Augmented Analytics With PySpark and Sentiment Analysis
Step by step tutorial of how you can leverage sentiment analysis to enrich tweets data with PySpark and get a feel of the overall sentiments towards COVID19.
Join the DZone community and get the full member experience.
Join For FreeIn this tutorial, you will learn how to enrich COVID19 tweets data with a positive sentiment score.You will leverage PySpark and Cognitive Services and learn about Augmented Analytics.
What Is Augmented Analytics?
According to Gartner's report, augmented analytics is the use of technologies such as machine learning and AI to assist with data preparation, insight generation. Its main goal is to help more people to get value out of data and generate insights in an easy, conversational manner. For our example, we extract the positive sentiment score out of a tweet to help in understanding the overall sentiment towards COVID-19.
What Is PySpark?
PySpark is the framework we use to work with Apache Spark and Python. Learn more about it here.
What Is Sentiment Analysis?
Sentiment Analysis is part of NLP - natural language processing usage that combined text analytics, computation linguistics, and more to systematically study affective states and subjective information, such as tweets. In our example, we will see how we can extract positive sentiment score out of COVID-19 tweets text. In this tutorial, you are going to leverage Azure Cognitive Service, which gives us Sentiment Analysis capabilities out of the box. When working with it, we can leverage the TextAnalyticsClient client library or leverage REST API. Today, you will use the REST API as it gives us more flexibility.
Prerequisites
- Apache Spark environment with notebooks, it can be Databricks, or you can start a local environment with docker by running the next command:
docker run -it -p 8888:8888 jupyter/pyspark-notebook - Azure free account
- Download Kaggle COVID-19 Tweet data
- Cognitive Services free account (check out the picture below )

Step by Step Tutorial — Full Data Pipeline:
In this step by step tutorial, you will learn how to load the data with PySpark, create a user define a function to connect to Sentiment Analytics API, add the sentiment data and save everything to the Parquet format files.
You now need to extract upload the data to your Apache Spark environment, rather it's Databricks or PySpark jupyter notebook. For Databricks use this, for juypter use this.
For both cases, you will need the file_location = "/FileStore/tables/covid19_tweets.csv" make sure to keep a note of it.
Loading the Data With PySpark
This is how you load the data to PySpark DataFrame object, spark will try to infer the schema directly from the CSV. One of the things you will notice is that when working with CSV and infer a schema, Spark often refers to most columns as String format.
xxxxxxxxxx
inputDF = spark.read.\
format("com.databricks.spark.csv").\
option("header", "true").\
option("inferSchema", "true").load("/FileStore/tables/covid19_tweets.csv")
Provide More Accurate Schema to Our Data:
In here you define the expectedSchema and later cast the data to match it. You will use StructType and StructField which are Spark SQL DataTypes that help you with defining the schema.
withColumn functionality creates a new DataFrame with the desired column according to the name and value you provide it with.
xxxxxxxxxx
from pyspark.sql.types import *
from pyspark.sql.functions import *
# create expected schema
expectedSchema = StructType([
StructField("user_name", StringType(), True),
StructField("user_location", StringType(), True),
StructField("user_description", StringType(), True),
StructField("user_created", StringType(), True),
StructField("user_followers", FloatType(), True),
StructField("user_friends", FloatType(), True),
StructField("user_favourites", FloatType(), True),
StructField("user_verified", BooleanType(), True),
StructField("date", StringType(), True),
StructField("text", StringType(), True),
StructField("hashtags", StringType(), True),
StructField("source", StringType(), True),
StructField("is_retweet", BooleanType(), True)
])
Now, let's create your new DataFrame with the right schema!
Notice that you assign the new schema to inputDF, which means you will no longer have access to the old DataFrame.
xxxxxxxxxx
# Set data types - cast the data in columns to match schema
inputDF = inputDF \
.withColumn("user_name", inputDF["user_name"].cast("string")) \
.withColumn("user_location", inputDF["user_location"].cast("string")) \
.withColumn("user_description", inputDF["user_description"].cast("string")) \
.withColumn("user_created", inputDF["user_created"].cast("string")) \
.withColumn("user_followers", inputDF["user_followers"].cast("float")) \
.withColumn("user_friends", inputDF["user_friends"].cast("float")) \
.withColumn("user_favourites", inputDF["user_favourites"].cast("float")) \
.withColumn("user_verified", inputDF["user_verified"].cast("boolean")) \
.withColumn("date", inputDF["date"].cast("string")) \
.withColumn("text", inputDF["text"].cast("string")) \
.withColumn("hashtags", inputDF["hashtags"].cast("string")) \
.withColumn("source", inputDF["source"].cast("string")) \
.withColumn("is_retweet", inputDF["is_retweet"].cast("boolean")) \
Connect to Sentiment Analysis With REST API
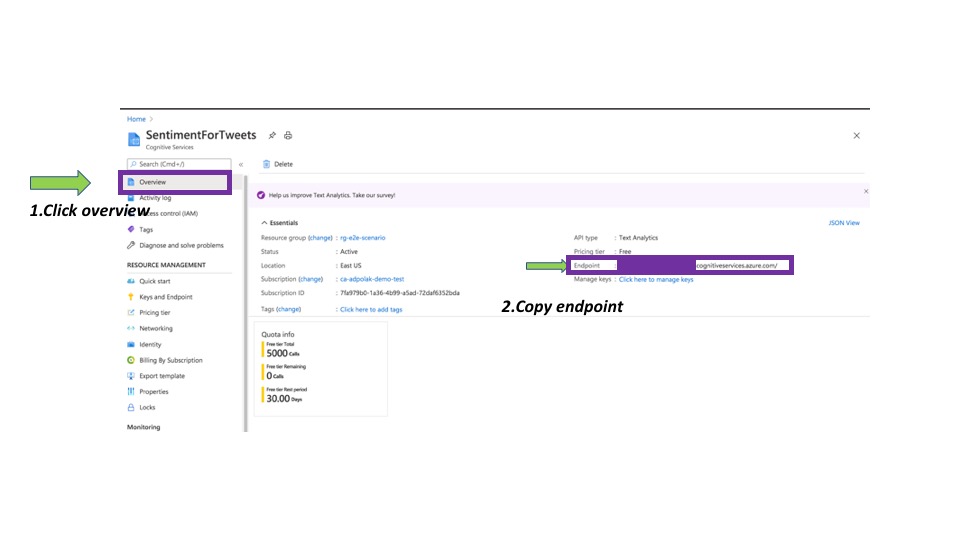
For connecting and consuming sentiment analysis services, we need to provide the sentiment analysis endpoint and access key. Both can be found in the .
Finding the endpoint, it can be from the Overview section or from Keys and Endpoints.
Finding the access key:

After finding the key and endpoint, for production and working in a team, you need to store them in someplace safe, try providing saving keys in free text in code, this is not safe. You might end up with hackers mining your cloud environment for bitcoins.
For Databricks, you can leverage dbutils.secrets functionality. This is how to set it up.
If you work locally with juypter PySpark notebook, you can use plain-text, but remember to remove it when you commit your code to a git repo.
This is how to work with dbutils, providing it the scope and key name.
In this code snippet, the scope is named - mle2ebigdatakv and the name for the key is sentimentEndpoint and sentimentAccessKeys.
xxxxxxxxxx
# provide endpoint and key
sentimentEndpoint = dbutils.secrets.get(scope="mle2ebigdatakv", key="sentimentEndpoint")
sentimentAccessKeys = dbutils.secrets.get(scope="mle2ebigdatakv", key="sentimentAccessKeys")
Let's build the connections itself, sentiment analysis expects to receive a document like an object, for that you will work with python dictionary and will build a doc request with ID. The ID has to be unique for every request.
Notice here the language_api_url variable, this is where you are constructing the request for Cognitive Analysis, asking for text analytics sentiment with version 3.0.
xxxxxxxxxx
import requests
# build the rest API request with language_api_url
language_api_url = sentimentEndpoint + "/text/analytics/v3.0/sentiment"
headers = {"Ocp-Apim-Subscription-Key": sentimentAccessKeys}
def constractDocRequest(text):
docRequest = {}
doc = {}
doc["id"]= text
doc["text"]= text
docRequest["documents"] = [doc]
return docRequest
Try running it with some text, you will see that the response is consistent of score sentiment for positive, netural and negative.
This is how a response is structured:
xxxxxxxxxx
{
"documents": [
{
"id": "1",
"sentiment": "positive",
"confidenceScores": {
"positive": 1.0,
"neutral": 0.0,
"negative": 0.0
},
"sentences": [
{
"sentiment": "positive",
"confidenceScores": {
"positive": 1.0,
"neutral": 0.0,
"negative": 0.0
},
"offset": 0,
"length": 66,
"text": "covid19 is not scary at all, it't actualy an oppurtiniry to thrive"
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
Let's build a python functionality to extract sentiment and register the function with PySpark through the UDF(user-defined function) api.
You need to make sure you are actually getting a document back from the REST API, and also secure your functionality from sending an empty text to the sentiment analysis service, as it will resolve in an error.
This is how you connect everything together:
x
from pyspark.sql.functions import udf
# extract the sentiment out of the returned json doc
def extractSentiment(doc,sentimentType):
if doc == {} or not 'documents' in doc:
return 0.0
return float(doc['documents'][0]['confidenceScores'][sentimentType])
#function for extracting the positive sentiment
def getPositiveSentiment(text):
if bool(text.strip()) == False:
return 0.0
positive = extractSentiment(constructDocRequest(text),'positive')
return positive
# creating the udf function pointer
get_positive_sentiment = udf(getPositiveSentiment, StringType())
# create a new DF with new column represetning positive sentiment score
enrichedDF_positiveSentiment = inputDF.withColumn('positive_sentiment', get_positive_sentiment(inputStream["text"]))
After enriching your data, it's important to save it to storage for future needs, you will save it to parquet format which will keep the schema intact. Apache Parquet format is designed to bring efficient columnar storage of data compared to row-based files such as CSV since it allows better compression and faster scanning of a subset of columns later on. Vs CSV, where we have to read the whole file and the columns to query only a subset of them.
This is how it's done with PySpark:
xxxxxxxxxx
# Stream processed data to parquet for the Data Science to explore and build ML models
enrichedDF_poisitveSentiment.write \
.format("parquet") \
.save("/DATALAKE/COVID19_TWEETS/REFINED/WITH_SENTIMENT/")
You can decide on the name and structure of your data, but make sure to point out that this data now contained a new column with positive sentiment.
This data can later be used in various data visualization tools or for researchers.
Issues That May Occur
xxxxxxxxxx
{'error': {'code': 'InvalidRequest',
'innererror': {'code': 'EmptyRequest', 'message': 'Request body must be present.'
},
'message': 'Invalid Request.'}
}
Pay notice to the error message, when you see this kind of error, it might be that you are out of quote with Cognitive Services. If you learning about the service and trying it out, it's better to use a few samples and not the whole datasets, as you might run out of quota in the free tier as it's good for up to 5K transactions.
That's it!
This tutorial walked you through how to leverage existing REST API services to enrich your data for future work and augmented analytics.
To learn more, check out the GitHub repo. Happy to take your questions and follow up with you on twitter.
Opinions expressed by DZone contributors are their own.
Comments