Apache Spark vs. MapReduce
How did Spark become so efficient in data processing compared to MapReduce? Learn about Spark's powerful stack of libraries and big data processing functionalities.
Join the DZone community and get the full member experience.
Join For FreeSpark can be deployed on a variety of platforms. It runs on Windows and UNIX (such as Linux and Mac OS) and can be deployed in standalone mode on a single node when it has a supported OS. Spark can also be deployed in a cluster node on Hadoop YARN as well as Apache Mesos. Spark is a Java Virtual Machine (JVM)-based distributed data processing engine that scales, and it is fast compared to many other data processing frameworks. Spark originated at the University of California at Berkeley and later became one of the top projects in Apache.
Apache Spark includes several libraries to help build applications for machine learning (MLlib), stream processing (Spark Streaming), and graph processing (GraphX).
To test the hypothesis that simple specialized frameworks provide value, we identified one class of jobs that were found to perform poorly on Hadoop by machine learning researchers at our lab — iterative jobs where a dataset is reused across a number of iterations. We built a specialized framework called Spark optimized for these workloads.
The biggest claim from Spark regarding speed is that it is able to "run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk." Spark could make this claim because it does the processing in the main memory of the worker nodes and prevents the unnecessary I/O operations with the disks. The other advantage Spark offers is the ability to chain the tasks even at an application programming level without writing onto the disks at all or minimizing the number of writes to the disks.
How did Spark become so efficient in data processing compared to MapReduce? It comes with a very advanced directed acyclic graph (DAG) data processing engine. What it means is that for every Spark job, a DAG of tasks is created to be executed by the engine. The DAG in mathematical parlance consists of a set of vertices and directed edges connecting them. The tasks are executed as per the DAG layout.
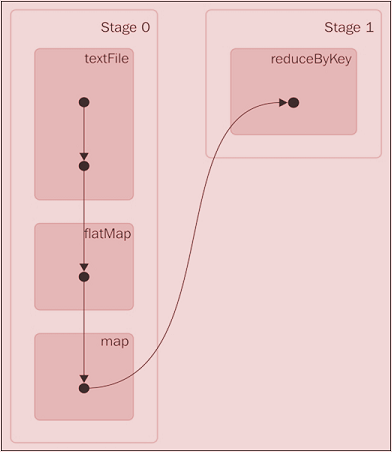
In the case of MapReduce, the DAG consists of only two vertices, with one vertex for the map task and the other one for the reduce task. The edge is directed from the map vertex to the reduce vertex. The in-memory data processing combined with its DAG-based data processing engine makes Spark very efficient. In Spark's case, the DAG of tasks can be as complicated as it can. Thankfully, Spark comes with utilities that can give an excellent visualization of the DAG of any Spark job that is running. In a word count example, Spark's Scala code will look something like the following code snippet. The details of this programming aspects will be covered in the coming chapters:
val textFile = sc.textFile("README.md")
val wordCounts = textFile.flatMap(line => line.split(" ")).map(word =>
(word, 1)).reduceByKey((a, b) => a + b)
wordCounts.collect()The web application that comes with Spark is capable of monitoring workers and applications. The DAG of the preceding Spark job generated on the fly will look like this:
In addition to the core data processing engine, Spark comes with a powerful stack of domain-specific libraries that use the core Spark libraries and provide various functionalities useful for various big data processing needs. The following table lists the supported libraries:
Library |
Use |
Supported Languages |
Spark SQL |
Enables the use of SQL statements or DataFrame API inside Spark applications |
Scala, Java, Python, and R |
Spark Streaming |
Enables processing of live data streams |
Scala, Java, and Python |
Spark MLlib |
Enables development of machine learning applications |
Scala, Java, Python, and R |
Spark GraphX |
Enables graph processing and supports a growing library of graph algorithms |
Scala |
Opinions expressed by DZone contributors are their own.
Comments