Why Use AWS Lambda Layers? Advantages and Considerations
If you are not using layers for your AWS Lambda function, it's time to reconsider it. This article will give you a glimpse into the implementation of Lambda layers.
Join the DZone community and get the full member experience.
Join For FreeI'm originally a .NET developer, and the breadth and depth of this framework are impressive. You probably know the phrase, "When all you have is a hammer, everything looks like a nail." Nevertheless, although I wrote a few articles about .NET-based Lambda function, this time, I decided to leave the hammer aside and look for another tool to serve the purpose.
Background
Choosing Python was an easy choice; it is simple to program, has many prebuilt libraries, and is supported well by the AWS Lambda function. So, this challenge is accepted!
Here's the background for the problem I wanted to solve:
Our product uses an external system that sends messages to our server, but sometimes a message is dropped. This inconsistency may reveal a bigger problem, so the goal was to raise an alert whenever a message hasn't arrived. Simple.
So, I wrote a Python script that compares the outgoing messages (from the external system) to the incoming messages (our Elasticsearch DB). I tested this script locally when the ultimate goal was to run it on our AWS environment. AWS Lambda is perfect for running Python-based scripts.
This article describes the journey for having a working AWS Lambda function based on Lambda layers.
First Hurdle: Connecting to Elasticsearch
Our data is stored on Elasticsearch, so I used the Python library to query our data and find this inconsistency. I thought it shouldn't be a problem until I ran the script for the first time and received the following error:
"The client noticed that the server is not Elasticsearch and we do not support this unknown product"
If you faced this problem too, you might not use the traditional Elastichsearch engine but its variant. In my case, I was using OpenSearch, a fork of Elasticsearch. Since the official Elasticsearch Python client checks for product compatibility, it rejected the connection to non-Elasticsearch servers.
It can be fixed by changing your library; instead of importing the Elasticsearch library, import OpenSearch.
pip install opensearch-py
#and in the Python script - import OpenSearch instead of Elasticsearch library
#from elasticsearch import Elasticsearch
from opensearchpy import OpenSearch
Besides the OpenSearch library, I also needed to install and import additional libraries for my sophisticated script:
- requests
- colorama (using coloured text)
- datetime (for using datetime, timedelta, timezone)
- pytz (timezone conversion)
- math
To summarize, I wrote a Python script that worked perfectly fine on my workstation. The next step was running the same logic on the AWS environment.
Second Hurdle: Python Packages in AWS Lambda Function
When I loaded the script to AWS, things went wrong.
First, I copied the Python libraries using my Lambda function; I downloaded them locally, for example:
pip install opensearch-py -t python/my-packages/Then, I tried to run the Lambda function but received an error:
AttributeError: module 'requests' has no attribute 'get'All the packages (e.g., requests, opensearch-py, etc.) were placed directly in the Lambda function's working folder, which led to namespace collisions and issues during import. When Python attempts to resolve imports, it may incorrectly reference your working folder as a module.
Diving deeper into this problem, I understood Python mistakenly treats the local folder as the library and tries to resolve the method get() from it.
To isolate the problem, I disabled the code for my REST requests and tried to test the connection to Elasticsearch. A similar error occurred when running a method call for the opensearch:
ImportError: cannot import name 'OpenSearch' from 'opensearchpy'To solve that problem, I could have changed the structure of the Python packages under the working directory. Nevertheless, I chose to move the Python libraries and place them elsewhere to better manage the packages, their version, and the dependencies.
In other words, I used Lambda layers.
The Solution: Using Layers
Why?
First, you can write a perfectly working AWS Lambda function without using Layers at all. Using external Python libraries, you can package them into your Lambda function by zipping the packages as part of the code.
However, layers with Python provide several advantages that enhance code modularity, reusability, and deployment efficiency. Layers are considered cross-function additional resources, managed separately under the Lambda service.
Lambda layers in Python streamline development, promote best practices, and simplify dependency management, making them a powerful tool for serverless application design.
Here's a summary of the key benefits:
1. Code Reusability: Sharing Across Multiple Functions
- Advantage: Common Python libraries or custom utilities can be shared across numerous Lambda functions without duplicating the code.
- Example: If several functions use
requestsoropensearch-py, you can package these dependencies in a layer and reuse them across all functions, reducing redundancy.
2. Reduced Deployment Package Size: Improve Simplicity and Cost Saving
- Advantage: Offloading large dependencies to a layer reduces the main deployment package size. This simplifies versioning and keeps your Lambda codebase lightweight. In addition, you save on storage and deployment time by reducing deployment size and avoiding duplicated dependencies.
- Example: A deployment package containing only your function code is smaller and easier to manage, while the heavy dependencies reside in a reusable layer. As for the cost saving, smaller deployment packages lead to less storage usage in S3 for Lambda deployments and faster upload times.
3. Faster Iteration
- Advantage: When only the code logic changes, you can update the function without repackaging or redeploying the dependencies in the layer.
- Example: Modify and deploy just the Lambda code while keeping the dependencies in the unchanged layer.
4. Consistency Across Functions
- Advantage: Layers ensure consistent library versions across multiple Lambda functions.
- Example: A shared layer with a specific version of
boto3orpandasguarantees that all functions rely on identical library versions, avoiding compatibility issues.
5. Improved Development Workflow and Collaboration
- Advantage: Developers can test shared libraries or modules locally, package them in a layer, and use them consistently in all Lambda functions. Layers can be shared within teams or across AWS accounts, facilitating collaboration.
- Example: A common utility module (e.g., custom logging or data transformation functions) can be developed once and used by all functions.
6. Support for Complex Dependencies
- Advantage: Layers simplify the inclusion of Python packages with native or compiled dependencies.
- Example: Tools like
numpyandscipyoften require compilation. Layers allow these dependencies to be built in a compatible environment (e.g., using Docker) and shared.
7. Simplified Version Management
- Advantage: Layers can be versioned, allowing you to update a specific layer without affecting other versions used by other functions. Each version has a unique ARN (AWS Resource Name); You can choose different versions for different AWS Lambda functions.
- Example: You can deploy a new version of a layer with updated libraries while keeping older Lambda functions tied to a previous version.
In general, the usage of layers increases when multiple Lambda functions use the same Python libraries or shared code. Nevertheless, I suggest using layers even if you have only a few Lambda functions as you set the foundations for future growth. With that, you keep layers modular and can focus only on specific functionality.
Setting the Layers' Priority
After loading the layers, you can associate them with your Lambda function. The merge order is a valuable feature for building the Lambda function. Layers are applied in a stacked order of priority, determining how files from multiple layers and the Lambda function's deployment package interact. Here's how Lambda resolves files and directories when using layers:
Function Deployment Package Takes the Highest Priority
- Files in the Lambda function's deployment package override files from all layers.
- If a file exists both in the deployment package and a layer, the file from the deployment package is used.
- Example:
- File
utils.pyexists in both the function package and a layer. - The version in the function deployment package will be used.
- File
The Last-Applied Layer Has a Higher Priority
- The last-added layer (highest in the stack) takes precedence if multiple layers contain the same file.
- Example:
- Layer 1 contains
config.json, layer 2 (added after Layer 1) also containsconfig.json. - The version from Layer 2 will override the version from Layer 1.
- Layer 1 contains
File System Union
- When running the Lambda function, files from all layers and the deployment package are combined into a single file system.
- If there are no conflicts (i.e., duplicate filenames), all files from layers and the function are available. If there are conflicts, the two rules mentioned above apply. Example:
- Layer 1 contains
lib1.py; Layer 2 containslib2.py. - Both
lib1.pyandlib2.pywill be available in the Lambda execution environment.
- Layer 1 contains
Practical Implications of Using Layers
1. Overriding Dependencies
- If you have multiple layers providing the same Python library (e.g.,
requests), the version from the layer with the highest priority (last-added) will be used. - Always ensure the correct versions of dependencies are in the right layers to avoid unintended overrides.
2. Custom Logic Overriding Layer Files
- Use the Lambda deployment package to override any files provided by layers if you need to make adjustments without modifying the layer itself.
3. Debugging Conflicts
- Conflicts between files in layers and the deployment package can lead to unexpected behavior. Carefully document and manage the contents of each layer.
Layer Priority in Execution
When the Lambda function runs:
- AWS Lambda combines files from all layers and the deployment package into the
/optdirectory and the root file system. - The Lambda environment resolves file paths based on the priority stack mentioned above:
- Files from the deployment package override files from
/opt. - Files from the last-added layer in
/optoverride earlier layers.
- Files from the deployment package override files from
Best Practices for Managing Layer Priority
1. Separate Concerns
- Use distinct layers for different purposes (e.g., one for shared libraries, another for custom utilities).
2. Version Control
- Explicitly version layers to ensure reproducibility and avoid conflicts when updates are applied.
3. Minimize Overlap
- Avoid including duplicate files or libraries in multiple layers to prevent unintentional overrides.
4. Test Layer Integration
- Test Lambda functions thoroughly when adding or updating layers to identify early conflicts.
By understanding the layer priority and resolution process, you can effectively design and manage Lambda functions to ensure predictable behavior and seamless integration of dependencies. Let me know if you'd like further clarification!
Building Python Packages
Download the package's file locally if you want to use a pre-built Python package as a layer. You can specify the requested version for this package, but it's not mandatory.
pip install <package-name>==<version> --target <local-folder>
## for example:
pip install requests==2.32 --target c:\tempOnce you obtain the files locally, place them in a folder hierarchy. The Python layer should have the following structure:
├── <package-folder-name>/
│ ├────── python/
│ ├────── lib/
│ ├────── python3/
│ ├────── site-packages/
│ └────── <package-content>
Do not overlook the Python version in the folder name (i.e. python3.0), which must align with your Lambda function's Python version. For instance:
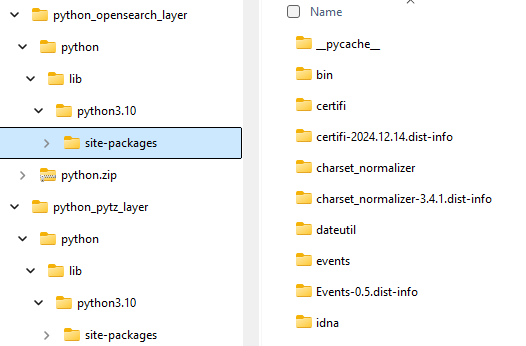
After creating this hierarchy with the Python package's files, you only need to zip and load it as a Lambda layer.
Here's how I copied the opensearch Python package locally:
mkdir opensearch_layer
cd opensearch_layer
mkdir -p python/lib/python3.10/site-packages
pip install opensearch-py -t python/lib/python3.10/site-packages/
zip -r opensearch_layer.zip pythonSince my Lambda function was based on Python3.10, I named the python folder accordingly. With that, you can create your own Python packages locally and load them as layers to your Lambda environment.
Wrapping Up
Lambda Layers make managing shared code and dependencies across multiple Lambda functions easy, keeping things organized and straightforward. By separating common libraries or utilities, layers help reduce the size of your deployment packages and make updates quicker — no need to redeploy your entire function to change a dependency.
This not only saves time but also keeps your functions consistent and reusable. With Lambda Layers, building and maintaining serverless applications becomes smoother and more efficient, leaving you more time to focus on creating great solutions.
I hope you find this content valuable.
Keep on coding!
Opinions expressed by DZone contributors are their own.
Comments