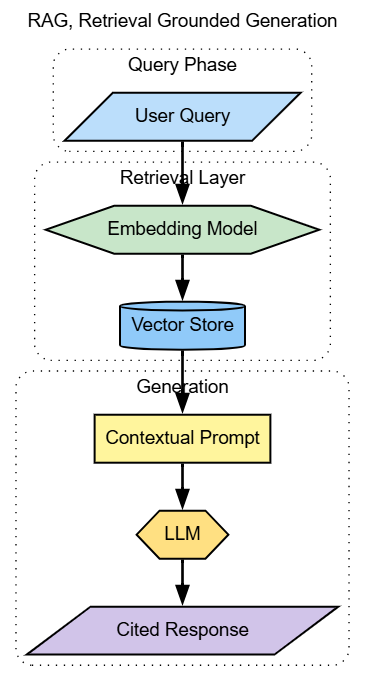
Retrieval-augmented generation, or RAG, grounds model outputs in external knowledge. Instead of trusting what the model remembers, the system retrieves relevant information at runtime and injects it into the prompt.
This pattern dominates enterprise adoption because it balances accuracy, freshness, and explainability. Knowledge can be updated without retraining models, and responses can be traced back to source documents.
Well-designed RAG systems treat retrieval as a first-class concern. Chunking strategy, embedding choice, ranking logic, and context all materially affect outcome quality.
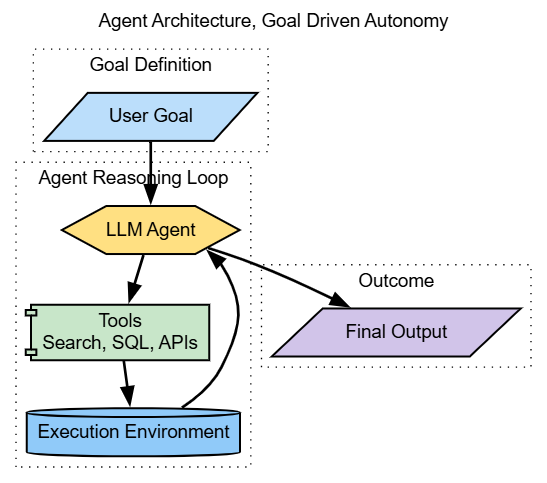
Agents
Agents introduce autonomy. An agent does not simply respond to input. It reasons, plans, calls tools, evaluates results, and iterates until a goal is achieved.
This capability is powerful and dangerous if misapplied. Agents are best suited for workflows such as multi-step analysis, orchestration, and decision support. They are poorly suited for factual retrieval or compliance-sensitive outputs.
Common failure modes include infinite loops, tool hallucination, runaway cost, and unpredictable behavior. In enterprise systems, agents must be constrained with explicit goals, step limits, tool allow lists, and strong observability. Autonomy without guardrails is not intelligence. It is a risk.
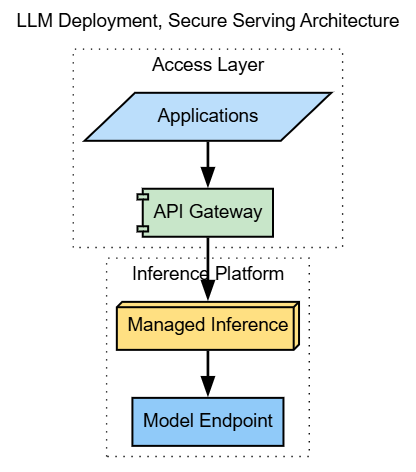
LLM Deployment
Deployment turns models into dependable services. This layer handles routing, scalability, authentication, authorization, and versioning. A clean deployment architecture allows teams to swap models without forcing application changes.
In enterprise environments, deployment also defines security boundaries. It determines where data flows, how requests are logged, and how failures are isolated.
Treating LLMs as just another API dependency is a mistake. They are probabilistic systems that require careful exposure and lifecycle management.
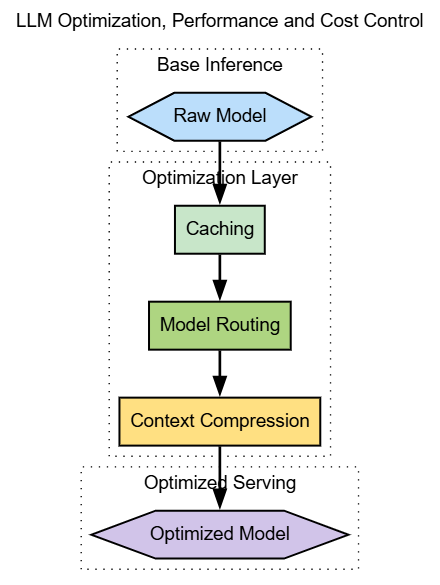
LLM Optimization
Optimization ensures performance and cost efficiency at scale. This includes caching frequent responses, compressing context, routing requests to different models, and applying techniques such as quantization.
Optimization is often invisible to end users but critical to sustainability. Without it, even well-designed systems become prohibitively expensive as usage grows.
Teams should treat optimization as an ongoing discipline rather than a one-time exercise. Usage patterns evolve, and so should optimization strategies.
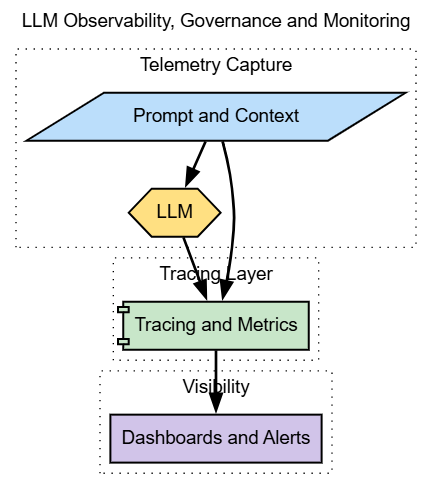
LLM Observability
Observability provides visibility into prompts, responses, latency, cost, and failure modes. Without it, LLM systems are effectively ungovernable.
In regulated industries, observability is not optional. Teams must be able to trace outputs, audit decisions, and detect drift or misuse.
Effective observability combines tracing, metrics, and structured logging. It allows teams to debug behavior, enforce policy, and continuously improve system quality.
This is end to end reference architecture diagram:
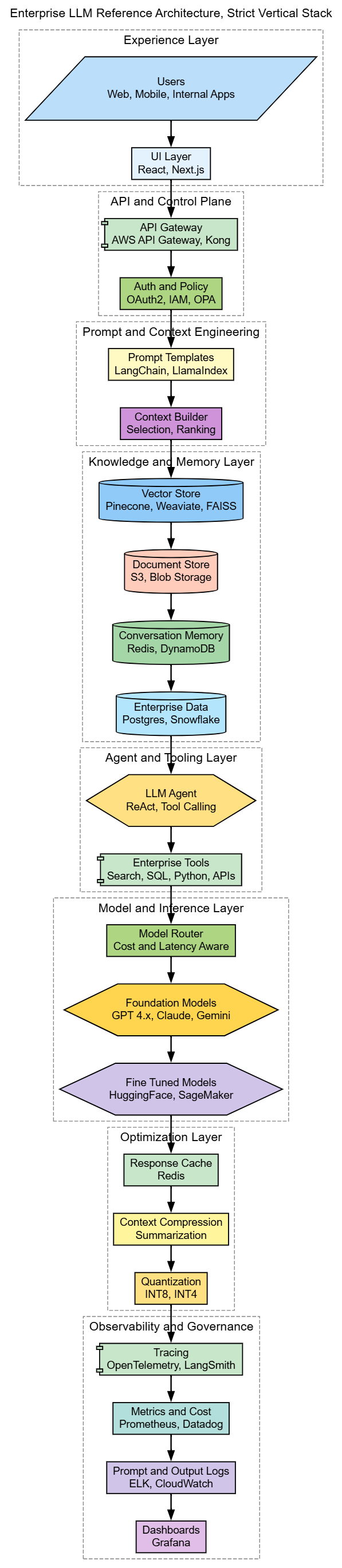
Reference Architecture Explanation
1. Prompt Engineering
The foundation of the system is prompt engineering, where user intent is transformed into structured instructions. In production, prompts are assembled programmatically using templates, system roles, constraints, and examples. Tools like LangChain and LlamaIndex allow for modular, reusable prompt templates, improving determinism and reducing hallucinations.
2. Context Engineering
Context engineering ensures the model sees the right information at inference time. Instead of embedding all data in a single prompt, the system dynamically assembles relevant context from multiple sources. This includes memory databases such as Redis or DynamoDB, document stores such as S3 or Blob Storage, structured enterprise data such as Postgres or Snowflake, and vector stores such as Pinecone, Weaviate, or FAISS. The context builder ranks and filters data to provide deterministic, auditable input to the model.
3. Fine-Tuning
Fine-tuning customizes models to internalize behaviors for repeated tasks. This is essential for domain-specific tasks such as classification, extraction, or reasoning at scale. Fine-tuned models are implemented using platforms like HuggingFace or SageMaker and provide consistency at the cost of flexibility.
4. Retrieval Augmented Generation
RAG ensures outputs are grounded in external knowledge rather than relying solely on what the model remembers. The system retrieves and embeds relevant information from vector stores, document repositories, enterprise databases, and memory layers into prompts. This balances accuracy, freshness, and explainability, forming a critical part of enterprise reliability.
5. Agents and Tooling
Agents orchestrate autonomous reasoning and task execution. They decide, iterate, and call external tools to achieve a goal. Enterprise tools include search, SQL queries, Python scripts, or APIs. Agents provide a structured workflow layer above raw inference, enabling complex multi-step operations while keeping control and auditability intact.
6. Model and Inference
This layer manages the execution of foundation and fine-tuned models. A model router selects the appropriate model based on cost, latency, or other criteria. Foundation models such as GPT 4.x, Claude, or Gemini handle general tasks, while fine-tuned models execute domain-specific operations. This layer turns the model into a dependable service that can scale and evolve without changing application logic.
7. Optimization
Optimization ensures performance and cost efficiency. Techniques include response caching with Redis, context compression using summarization and chunking, and model quantization with INT8 or INT4 representations. These optimizations are invisible to users but crucial for sustainability at scale.
8. Observability and Governance
The final layer provides visibility, traceability, and monitoring. Tools like OpenTelemetry and LangSmith trace prompt and model activity. Metrics and cost tracking are handled via Prometheus or Datadog. Logs from prompts and model outputs are collected in ELK or CloudWatch, and dashboards such as Grafana provide a comprehensive view for engineers and decision makers. Observability enables governance, auditing, and operational reliability.
Conclusion
When you understand these eight skills and how they compose, you stop thinking in terms of models and start thinking in systems. That shift is what turns LLM adoption from experimentation into real engineering leadership.
Opinions expressed by DZone contributors are their own.
Comments