AWS Lambda Functions and Layers
Lambda layers provides a way to package dependencies in a clean way and deploy them in response to AWS Lambda calls.
Join the DZone community and get the full member experience.
Join For Free
Once upon a time, we used to have lambda functions with deployment packages reach 50MiB. We tended to test locally, zip all dependencies, and wait until it became available for testing after uploading the files. What makes it worse is when we have bad internet. Fortunately, now we have Layers!!
What are Lambda Layers?
In short, Lambda Layers is an approach that makes appending extra code to a Lambda function easier. It keeps the development package smaller and easy to maintain.
Also, this extra code can be shared by different functions. Do it once, and let the linking to other functions begin.
Didn’t get my idea? Check the sketch:
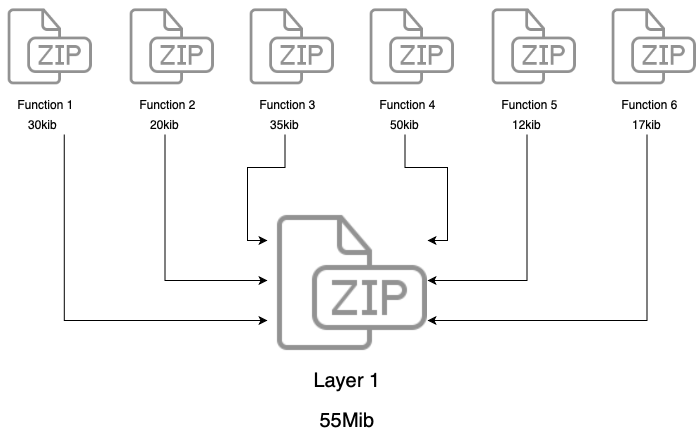
So, as we have shown, a layer is a container that compresses all your dependencies in a single file that can be consumed by multiple functions. It is a convenient way to contain the smallest size of your deployment package, helping to ensure that the dependencies are kept in the correct version. Think about it as a version control package that you update when needed.
Now we know what a Lambda layer is. Why should we use it?
Layers Benefits
Let me show you the benefits with examples that makes more sense.
Example 1: One function with a huge huge deployment package.
I used to work with huge datasets, and my aim was to make the system I'm working on serverless. One of my development issues was the OS, which is not the same as the Lambda environment (I use OS X and Lambda uses Linux). So, I code the function and test it locally? Cool, zip it and upload it. But wait, I forgot to remove a comma. The old approach is to fix that locally, do all the steps again because dependencies are over 50MiB, which is the maximum size Lambda lets you edit code online.
Imagine the loss in effort and time in this scenario. Thankfully, you can have the dependencies in a layer and can reference it. The job is done!
Example 2: One function, different dependencies.
I tend to organize my layers based on types like having one layer for data manipulation, one for media manipulation/conversion, and one for static functions (like input validation, function response messages, and DB connection functions). In this case, having one big layer is harder to maintain and puts you under threat of reaching the limit.
So, the best way is to split dependencies into different layers and link what is needed.
The same function I mentioned in the first example needs to validate the user inputs (layer 3) and then work with the data (layer 1). In this case, I can manage what gets executed when this function gets triggered. Another function usage is to make thumbnails (layer 2) and then update the account table in the database (layer 3). You can see the benefits right?
Example 3: Version control.
At some stages in development, some of your dependencies get an update. This update might contain some functions deprecations. This is not cool when you’re relying on it to do certain actions. You have a deadline and rules state that code upgrade can’t be done at this moment. Having your dependencies in a layer insure that these libraries won’t be updated until you do that.
Layers Disadvantages
Sure, almost everything could have downsides, and while they might not affect you, keeping them in mind won’t hurt.
I can summarize my challenges with layers in two points: creating and updating layers.
The reason that Layers is great is the same reason that it is time-consuming and hard to maintain.
I use AWS SAM every day in my job. I push new functions and fix others. Sometimes, new functions need new libraries, to be able to use it is whether to create a new layer or update an existed one. All this needs to be done manually.
Compile resources (since I’m working on OS X), zip it, upload it, get the link, create a new layer, reference it in the template and push it. That’s a lot!
Another downside could be the public understanding of the layer version. Basically, you can have a layer that has different versions, and you can reference any version you want. But, when you delete a specific version, what will happen in that case?
When you have a layer and you reference it in your function, saving this function will create some sort of a container that has the function and its dependencies. Now, it's an independent entity. Try to delete the referenced version, add an empty single line to your main function and save this change, then you’ll have an issue that these dependencies are gone. Because it will recreate this container and the declared version does not exist anymore, this will lead to either uploading the same layer version from a backup or updating the function accordingly.
Layers Limits
There are two main limitations you need to keep in mind: size and layers per function.
Size
You should know that a layer size unzipped should not pass 250MiB. Having files that are bigger than that will lead to functional failure. This function won’t work at all.
Layers per function
You can’t reference more than 5 layers for each function. Also, size limitation applies to this, too. These layers all together unzipped must follow the 250MiB rule.
Summary
AWS Lambda Layers is a great addition to the serverless architecture. Now, we can code, test and deploy heavy functions (in terms of purpose) in a small and easy way thanks to the sharing dependencies that layers provide. But, and it's a big but here, use it wisely. Try to understand your application well, and organize these layers based on purpose. Lambda Layers is a managed service from AWS, so you should expect hard limits and you need to be flexible.
Note: If you want to learn how to deploy your first layer, please click here.
Opinions expressed by DZone contributors are their own.
Comments