Automating AWS Glue Infra and Code Reviews With RAG and Amazon Bedrock
Automate AWS Glue reviews with infra-first RAG governance, enforcing enterprise standards, reducing manual work, and shifting checks left.
Join the DZone community and get the full member experience.
Join For FreeIn many enterprises, the transition from a "working" pipeline to a "production-ready" pipeline is gated by a manual checklist. In most enterprises, a “simple” Glue review involves answering questions like:
- Is the Glue job deployed?
- Was it provisioned via CloudFormation?
- Does the expected crawler exist?
- Is the code production-grade?
- Does it follow internal best practices?
Traditionally, a senior engineer would spend 4–6 hours per use case and manually:
- Cross-references CloudFormation
- Opens job scripts
- Reviews against a checklist stored somewhere
- Writes feedback by hand
In a fast-scaling organization, this creates a bottleneck. To solve this, I developed a utility that implements shift-left governance — moving the review process from the final "pre-production" stage directly into the development cycle.
So instead of waiting for a Senior Engineer to find a missing Crawler or a hardcoded S3 path near production deployment, the developer runs an automated script during development.
- Proactive vs. reactive: Issues are fixed while in the development phase.
- Cost reduction: It is significantly cheaper that 4-6hrs a senior engineer would spend.
- Empowerment: Developers receive instant, expert-level feedback without waiting on a human reviewer.
The Solution Architecture: RAG-Powered Governance
The core of this implementation is a retrieval-augmented generation (RAG) pattern. While LLMs are smart, they don't natively know your specific "Enterprise Internal Standards."
The RAG Approach: Grounding the Review
Instead of hardcoding rules into a prompt, we store the Enterprise Best Practices Checklist as a document in Amazon S3.
Design Principle: Deterministic Infrastructure Validation Before Probabilistic Inference
The key insight was simple: A Glue job review is meaningless without infrastructure context.
So instead of building “another code reviewer,” let's build a system that:
- Starts with real deployed infrastructure
- Verifies it against enterprise standards
- Reviews code only if infra checks pass
- Uses GenAI with strict grounding
The High-Level Architecture
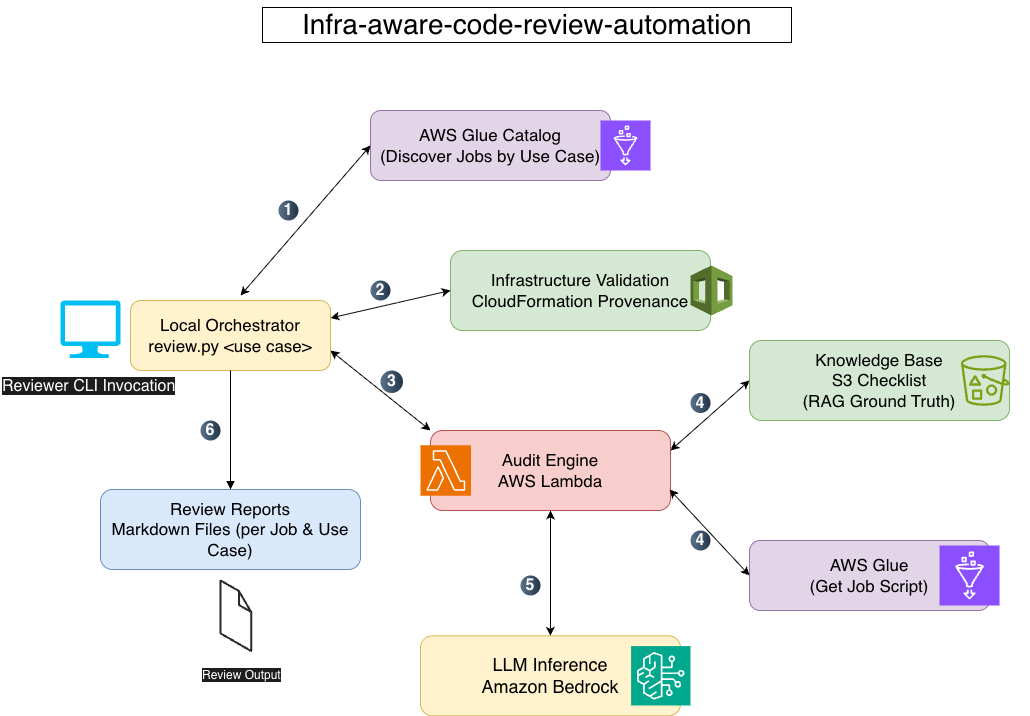
At a glance, the system works like this:
- The reviewer runs a local CLI command with a use case name.
- The system discovers all Glue jobs for that use case.
- It validates:
- Glue job existence
- Deployment status
- CloudFormation provenance
- Expected crawlers
- It retrieves enterprise review standards from Amazon S3, along with the glue job script to be reviewed against this checklist.
- It runs a GenAI-powered code review.
- It generates Markdown reports per job.
All fully automated.
Step 1: Discover Glue Jobs Automatically
Instead of hardcoding job names, I used the AWS Glue Data Catalog to discover jobs associated with a use case.
This allows the review process to:
- Stay decoupled from naming conventions
- Work across environments
- Scale as pipelines grow
Step 2: Infrastructure Validation (The Missing Piece)
Before touching the code, the system validates the infrastructure.
For each Glue job, it checks:
- Does the job exist?
- Is it deployed?
- Was it created via CloudFormation?
- Does required crawler exist?
Example output:
Glue Job Exists
- Resource: Glue Job (<gluejob name>)
Status: Deployed
Source: IaC (CloudFormation: <stack name>)
Compliance: Project standards met
If something is missing:
Crawler Doesn't Exist
<crawler name> Expected
- Compliance: Project standards not metStep 3: The RAG Approach (Grounding the review)
Once infra checks pass, the system sends the script and the RAG-retrieved checklist to a Claude Sonnet 3.5 LLM hosted on Amazon Bedrock.
Here’s how:
- The enterprise checklist is stored in Amazon S3
- Relevant checklist is retrieved at runtime
- Glue job script is retrieved from job metadata at runtime.
- They are injected directly into the LLM prompt
- The LLM evaluates code only against retrieved standards
The model does not invent rules.
It reasons strictly within enterprise-defined constraints.
This allows the governance rules to evolve (e.g., adding a new requirement) just by updating an S3 file, without changing a single line of the review code.
Why Not Free-Form GenAI?
Unconstrained GenAI:
- Hallucinates standards
- Produces inconsistent feedback
- Is impossible to audit
That’s unacceptable in an enterprise.
What the Code Review Output Looks Like
Each Glue job gets a Markdown report like this:
## Code Structure & Readability
Is the code modular and function-based?
- Status: NEEDS IMPROVEMENT
- Explanation: Logic is implemented in a single main function. But there is repetitive code for listing objects in S3 buckets.
- Recommendation: Create a separate function for listing S3 objects to reduce repetition.Every checklist item includes:
- Pass/fail status
- Clear explanation
- Actionable recommendation
Exactly how a senior engineer would review — but consistently.
Performance and Productivity Gains
By shifting governance left and using RAG, we can turn a slow, expert-driven, manual process into a fast, deterministic, self-service workflow:
| metric | manual process | rag-automated process | improvement |
|---|---|---|---|
| Review Time | ~4 hrs | ~3-4 Minutes | 98% Faster |
|
Rule Updates
|
Manual Re-training | Update S3 File | Instant |
| Reviewer dependency | Senior engineer | Self-service | Reallocation of senior expertise to high-impact architecture |
| Consistency | Human-dependent | 100% Policy-aligned | No subjective bias |
| Review quality | Variable | Standardised | Institutionalisation of "Best Practices. |
| Cost | High-Cost Engineering Hours | Nominal API/Compute Cost. (<$0.10 per PR via Amazon Bedrock) | >99% Reduction in Direct Review Expense |
| Audit trail | Manually 1 to 1 shared review comments | Markdown artifacts | High-fidelity visibility for stakeholders |
Net result: ~95% reduction in review time.
Conclusion: Governance as a Service
This implementation proves that "Enterprise Standards" don't have to be a manual burden. By utilizing a RAG approach with Amazon Bedrock, a living governance engine can be created that executes in minutes and is active from the development phase itself. This allows senior engineers to focus on architecture and innovation, while the "bottleneck" of checklist-checking is eliminated.
The code for this implementation is available in my GitHub repository.
Clone URL: https://github.com/chhabrapooja/infra-aware-code-review-automation.git
I will make the repository public following the publication of this article.
Why This Works (and Scales)
Some reasons are:
- Infra comes first. Most review tools ignore infrastructure. This one starts there.
- Grounded GenAI implementation. RAG ensures correctness, consistency, and auditability.
- Standards are decoupled from code. Updating the checklist requires no redeployment.
- Decoupling infrastructure by lifecycle and/or use case. Instead of maintaining a single stack, we implemented granular stack segmentation based on the specific pipeline stage to locate specific resources instantly.
Future Roadmap
CI/CD Integration: Trigger reviews automatically on GitHub Pull Requests.
Opinions expressed by DZone contributors are their own.
Comments