Automating Podcast Promotion With AI and Event-Driven Design
How I built an AI-powered LinkedIn post generator using Next.js, OpenAI's GPT and Whisper models, Apache Kafka, and Apache Flink.
Join the DZone community and get the full member experience.
Join For FreeI host two podcasts, Software Engineering Daily and Software Huddle, and often appear as a guest on other shows. Promoting episodes — whether I’m hosting or featured — helps highlight the great conversations I have, but finding the time to craft a thoughtful LinkedIn post for each one is tough. Between hosting, work, and life, sitting down to craft a thoughtful LinkedIn post for every episode just doesn’t always happen.
To make life easier (and still do justice to the episodes), I built an AI-powered LinkedIn post generator. It downloads podcast episodes, converts the audio into text, and uses that to create posts. It saves me time, keeps my content consistent, and ensures each episode gets the spotlight it deserves.
In this post, I break down how I built this tool using Next.js, OpenAI’s GPT and Whisper models, Apache Kafka, and Apache Flink. More importantly, I’ll show how Kafka and Flink power an event-driven architecture, making it scalable and reactive — a pattern critical for real-time AI applications.
Note: If you would like to just look at the code, jump over to my GitHub repo here.
Designing a LinkedIn Post Assistant
The goal of this application was pretty straightforward: help me create LinkedIn posts for the podcasts I’ve hosted or guested on without eating up too much of my time.
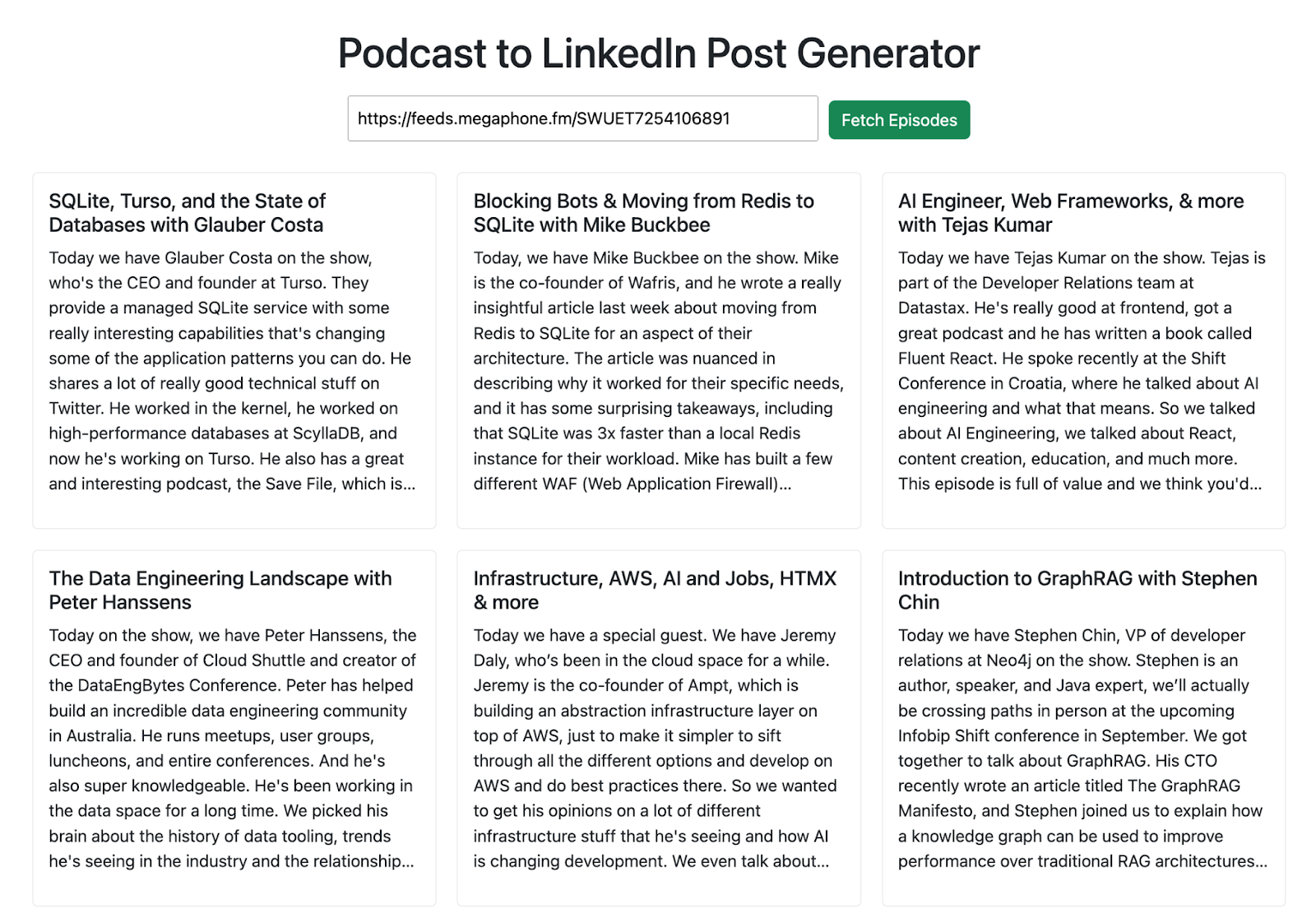
To meet my needs, I wanted to be able to provide a URL for a podcast feed, pull in the list of all episodes, and then generate a LinkedIn post for any episode I chose. Simple, right? Of course, there’s some heavy lifting under the hood to make it all work:
- Download the MP3 for the selected episode.
- Convert the audio to text using OpenAI’s Whisper model.
- Since Whisper has a 25MB file size limit, split the MP3 into smaller chunks if needed.
- Finally, use the transcription to assemble a prompt and ask an LLM to generate the LinkedIn post for me.
Beyond functionality, I also had another important goal: keep the front-end app completely decoupled from the AI workflow. Why? Because in real-world AI applications, teams usually handle different parts of the stack. Your front-end developers shouldn’t need to know anything about AI to build the user-facing app. Plus, I wanted the flexibility to:
- Scale different parts of the system independently.
- Swap out models or frameworks as the ever-growing generative AI stack evolves.
To achieve all this, I implemented an event-driven architecture using Confluent Cloud. This approach not only keeps things modular but also sets the stage for future-proofing the application as AI technologies inevitably change.
Why an Event-Driven Architecture for AI?
Event-driven architecture (EDA) emerged as a response to the limitations of traditional, monolithic systems that relied on rigid, synchronous communication patterns. In the early days of computing, applications were built around static workflows, often tied to batch processes or tightly coupled interactions.
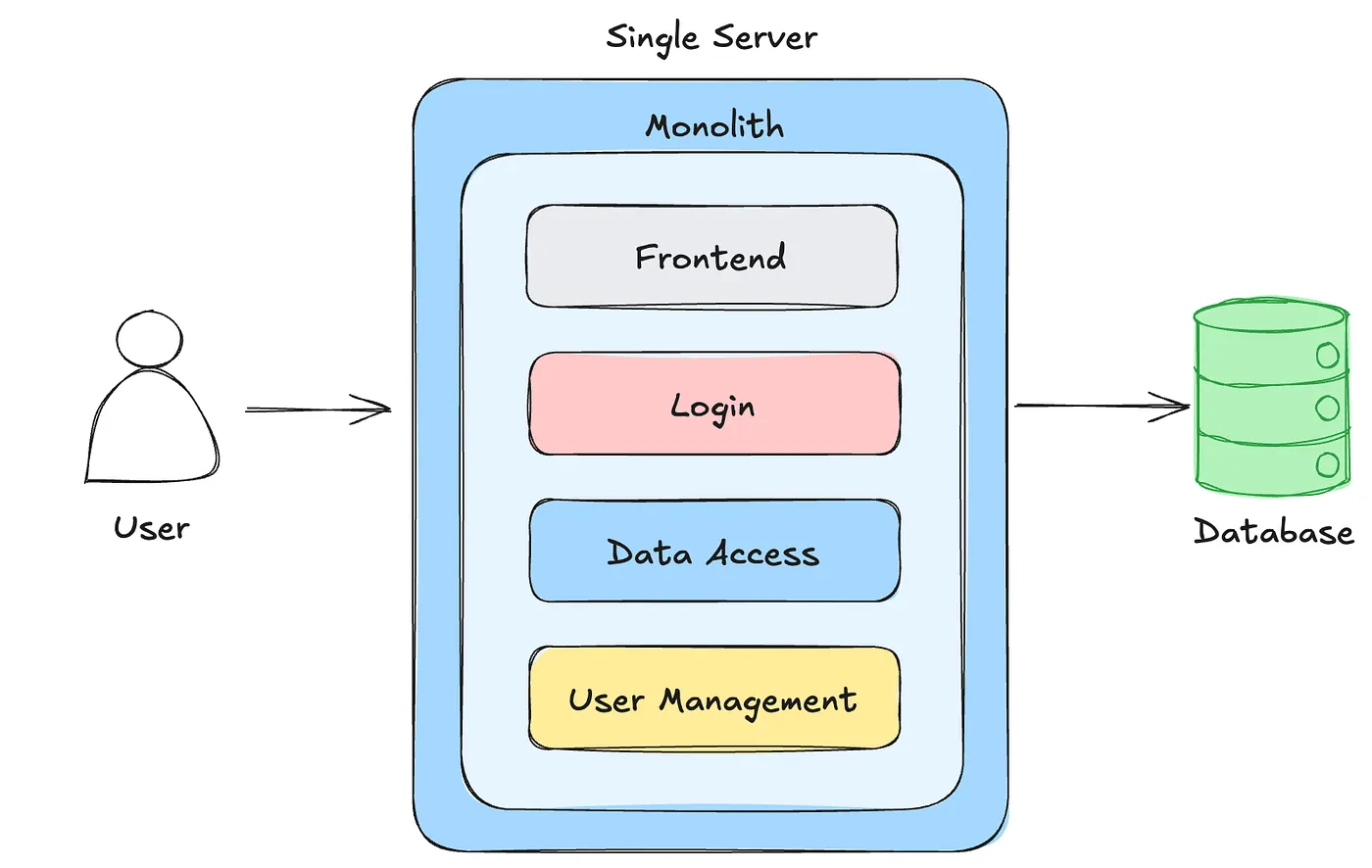
The architecture of a single server monolith
As technology evolved and the demand for scalability and adaptability grew — especially with the rise of distributed systems and microservices — EDA became a natural solution.
By treating events — such as state changes, user actions, or system triggers — as the core unit of interaction, EDA enables systems to decouple components and communicate asynchronously.
This approach uses data streaming, where producers and consumers interact through a shared, immutable log. Events are persisted in a guaranteed order, allowing systems to process and react to changes dynamically and independently.
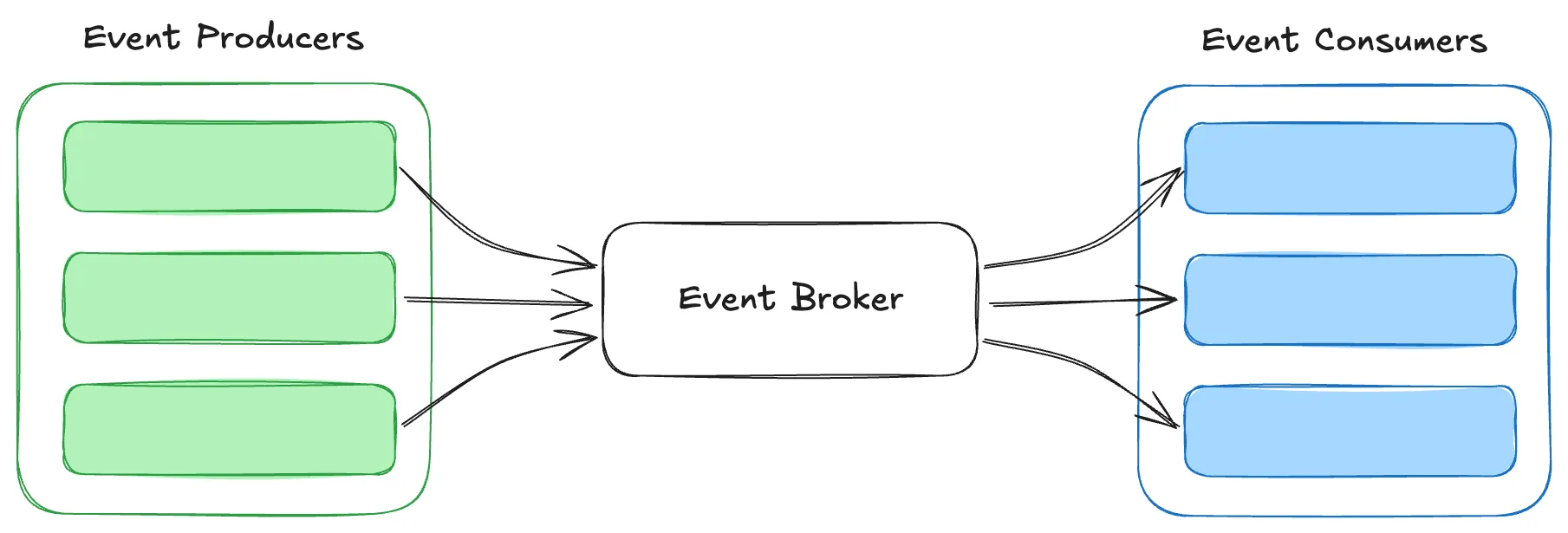
High-level overview of event producers and consumers
Decoupling My Web App from the AI Workflow
Bringing this back to the task at hand, my web application doesn’t need to know anything about AI.
To decouple the user-facing application from the AI, I used Confluent Cloud’s data streaming platform, which supports Kafka, Flink, and AI models as first-class citizens, making it easy to build a truly scalable AI application.
When a user clicks on a podcast listing, the app asks the server to check a backend cache for an existing LinkedIn post. If one is found, it’s returned and displayed.
You could store these LinkedIn posts in a database, but I chose a temporary cache since I don’t really need to persist these for very long.
If no LinkedIn post exists, the backend writes an event to a Kafka topic, including the MP3 URL and episode description. This triggers the workflow to generate the LinkedIn post.
The diagram below illustrates the full architecture of this event-driven system, which I explain in more detail in the next section.
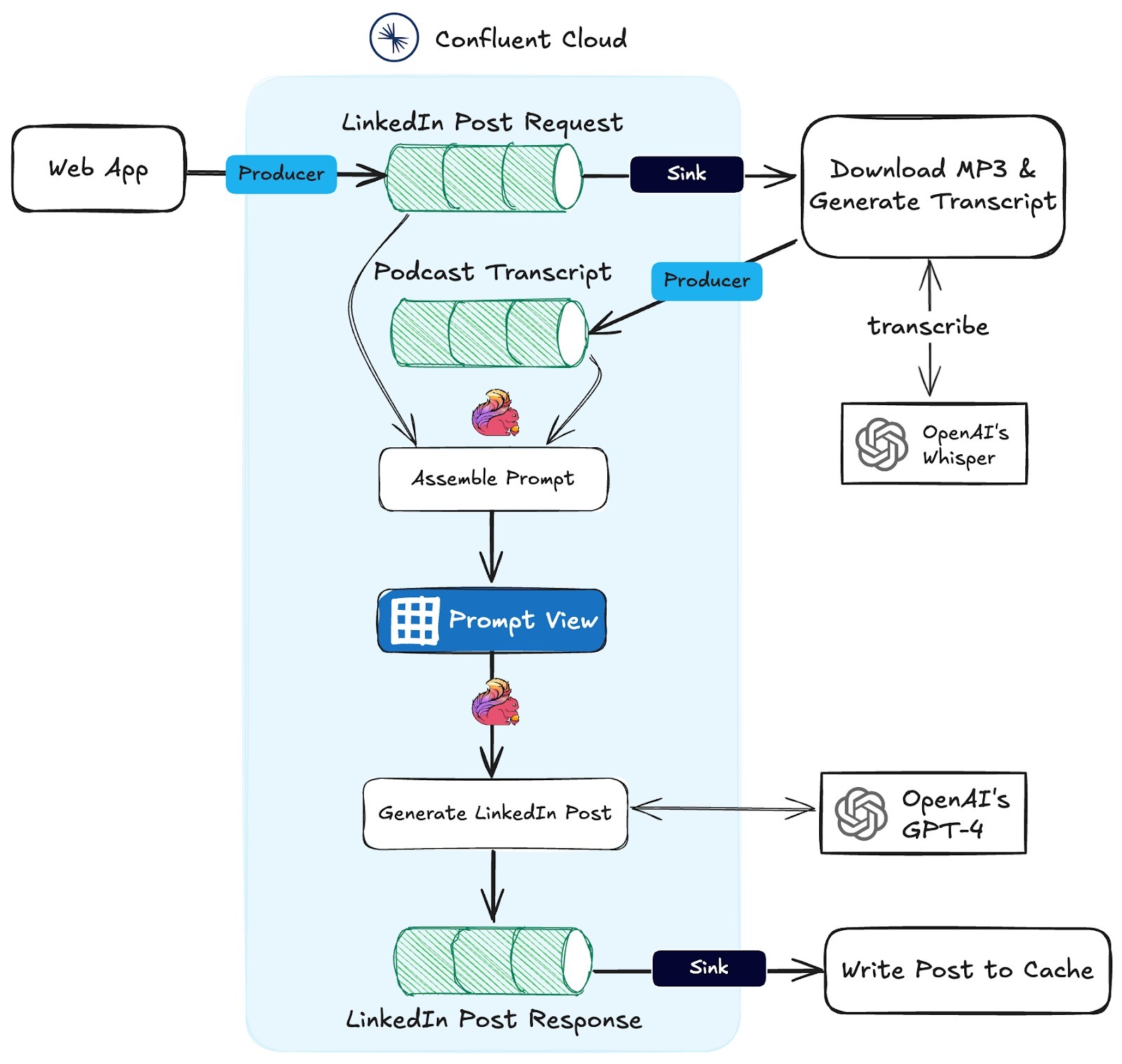
Downloading and Generating the Transcript
This part of the workflow is fairly straightforward. The web app writes requests to a Kafka topic named LinkedIn Post Request. Using Confluent Cloud, I configured an HTTP Sink Connector to forward new messages to an API endpoint.
The API endpoint downloads the MP3 using the provided URL, splits the file into 25 MB chunks if necessary, and processes the audio with Whisper to generate a transcript. As transcriptions are completed, they are written to another Kafka topic called Podcast Transcript.
This is where the workflow gets interesting — stream processing begins to handle the heavy lifting.
Generating the LinkedIn Post
Apache Flink is an open-source stream-processing framework designed to handle large volumes of data in real time. It excels in high-throughput, low-latency scenarios, making it a great fit for real-time AI applications. If you're familiar with databases, you can think of Flink SQL as similar to standard SQL, but instead of querying database tables, you query a data stream.
To use Flink for turning podcast episodes into LinkedIn posts, I needed to integrate an external LLM. Flink SQL makes this straightforward by allowing you to define a model for widely used LLMs. You can specify the task (e.g., text_generation) and provide a system prompt to guide the output, as shown below.
CREATE MODEL `linkedin_post_generation`
INPUT (text STRING)
OUTPUT (response STRING)
WITH (
'openai.connection'='openai-connection',
'provider'='openai',
'task'='text_generation',
'openai.model_version' = 'gpt-4',
'openai.system_prompt' = 'You are an expert in AI, databases, and data engineering.
You need to write a LinkedIn post based on the following podcast transcription and description.
The post should summarize the key points, be concise, direct, free of jargon, but thought-provoking.
The post should demonstrate a deep understanding of the material, adding your own takes on the material.
Speak plainly and avoid language that might feel like a marketing person wrote it.
Avoid words like "delve", "thought-provoking".
Make sure to mention the guest by name and the company they work for.
Keep the tone professional and engaging, and tailor the post to a technical audience. Use emojis sparingly.'
);To create the LinkedIn post, I first joined the LinkedIn Post Request topic and Podcast Transcript topic based on the MP3 URL to combine the episode description and transcript into a prompt value that I store in a view. Using a view improves readability and maintainability; while I could have embedded the string concatenation directly in the ml_predict call, doing so would make the workflow harder to modify.
CREATE VIEW podcast_prompt AS
SELECT
mp3.key AS key,
mp3.mp3Url AS mp3Url,
CONCAT(
'Generate a concise LinkedIn post that highlights the main points of the podcast while mentioning the guest and their company.',
CHR(13), CHR(13),
'Podcast Description:', CHR(13),
rqst.episodeDescription, CHR(13), CHR(13),
'Podcast Transcript:', CHR(13),
mp3.transcriptionText
) AS prompt
FROM
`linkedin-podcast-mp3` AS mp3
JOIN
`linkedin-generation-request` AS rqst
ON
mp3.mp3Url = rqst.mp3Url
WHERE
mp3.transcriptionText IS NOT NULL;Once the prompts are prepared in the view, I use another Flink SQL statement to generate the LinkedIn post by passing the prompt to the LLM model that I set up previously. The completed post is then written to a new Kafka topic, Completed LinkedIn Posts. This approach simplifies the process while keeping the workflow scalable and flexible.
INSERT INTO `linkedin-request-complete`
SELECT
podcast.key,
podcast.mp3Url,
prediction.response
FROM
`podcast_prompt` AS podcast
CROSS JOIN
LATERAL TABLE (
ml_predict(
'linkedin_post_generation',
podcast.prompt
)
) AS prediction;Writing the Post to the Cache
The final step is configuring another HTTP Sink Connector in Confluent Cloud to send the completed LinkedIn post to an API endpoint. This endpoint writes the data to the backend cache.
Once cached, the LinkedIn post becomes available to the front-end application, which automatically displays the result as soon as it’s ready.
Key Takeaways
Building an AI-powered LinkedIn post generator was more than just a way to save time — it was an exercise in designing a modern, scalable, and decoupled event-driven system.
As with any software project, choosing the right architecture upfront is vitally important. The generative AI landscape is evolving rapidly, with new models, frameworks, and tools emerging constantly. By decoupling components and embracing event-driven design, you can future-proof your system, making it easier to adopt new technologies without overhauling your entire stack.
Decouple your workflows, embrace event-driven systems, and ensure your architecture allows for seamless scaling and adaptation. Whether you’re building a LinkedIn post generator or tackling more complex AI use cases, these principles are universal.
If this project resonates with you, feel free to explore the code on GitHub or reach out to me on LinkedIn to discuss it further. Happy building!
Published at DZone with permission of Sean Falconer. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments