Apache Ignite on Kubernetes: Things to Know About
Things you should know about apache Ignite on Kubernetes.
Join the DZone community and get the full member experience.
Join For FreeKubernetes is becoming more and more popular these days. No wonder! It’s an awesome technology that helps a lot in deploying and orchestrating applications in various cloud environments, both private and public.
I, as a person who works a lot with Apache Ignite, get questions about how to use it together with Kubernetes almost daily. Ignite is a distributed database, so utilizing Kubernetes to deploy it seems really appealing. In addition, many companies are currently in the process of transitioning their whole infrastructures to Kubernetes, which sometimes includes multiple Ignite clusters, as well as dozens of Ignite-related applications.
I consider Apache Ignite to be very Kubernetes-friendly. First of all, it’s generally agnostic to where it runs. It is essentially a set of Java applications, so if you can run JVMs in your environment, then you will most likely run Ignite without any issues. Second of all, Ignite comes along with Docker images and detailed documentation on how to use them in Kubernetes: https://apacheignite.readme.io/docs/kubernetes-deployment
At the same time, there are several pitfalls specific to the Ignite+Kubernetes combination, that I would like to share with you. Here are the questions that I will try to give answers for:
- Cluster Discovery — How to achieve it in Kubernetes?
- Stateless and Stateful Clusters — What is the difference and how it affects the Kubernetes configuration?
- Thick Clients vs. Thin Clients — Which ones should be used when running in Kubernetes?
Cluster Discovery
When you deploy Apache Ignite, you need to make sure that nodes connect to each other and form a cluster. This is done via the discovery protocol: https://apacheignite.readme.io/docs/tcpip-discovery
The most common way of configuring discovery for Ignite is to simply list the socket addresses of the servers where nodes are expected to run. Like this:
x
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder">
<property name="addresses">
<list>
<value>10.0.0.1:47500..47509</value>
<value>10.0.0.2:47500..47509</value>
<value>10.0.0.3:47500..47509</value>
</list>
</property>
</bean>
</property>
</bean>
</property>
</bean>
This, however, does not work in Kubernetes. In such a dynamic environment, where pods can be moved between underlying servers, and where addresses can change during restarts, there is no way to provide static configuration.
In order to tackle this, Ignite provides the Kubernetes IP Finder, which utilizes a Kubernetes service API to lookup a list of currently running pods. With this feature, all you need is to provide the name of the service to use for discovery. All nodes that run in the same namespace and are pointed to the same service, will discover each other. The configuration becomes very straightforward:
x
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.kubernetes.TcpDiscoveryKubernetesIpFinder">
<property name="namespace" value="ignite"/>
<property name="serviceName" value="ignite-service"/>
</bean>
</property>
</bean>
</property>
</bean>
Stateless and Stateful Clusters
There are two different ways how Ignite can be used: as a caching layer on top of existing data sources (relational and NoSQL databases, Hadoop, etc.), or as an actual database. In the latter case, Ignite uses the Native Persistence storage which is provided out of the box.
If Ignite acts as a cache, all data is persisted outside of it, therefore Ignite nodes are volatile. If a node restarts, it actually starts as a brand new one, without any data. There is no permanent state, in which case we say that the cluster is stateless.
On the other hand, if Ignite acts as a database, it is fully responsible for data consistency and durability. Every node stores a portion of the data both in memory and on disk, and in case of a restart, only in-memory data is lost. On-disk data, however, must be preserved. There is a permanent state that has to be maintained, so the cluster is stateful.
In the Kubernetes world, this translates to different controllers that you should use for different types of clusters. Here is a simple rule:
- For stateless clusters, the Deployment controller should be used.
- For stateful clusters, the StatefulSet controller should be used.
Following this rule will help you to not overcomplicate the configuration for stateless clusters, and at the same time make sure that stateful clusters behave as expected.
Thick Clients vs Thin Clients
Ignite provides various client connectors that serve different purposes and are quite different in the way they are designed. I wrote about this in detail in one of my previous articles: https://dzone.com/articles/apache-ignite-client-connectors-variety. Specifics of the Kubernetes environment add additional considerations to the topic.
Kubernetes does not expose individual pods directly to the outside world. Instead, there is usually a load balancer that is responsible for accepting all outside requests and redirecting them to the pods. Both Ignite server nodes and client applications can run on either side of the load balancer, which affects the choice between thick and thin clients.
Typically, you will see one of these three scenarios.
Scenario 1: Everything in Kubernetes
By “everything” I mean both the Ignite cluster and the application talking to this cluster. They run in the same namespace of the same Kubernetes environment.
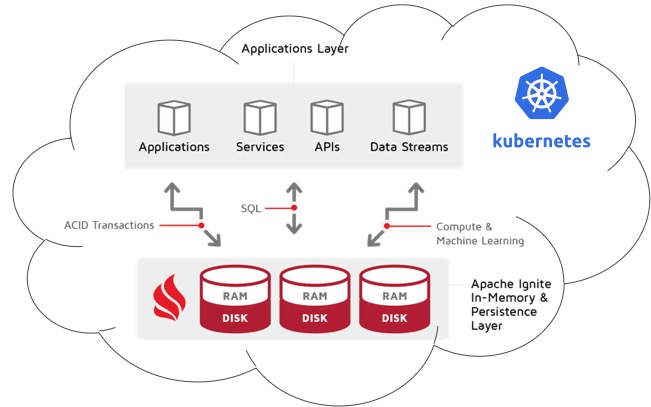
In this case, there are no limitations whatsoever — you are free to use any type of client connector. Unless there is a specific reason to do otherwise, I would recommend sticking with thick clients here, as it’s the most efficient and robust option.
Scenario 2: Cluster Outside of Kubernetes
This is very typical for companies that are in progress of transitioning existing clusters and applications from more traditional bare metal deployment to Kubernetes deployment.
Such companies usually prefer to transition applications first, as they are much more dynamic — updated frequently by a large number of individual developers. This makes proper orchestration for applications much more important than for Ignite clusters, which can run for months or even years without disruption, and are usually maintained by a small group of people.
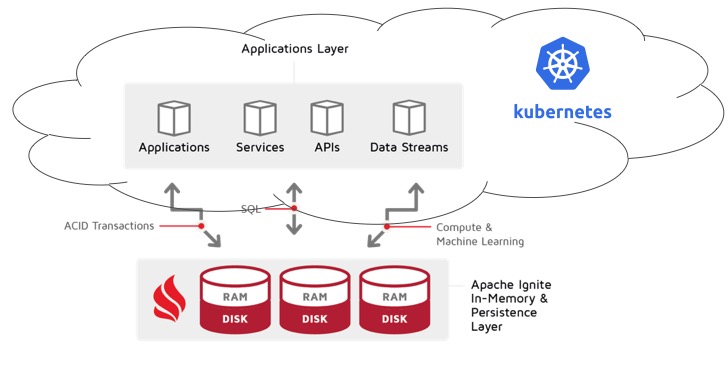
Here we have a significant limitation: thick clients are not compatible with this scenario. The reason is that there is a possibility for a server node to try creating a TCP connection with a particular thick client. This will most likely fail due to the load balancer in front of the Kubernetes cluster.
If you find yourself in this situation, you currently have two options:
- Use thin clients or JDBC/ODBC drivers instead of thick clients.
- Move the Ignite cluster into the Kubernetes environment (effectively transitioning to scenario 1 which doesn’t have these limitations).
Good news though: Apache Ignite community recognizes the impact of this limitation and is currently working on improvements that would allow using thick clients in this kind of deployment. Stay tuned!
Scenario 3: Applications Outside of Kubernetes
This is the opposite of the previous scenario — Ignite cluster runs within Kubernetes, but applications are outside of it.
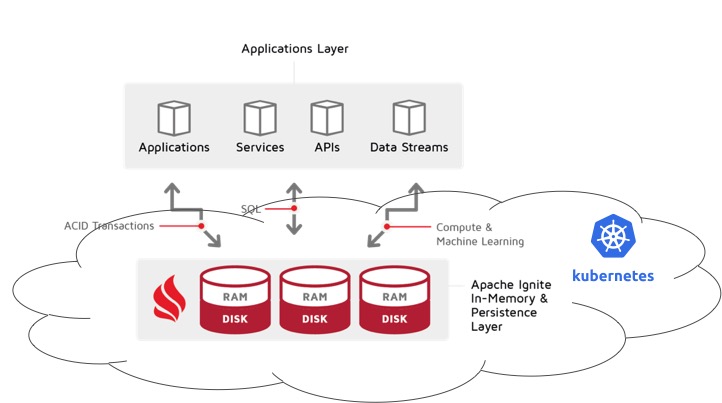
Although I’ve seen it a couple of times, this scenario is extremely rare compared to the other two. If this is your case, I would strongly recommend you to consider moving the applications to Kubernetes, since you already use it. You can thank me later!
From Ignite perspective, this type of deployment allows only for thin clients and JDBC/ODBC drivers. You can’t use thick clients in this scenario.
What I’ve described above are the main complications that you might stumble upon when working with Apache Ignite in Kubernetes environments.
As a next step, I would suggest taking a look at this GitHub repo where I uploaded full configuration files that can be used to deploy a stateful Ignite cluster in Amazon EKS: https://github.com/vkulichenko/ignite-eks-config
And of course, always feel free to refer to the Ignite documentation for more details: https://apacheignite.readme.io/docs/kubernetes-deployment
Opinions expressed by DZone contributors are their own.
Comments