Beyond Outages: Building True Resilience After the AWS Outage
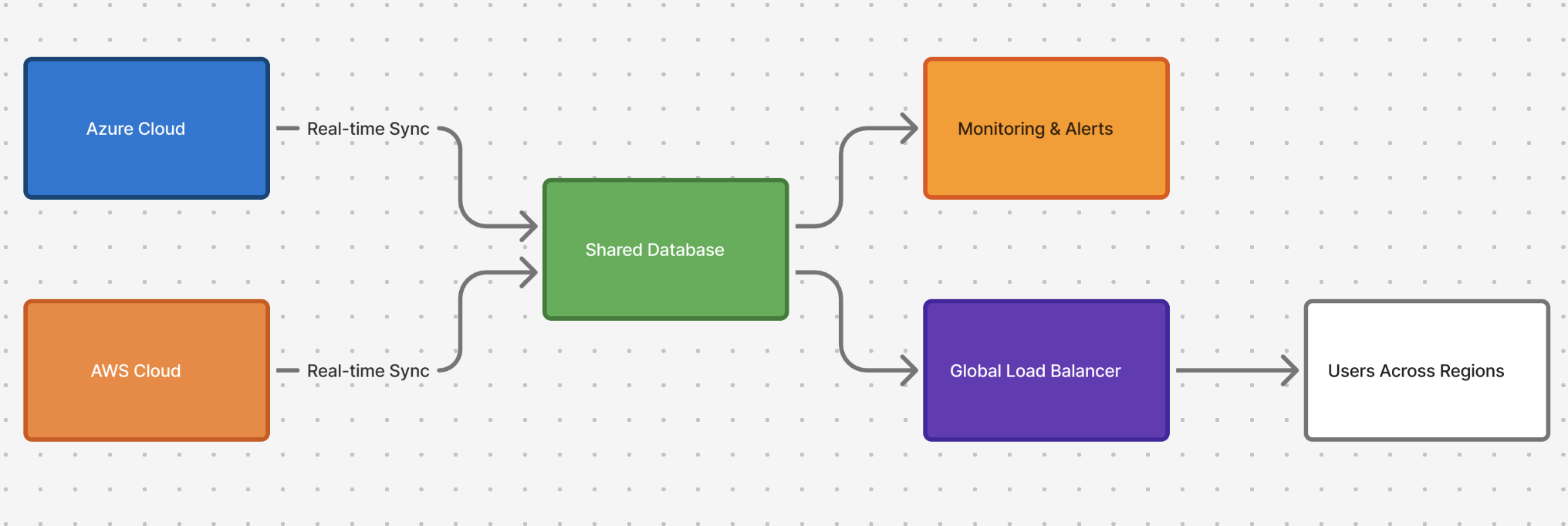
True resilience means multi-cloud architecture, spreading critical workloads across AWS, Azure, or GCP with shared data, global load balancing, and unified monitoring.
Join the DZone community and get the full member experience.
Join For FreeWhen AWS went dark last week, the internet seemed to take a deep breath with it. Streaming services froze, fintech apps stalled, and even smart home devices blinked out. For a few hours, much of the digital world that relied on AWS ran on borrowed patience.
It wasn't just an outage; it was a reminder. A reminder that even the most reliable cloud can still have cloudy days (pun intended).
The Wake-Up Call
The October 2025 AWS started with a DNS failure in the us-east-1 region, the same region that quietly powers a huge share of the world's online activity.
What began as a small hiccup rippled outward through APIs, control planes, and load balancers, creating a chain reaction that affected everything from food delivery apps to enterprise systems.
Within hours, AWS recovered. But what it left behind was a simple truth that technologists have long known but too often ignore:
High availability within a single cloud is not the same as resilience across multiple clouds.
High Availability Isn't the Same as Resilience
Most modern systems already follow best practices, i.e., multiple availability zones, auto-scaling, and self-healing clusters.
Those protect you from local hardware or network issues, but they don't protect you when the provider itself goes down. When an entire region or control plane fails, all that internal redundancy stays trapped inside the same boundary. And if your business depends on that single boundary, so does your downtime.
True resilience means asking a harder question:
What happens when the provider fails, not the server, not the zone, but the provider?
That's where multi-cloud architecture comes in.
Thinking Beyond a Single Cloud
Multi-Cloud doesn't mean running everything everywhere. It means knowing which parts of your system are too critical to fail, and giving them a second home.
For many teams, the first step is an active-passive setup.
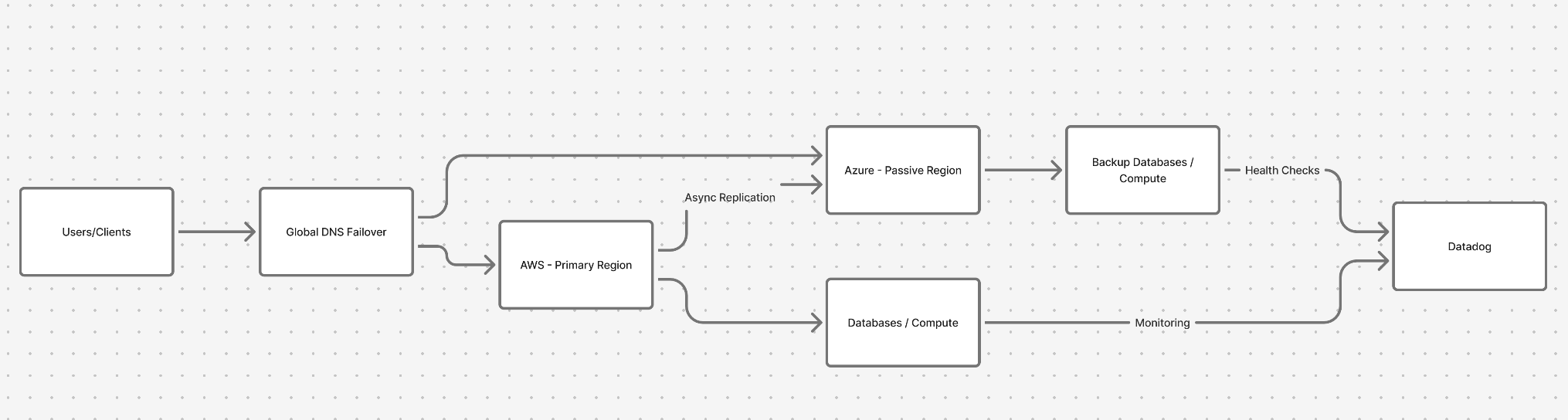
Your primary workload lives on AWS -> EC2, Lambda, DynamoDB.
A secondary environment, maybe on Azure or Google Cloud, stays synchronised but idle.
If the primary environment becomes unhealthy, traffic automatically reroutes via a global DNS service or a load balancer such as Cloudflare or NS1.
It's not perfect. Replication lag can cause brief delays, but it keeps the service alive when your primary cloud is unavailable.
And for most businesses, that's the difference between an interruption and a crisis.
When Downtime Isn't an Option
For mission-critical systems, active-active setups take it a step further. Here, both clouds are alive all the time, serving users in parallel.
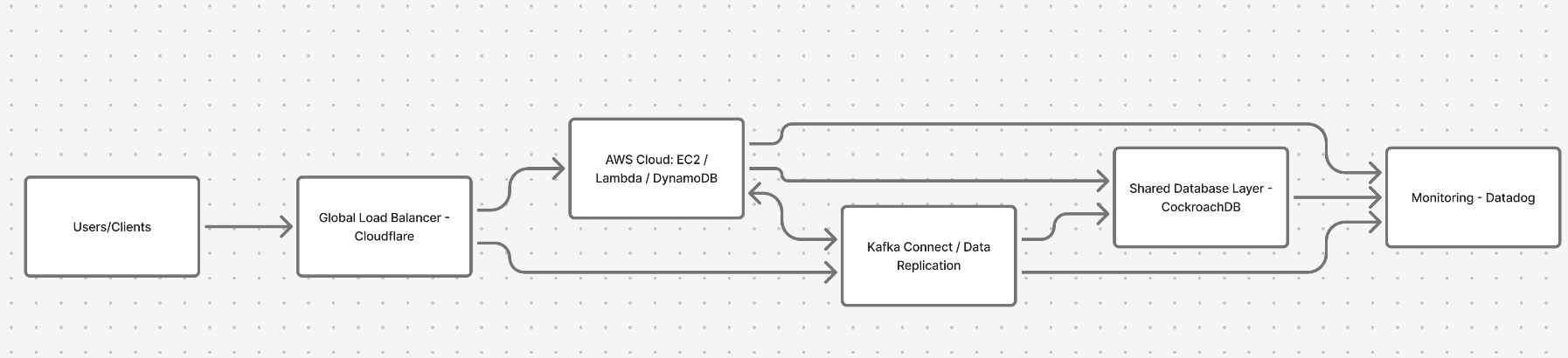
They share a distributed database (CockroachDB, YugabyteDB, Spanner) or a real-time event pipeline (Kafka, Debezium) that keeps data consistent between them.
A global load balancer watches latency and routes requests to whatever provider is healthier.
This approach is more complex and more expensive, but it delivers near-zero downtime, even if one provider completely fails.
If your business runs financial transactions, healthcare data, or high-volume logistics, this kind of setup isn't a luxury but rather an insurance.
The Hard Part Isn't Compute. It is Data.
I have seen this misconception quite a lot. Compute redundancy is easy, but Data consistency is not.
When you write to DynamoDB in AWS and CosmoDB in Azure, which record wins in a conflict? When latency spikes, how do you prevent divergent states?
Distributed databases handle much of this automatically, but you still need to plan for schema design, quorum rules, and how your application reconciles eventual consistency.
Identity is another overlooked weakness. If your logi system relies on AWS Cognito, and Cognito goes down, users can't authenticate, even if your backup infrastructure is ready.
That's why many organisations move identity to neutral services like Okta or Auth0, which remain reachable across providers.
And finally, there's monitoring. You can't fix what you can't see.
If your observability stops at CloudWatch, you're blind the moment AWS fails.
Cross-cloud observability platforms like Datadog or OpenTelemetry ensure you always know which side of your system is healthy and which isn't.
Infrastructure as Code Makes It Possible
Ten years ago, maintaining multiple clouds would've been chaos. Today, tools like Terraform and Pulumi make it achievable, even elegant.
You can define your infrastructure once, abstract cloud-specific differences, and deploy identical environments across providers. Version control ensures consistency, and CI/CD pipelines can spin up or tear down environments as needed. Automated tests can validate that your backup environment actually works and not just in theory, but in practice.
That's what turns multi-cloud from an expensive idea into an operational reality.
The Cost of Downtime vs. The Cost of Readiness
Critics often say, "Multi-cloud is too expensive." And it can be. But outages are expensive too, far more than the cost of readiness.
Analysts estimate that the 2025 AWS outage cost hundreds of millions of dollars in global losses. For some businesses, even an hour of downtime means lost transactions, breached SLAs, and reputational damage that takes months to rebuild. So, the real comparison isn't AWS vs. Azure pricing. It's uptime vs. reputation.
When your system becomes infrastructure for others (APIs, financial services, logistics), your reliability becomes their dependency.
Multi-cloud isn't just about infrastructure. It's about trust.
A Practical Example
Imagine a global tax calculation service that processes thousands of transactions per minute. It primarily runs on AWS, using Lambda and DynamoDB. During an outage, those calculations get stalled, and every integrated customer feels it.
Now, imagine a secondary environment in Azure.
The same service logic runs on Azure Functions, backed by Cosmos DB that syncs continuously with DynamoDB.
A Cloudflare load balancer monitors health and shifts traffic automatically if AWS latency rises.
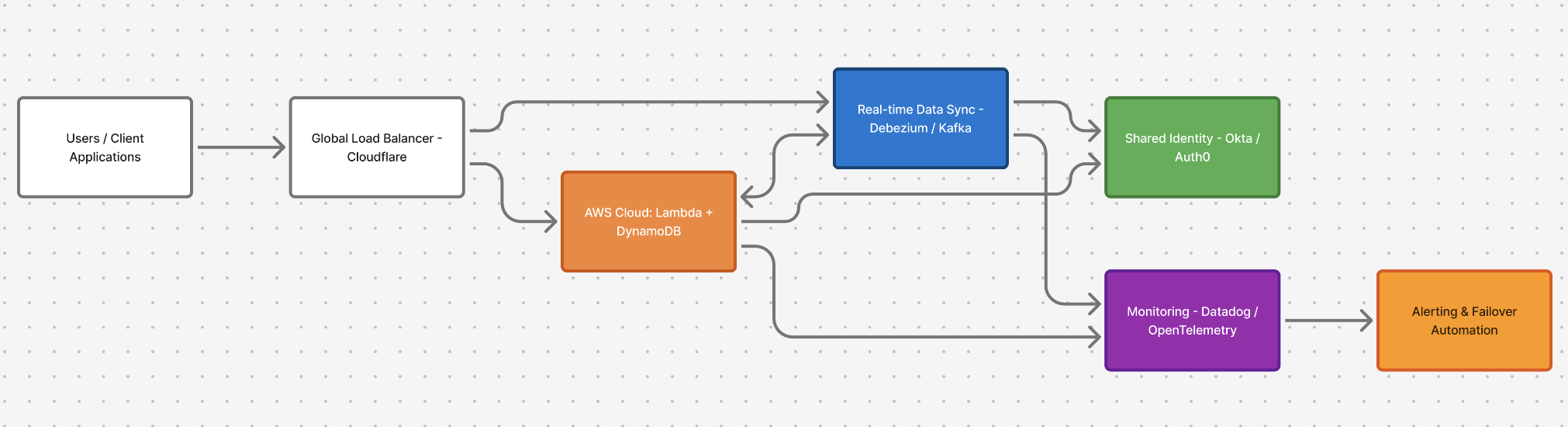
From the user's perspective, nothing changes. The system stays online.
That's resilience. Not luck, but preparation.
The Takeaway
Outages will keep happening. In fact, it is more common than not that it will. DNS issues, expired certificates, misconfigurations, they're part of the internet's DNA. The difference between a headline and a hiccup lies in your architecture. You don't need to duplicate everything.
Start small: Replicate critical data, externalise identity, add cross-cloud monitoring, and test failover drills. Over time, resilience becomes your default posture and not a contingency plan.
The 2025 AWS outage wasn't a failure of technology. It was a reminder that technology, like everything else, needs backup plans.
The question isn't whether your provider will fail again; it's whether you'll be ready when it does.
If this outage got you thinking about your own infrastructure, good. That's the first step towards real resilience.
Because the next time the cloud stumbles, your system doesn't have to fall with it.
Opinions expressed by DZone contributors are their own.
Comments