How We Built a Smarter University Chatbot Using LLaMA2, AWS SageMaker, and RAG
We built a multilingual university chatbot using LLaMA2, SageMaker, LangChain, and Milvus with RAG for real-time answers scalable to domains like healthcare and HR.
Join the DZone community and get the full member experience.
Join For FreeEvery semester, university IT helpdesks are overwhelmed by repetitive queries from students — from course registration deadlines to tuition fees and campus services. Most existing systems either rely on outdated FAQs or rigid bots that can't adapt to multiple languages or real-time updates. Recognizing this gap, we developed a smarter, multilingual chatbot using LLaMA2, AWS SageMaker, LangChain, and Milvus, built around a Retrieval-Augmented Generation (RAG) pipeline.
The Need for Smarter Campus Support
Higher education institutions face growing demands to modernize how students interact with campus services. Traditional IT support models don’t scale well — especially when students ask the same questions repeatedly. Even chatbots built on rule-based logic often fall short due to poor language handling, limited context awareness, and rigid workflows. By mid-semester, helpdesk queues are swamped, leading to delays and user frustration.
We wanted to change that by building a chatbot that could respond quickly, accurately, and in multiple languages — without constant maintenance. That meant combining a large language model with real-time retrieval and seamless integration into university systems.
Problem Overview
Many universities rely on static knowledge bases or rule-based bots that can’t scale with demand or linguistic diversity. We identified three core challenges:
- Limited Multilingual Support: Traditional bots struggle with regional languages like Hindi, Telugu, Spanish, or Gujarati.
- Manual Maintenance Overhead: Every tuition change or academic policy update requires manual data entry or retraining.
- Scalability Issues: Scaling chatbot features across departments or regions required extensive customization and infrastructure upgrades.
These limitations led us to design a dynamic, real-time system that integrates retrieval and generation using recent open-source technologies.
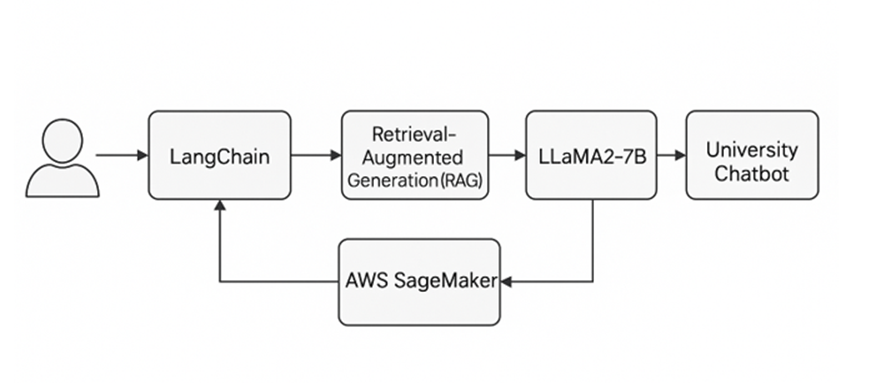
Solution Architecture
We chose a modular, cloud-native architecture to keep things flexible and scalable:
- LLaMA2-7b-hf: A capable, open-source model with strong reasoning and minimal hardware demands.
- AWS SageMaker: Offered streamlined training and deployment via managed endpoints.
- LangChain: Orchestrated the entire query workflow using RAG techniques.
- Milvus: A vector database to semantically index and search university documents (catalogs, policies, FAQs).
This architecture allowed us to avoid vendor lock-in and retain full control over how our models handle private university data. We also ensured modularity so we could swap in new components without rewriting the core logic.
Additional Visuals from Prototype
Screenshot: Early Chatbot Response Example
This screenshot shows the chatbot responding to a student's question about course requirements using live document context.
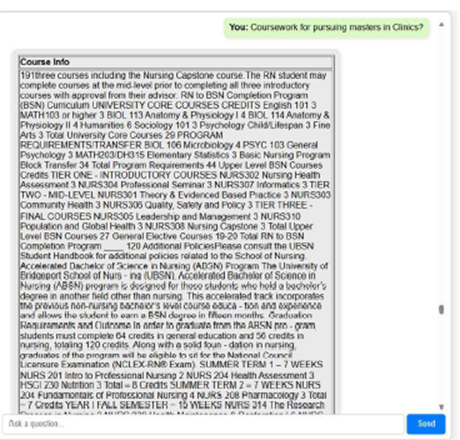
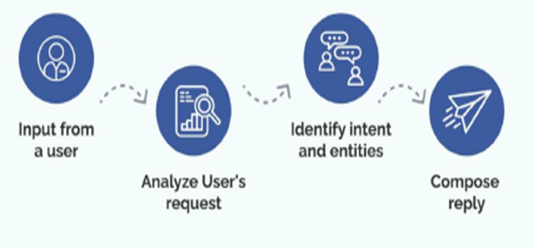
Diagram: Chatbot Query Lifecycle
This visual illustrates how a user query travels through embeddings, semantic search, prompt assembly, and finally generates a contextual answer.
Data Flow and RAG Pipeline
The system follows this structured flow:
[User Query]
↓
[Embedding Generation]
↓
[Vector Search in Milvus]
↓
[Relevant Context]
↓
[Prompt Assembly]
↓
[LLaMA2 Response]
↓
[Chatbot Reply]
This combination allows our model to avoid hallucinations and always ground its answers in up-to-date academic material.
Implementation Highlights
- Embeddings: We used sentence-transformers/all-MiniLM-L6-v2 to turn documents into searchable vectors.
- Security: IAM roles and encrypted transport ensured secure deployment with no PII exposure.
- Caching: We layered an LRU cache to reduce duplicate vector searches and lower costs.
- Scalability: Using SageMaker’s multi-model endpoints helped serve different departments (e.g., housing, bursar) efficiently.
- Custom Dataset Preparation: We used a mix of academic PDFs, previous FAQs, and helpdesk transcripts to fine-tune query handling for campus-specific language.
- Prompt Engineering: We iterated on prompt templates to better structure questions, reduce verbosity, and avoid hallucinated answers.
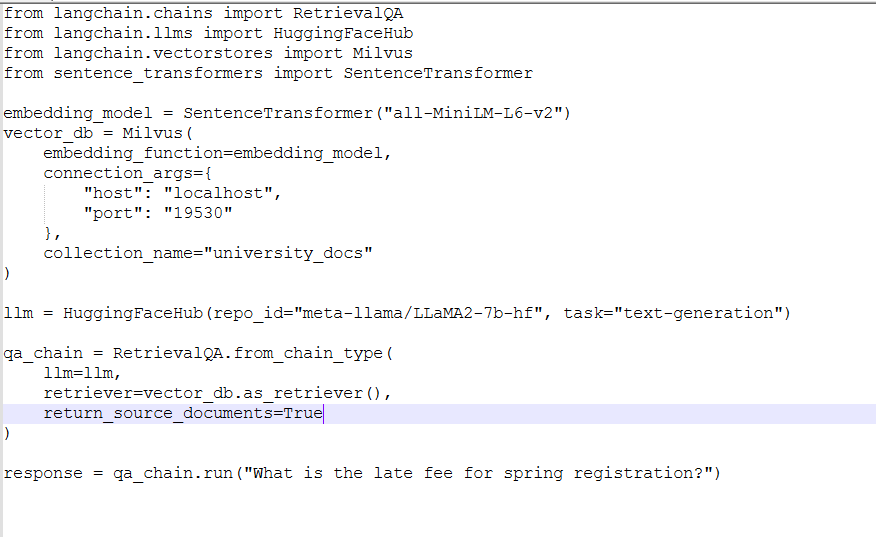
Example Code Snippets
LangChain RAG Setup
Caching Strategy

AWS SageMaker Invocation

Results and Metrics
After deploying our chatbot, we recorded measurable improvements:
- 70% reduction in helpdesk queries.
- <2 seconds average response time.
- 5+ languages supported using a single model and embeddings.
- Consistent tone and accurate answers, even for edge cases.
In addition, we saw a 40% increase in self-service usage through the chatbot UI, freeing up IT staff for more complex requests. Based on logs, the most common student questions were about fees, deadlines, course registration, and dorm assignments.
Lessons Learned
- Prompt Tuning Was More Effective Than Model Tuning
- Semantic Search Reduced Hallucinations by 60%
- Department-level context switching was best handled with metadata filters in Milvus
- Frontline feedback loops helped improve weak responses
- Throttling Milvus calls saved 20% on compute costs during peak hours
- Multilingual queries worked better when prompts included user locale explicitly
Future Roadmap
- Voice-to-text input using Whisper or Amazon Transcribe.
- Analytics dashboard for identifying repetitive queries.
- Specialized bots for each office: registrar, housing, bursar, and admissions.
- Expanding to other schools in the university system.
- Embedding sentiment feedback into query logs for evaluation.
- Live testing with multilingual students to fine-tune local dialect support.
Broader Applications
Although this project focused on a university setting, the architecture is flexible. Any organization dealing with internal knowledge — such as hospitals, banks, or HR departments — could use this same RAG stack to power their chat interfaces and automate support.
For example, a hospital might use this setup to help patients navigate insurance policies or appointment scheduling by retrieving specific documents on demand. Similarly, HR teams could automate policy Q&A by indexing employee handbooks and benefit guides.
Conclusion
Our LLaMA2-based chatbot proves that intelligent, real-time, multilingual campus assistants can be built using open-source tools and cloud infrastructure. With retrieval-augmented generation, contextual integrity is maintained — and student support scales efficiently. By combining open models, modern orchestration, and semantic search, we created a foundation that’s not just smart — it’s sustainable.
References
- Hugging Face. (2023). LLaMA2: Open Foundation Models for Research and Industry. https://huggingface.co
- AWS. (2023). AWS SageMaker: Cloud AI and Machine Learning Platform. https://aws.amazon.com/sagemaker/
- Milvus. (2022). Milvus: Open-Source Vector Database. https://milvus.io
- Lewis, M., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. https://arxiv.org/abs/2005.11401
Opinions expressed by DZone contributors are their own.
Comments