AWS NoSQL Performance Lab Using Python
This is a coding lab to evaluate the performance of AWS-managed NoSQL databases such as DynamoDB, Cassandra, Redis, and MongoDB using Python.
Join the DZone community and get the full member experience.
Join For FreeIn most financial firms, online transaction processing (OLTP) often relies on static or infrequently updated data, also called reference data. Reference data sources don’t always require ACID transaction capabilities, rather need support for fast read queries often based on simple data access patterns, and event-driven architecture to ensure the target systems remain up-to-date. NoSQL databases emerge as ideal candidates to meet these requirements, and cloud platforms such as AWS offer managed and highly resilient data ecosystems.
In this article, I am not going to determine which AWS NoSQL database is better: the concept of a better database only exists within a specific purposeful context. I will share a coding lab to measure the performance of AWS-managed NoSQL databases such as DynamoDB, Cassandra, Redis, and MongoDB.
Performance Testing
I will start by defining the performance test case, which will concurrently insert a JSON payload 200 times and then read it 200 times.
JSON Payload
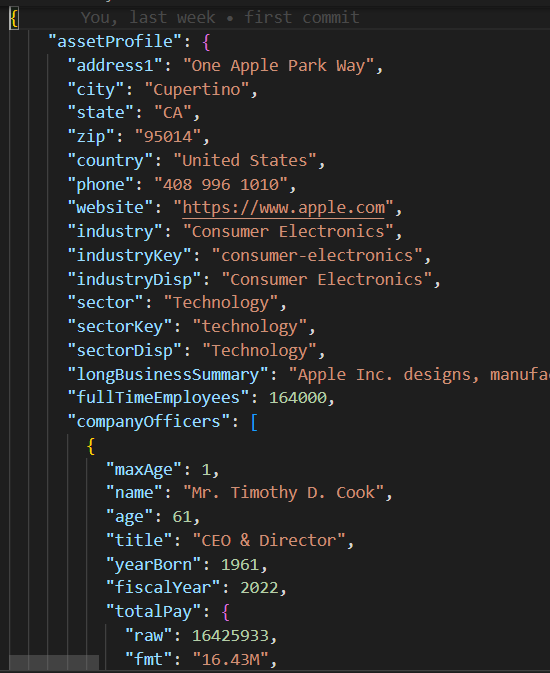
The base/parent class in base_db.py implements the test case logic of executing 10 concurrent threads to create and read 200 records.
#imports
.....
class BaseDB:
def __init__(self, file_name='instrument.json', threads=10, records=20):
...................................
def execute(self):
create_threads = []
for i in range(self.num_threads):
thread = threading.Thread(
target=self.create_records, args=(i,))
create_threads.append(thread)
thread.start()
for thread in create_threads:
thread.join()
read_threads = []
for i in range(self.num_threads):
thread = threading.Thread(target=self.read_records, args=(i,))
read_threads.append(thread)
thread.start()
for thread in read_threads:
thread.join()
self.print_stats()
Each thread executes the write/read routine in the create_records and read_records, respectively. Notice that these functions do not include any database-specific logic, but rather, measure the performance of each read-and-write execution.
def create_records(self, thread_id):
for i in range(1, self.num_records + 1):
key = int(thread_id * 100 + i)
start_time = time.time()
self.create_record(key)
end_time = time.time()
execution_time = end_time - start_time
self.performance_data[key] = {'Create Time': execution_time}
def read_records(self, thread_id):
for key in self.performance_data.keys():
start_time = time.time()
self.read_record(key)
end_time = time.time()
execution_time = end_time - start_time
self.performance_data[key]['Read Time'] = execution_timeOnce the test case is executed, the print_stats function prints the execution metrics such as the read/write mean and the standard deviation (stdev) values, which indicate database read/write performance and consistency (smaller stdev implies more consistent execution performance).
def print_stats(self):
if len(self.performance_data) > 0:
# Create a Pandas DataFrame from performance data
df = pd.DataFrame.from_dict(self.performance_data, orient='index')
if not df.empty:
df.sort_index(inplace=True)
# Calculate mean and standard deviation for each column
create_mean = statistics.mean(df['Create Time'])
read_mean = statistics.mean(df['Read Time'])
create_stdev = statistics.stdev(df['Create Time'])
read_stdev = statistics.stdev(df['Read Time'])
print("Performance Data:")
print(df)
print(f"Create Time mean: {create_mean}, stdev: {create_stdev}")
print(f"Read Time mean: {read_mean}, stdev: {read_stdev}")
NoSQL Code
Unlike relational databases that support standard SQL, each NoSQL database has its own SDK. The child test case classes for each NoSQL database only need to implement a constructor and create_record/read_recod functions that contain proprietary database SDK to instantiate a database connection and to create/read records in a few lines of code.
DynamoDB Test Case
import boto3
from base_db import BaseDB
class DynamoDB (BaseDB):
def __init__(self, file_name='instrument.json', threads=10, records=20):
super().__init__(file_name, threads, records)
dynamodb = boto3.resource('dynamodb', region_name='us-east-1')
table_name = 'Instruments'
self.table = dynamodb.Table(table_name)
def create_record(self, key):
item = {
'key': key,
'data': self.json_data
}
self.table.put_item(Item=item)
def read_record(self, key):
self.table.get_item(Key={'key': key})
if __name__ == "__main__":
DynamoDB().execute()AWS Setup
To execute these performance test cases in an AWS account, you should follow these steps:
- Create an EC2 IAM role with privileges to access the required AWS data services.
- Launch an EC2 instance and assign the newly created IAM role.
- Create each NoSQL database instance.
IAM Role![IAM Role]()

DynamoDB Table

Cassandra Keyspace/Table
Please note the DB host and credentials were hardcoded and removed in the mongo_db.py and redis_db.py modules and will need to be updated with the corresponding database connection setting for your AWS account. To connect to DynamoDB and Cassandra, I opted to use the Boto3 session credentials temporarily assigned to the db_performnace_iam_role IAM Role. This code will run in any AWS account in the East 1 region without any modification.
class CassandraDB(BaseDB):
def __init__(self, file_name='instrument.json', threads=10, records=20):
super().__init__(file_name=file_name, threads=threads, records=records)
self.json_data = json.dumps(
self.json_data, cls=DecimalEncoder).encode()
# Cassandra Keyspaces configuration
contact_points = ['cassandra.us-east-1.amazonaws.com']
keyspace_name = 'db_performance'
ssl_context = SSLContext(PROTOCOL_TLSv1_2)
ssl_context.load_verify_locations('sf-class2-root.crt')
ssl_context.verify_mode = CERT_REQUIRED
boto_session = boto3.Session(region_name="us-east-1")
auth_provider = SigV4AuthProvider(session=boto_session)
cluster = Cluster(contact_points, ssl_context=ssl_context, auth_provider=auth_provider,
port=9142)
self.session = cluster.connect(keyspace=keyspace_name)Connect to the EC2 instance (I used the Session Manager), and run the following Shell script to perform these tasks:
- Install Git.
- Install Pythion3.
- Clone the GitHub performance_db repository.
- Install and activate the Python3 virtual environment.
- Install 3rd party libraries/dependencies.
- Execute each test case.
sudo yum install git
sudo yum install python3
git clone https://github.com/dshilman/db_performance.git
sudo git pull
cd db_performance
python3 -m venv venv
source ./venv/bin/activate
sudo python3 -m pip install -r requirements.txt
cd code
sudo python3 -m dynamo_db
sudo python3 -m cassandra_db
sudo python3 -m redis_db
sudo python3 -m mongo_dbYou should see the following output for the first two test cases:
(venv) sh-5.2$ sudo python3 -m dynamo_db Performance Data: Create Time Read Time 1 0.336909 0.031491 2 0.056884 0.053334 3 0.085881 0.031385 4 0.084940 0.050059 5 0.169012 0.050044 .. ... ... 916 0.047431 0.041877 917 0.043795 0.024649 918 0.075325 0.035251 919 0.101007 0.068767 920 0.103432 0.037742
[200 rows x 2 columns] Create Time mean: 0.0858926808834076, stdev: 0.07714510154026173 Read Time mean: 0.04880355834960937, stdev: 0.028805479258627295 Execution time: 11.499964714050293 |
(venv) sh-5.2$ sudo python3 -m cassandra_db Performance Data: Create Time Read Time 1 0.024815 0.005986 2 0.008256 0.006927 3 0.008996 0.009810 4 0.005362 0.005892 5 0.010117 0.010308 .. ... ... 916 0.006234 0.008147 917 0.011564 0.004347 918 0.007857 0.008329 919 0.007260 0.007370 920 0.004654 0.006049
[200 rows x 2 columns] Create Time mean: 0.009145524501800537, stdev: 0.005201661271831082 Read Time mean: 0.007248317003250122, stdev: 0.003557610695674452 Execution time: 1.6279327869415283 |
Test Results
| DynamoDB | Cassandra | MongoDB | Redis | |
|---|---|---|---|---|
| Create | mean: 0.0859 stdev: 0.0771 |
mean: 0.0091 stdev: 0.0052 |
mean: 0.0292 std: 0.0764 |
mean: 0.0028 stdev: 0.0049 |
| Read | mean: 0.0488 stdev: 0.0288 |
mean: 0.0072 stdev: 0.0036 |
mean: 0.0509 std: 0.0027 |
mean: 0.0012 stdev: 0.0016 |
| Exec Time | 11.45 sec | 1.6279 sec | 10.2608 sec | 0.3465 sec |
My Observations
- I was blown away by Cassandra’s fast performance. Cassandra support for SQL allows rich access pattern queries and AWS Keyspaces offer cross-region replication.
- I find DynamoDB's performance disappointing despite the AWS hype about it. You should try to avoid the cross-partition table scan and thus must use an index for each data access pattern. DynamoDB global tables enable cross-region data replication.
- MongoDB has a very simple SDK, is fun to use, and has the best support for the JSON data type. You can create indexes and run complex queries on nested JSON attributes. As new binary data formats are emerging, MongoDB may lose its appeal.
- Redis performance is amazingly fast, however, at the end of the day, it’s a key/value cache even if it supports complex data types. Redis offers powerful features such as pipelining and scripting to further improve query performance by passing code to Redis to execute on the server side.
Conclusion
In conclusion, choosing the AWS-managed NoSQL database for your enterprise reference data platform depends on your specific priorities. If performance and cross-region replication are your primary concern, AWS Cassandra stands out as a clear winner. DynamoDB integrates well with other AWS services such as Lambda and Kinesis and therefore is a great option for AWS native or serverless architecture. For applications requiring robust support for JSON data types, MongoDB takes the lead. However, if your focus is on fast lookup or session management for high availability, Redis proves to be an excellent option. Ultimately, the decision should align with your organization's unique requirements.
As always, you can find the code in the GitHub repo linked earlier in this article (see Shell script task #3 above). Feel free to contact me if you need help running this code or with the AWS setup.
Opinions expressed by DZone contributors are their own.
Comments