Apache Spark 4.0: What’s New for Data Engineers and ML Developers
Spark 4.0 brings Spark Connect, enhanced SQL (PIPE, VARIANT), richer Python APIs, and advanced streaming — modernizing Spark for faster, more flexible 2025 workloads.
Join the DZone community and get the full member experience.
Join For Free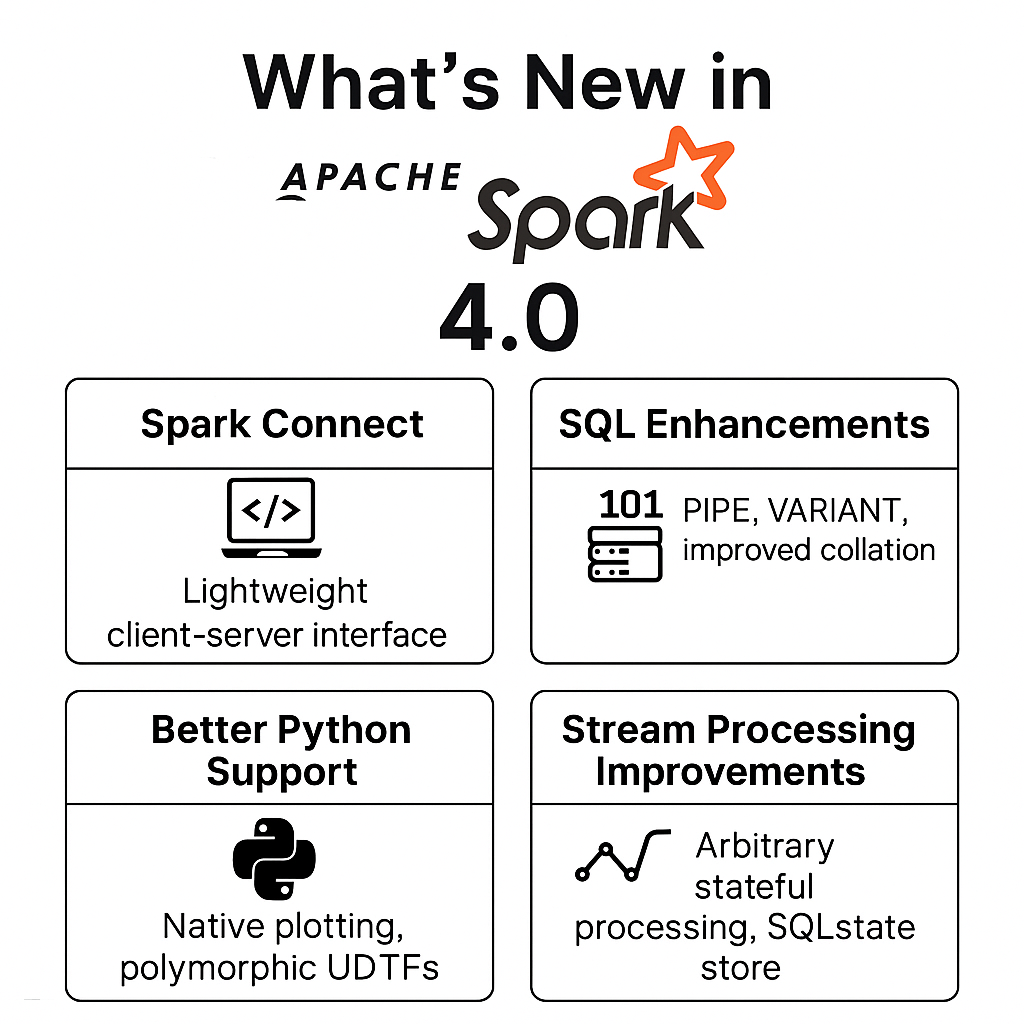
Undoubtedly one of the most anticipated updates in the world of big-data engines, the release of Apache Spark 4.0 is a big step in the right direction. According to the release notes, this shift involved closing more than 5,100 sprint tickets, facilitated by the negligence of over 390 active contributors.
Machine learning and data engineering professionals, the new features of SQL, additional capabilities for Python, management of streaming states, and the newly introduced Spark Connect framework in Spark 4.0 will further reinforce the trend of high-performance, easy-to-use, scalable data analytics.
What’s New: Key Highlights for Practitioners
Lightweight Multi-Language Client Spark Connect
The most significant improvement in Spark 4.0 is the updated Spark Connect client-server framework. There is a new Python client that is only 1.5MB in size.
This release also introduces the spark.api.mode config parameter for switching between classic and Connect modes, as well as richer Python, Scala, and new Go, Swift, and Rust API client implementations.
The change in impact is the newly expanded capability of data engineering teams to create thinner, more performant client applications, or simpler, streamlined applications for use in Go or Rust that query a Spark cluster.
This amplifies the versatility of deployment and enables the use of Spark in microservices or in a containerized context.
Innovations in SQL Language & Data Types
Spark 4.0 introduces some of the most substantial new features in SQL:
- With SQL scripting and session variables, users can implement complex SQL workings using local variables and control structures.
- The use of the new PIPE syntax (|>) makes it possible to write SQL statements in a chained, more legible, functional form.
- New VARIANT data type tailored for semi-structured data such as JSON and other map-like structures enhances schema versatility.
- Collation (accent/case insensitivity, locale-based ordering) improves the treatment of multilingual data in string datasets.
Effect
With the additional Spark features, a unified data processing engine for working with structured and non-structured data becomes possible. And more SQL capabilities translate into easier work for data engineers, as they can design systems with more direct approaches and fewer configuration workarounds.
Improving the Developer Experience and Incorporating Python into the Workspace
- Gains in productivity for Python programmers.
- Implementing custom batch and streaming connectors in Python.
- User Defined Table Functions (UDTFs) written in Python where the output can dynamically change and return different schemas.
Effect
These improvements let ML developers and data scientists spend less time and effort on prototyping and productionizing to code, and in particular, custom connectors and transformations without having to use Scala or Java.
Advances in Streaming and Managing State
- Date: Spark 4.0. Relational stream processing now has several enhancements.
- The Arbitrary Stateful Processing v2 API (e.g., transformWithState) in streaming flows can manage complex state logic, timers, TTLs, and schema evolution.
- Queryable state and the State Store Data Source, which expose streaming state as a table, enhancing visibility for debugging.
Effect
Data engineers working on real-time pipelines now have more advanced techniques for creating stateful applications and stream processing, particularly in event-driven scenarios.
Migration & Other Considerations
While enhancements have been made to Spark 4.0, there are still some issues with migration:
- Changing some of the policies (like overflow or the new null policy) breaks more forgiving behavior, which will turn on the soft east policies and make them stricter.
- Java 17 runtime is now supported and required in some spaces, which may require changes to the dependencies used.
- Because there are new APIs, such as the Python Data Source API, UDTFs, and VARIANT data types, organizations are to first test migration on workloads that are not as critical for detecting compatibility problems.
Tip for teams: Use Spark 4.0 with the newest workloads, and after the system is stable, then monitor the system behavior to retro-fit the older workloads.
How Does This Matter for 2025 and Beyond?
Spark 4.0 has been released amid several industry shifts.
- There is an increased demand for all-in-one data platforms (batch + streaming + machine learning).
- There is an increased use of semi-structured data (JSON logs, variant schemas).
- There is an increased use of non-JVM languages (Go, Rust) in the big data domain.
- There are increased expectations for observability and developer productivity in data engineering.
Given the above trends, Spark 4.0 has established itself as an engine primed for data engineering and Machine Learning workloads. Effective upgrades will provide enterprises with an increased developer velocity, observability, and production stability.
Closing Thoughts
For those in charge of data engineering or machine learning operations, Spark 4.0 provides an important point in time. This is not just about upgrading to larger clusters and increasing job speeds, but also about improving APIs, expanding programming language support, enhancing SQL interfaces and streaming tools, and improving overall usability.
Any migration to Spark 4.0 will require careful planning; however, the return on investment will include improved developer productivity, better integration of data engineering and Machine Learning workflows, and a more future-proofed platform.
Begin with a sandbox to explore Spark 4.0 and test the new SQL and streaming capabilities to justify the business case for Spark 4.0. It is in the center of the future of data engineering and will brighten it with its capabilities.
Opinions expressed by DZone contributors are their own.
Comments