Why Infrastructure Efficiency Is Becoming the New Cloud Profitability Metric
Learn about how cost per workload, operational efficiency, and infrastructure architecture are reshaping cloud profitability and TCO analysis.
Join the DZone community and get the full member experience.
Join For FreeInfrastructure efficiency is rapidly becoming one of the most important factors determining profitability for cloud providers, managed service providers, and SaaS companies.
For years, infrastructure growth followed a simple formula: add more servers, more storage, and more capacity whenever demand increased. That model worked when hardware prices consistently declined, and inefficiencies could be absorbed through growth.
Those conditions no longer exist.
Today, providers face rising costs for memory, enterprise SSDs, GPUs, power, cooling, and colocation, while customers continue to expect lower pricing, better performance, stronger SLAs, and faster service delivery.
Several industry shifts have fundamentally changed infrastructure economics. Changes in virtualization licensing models have increased costs for many organizations. AI adoption has driven demand for GPUs, high-capacity memory, and high-performance storage. Power and colocation costs continue to rise globally, while sovereign cloud initiatives are creating demand for regional infrastructure that must compete economically with hyperscale cloud providers.
The challenge is clear: infrastructure costs are rising faster than revenue.
What Does a Workload Really Cost?
Infrastructure efficiency ultimately comes down to a simple question: what does it cost to deliver a workload?
Customers do not buy servers, storage systems, or software licenses. They buy virtual machines, Kubernetes clusters, databases, AI environments, SaaS applications, and business services.
The true cost of delivering those workloads includes much more than infrastructure hardware:
- Software licensing
- Power and cooling
- Colocation
- Network connectivity
- Storage
- Capacity buffers
- Staffing and operations
- Support and SLA commitments
The providers that achieve the lowest cost per workload while maintaining performance and service quality gain a significant competitive advantage.
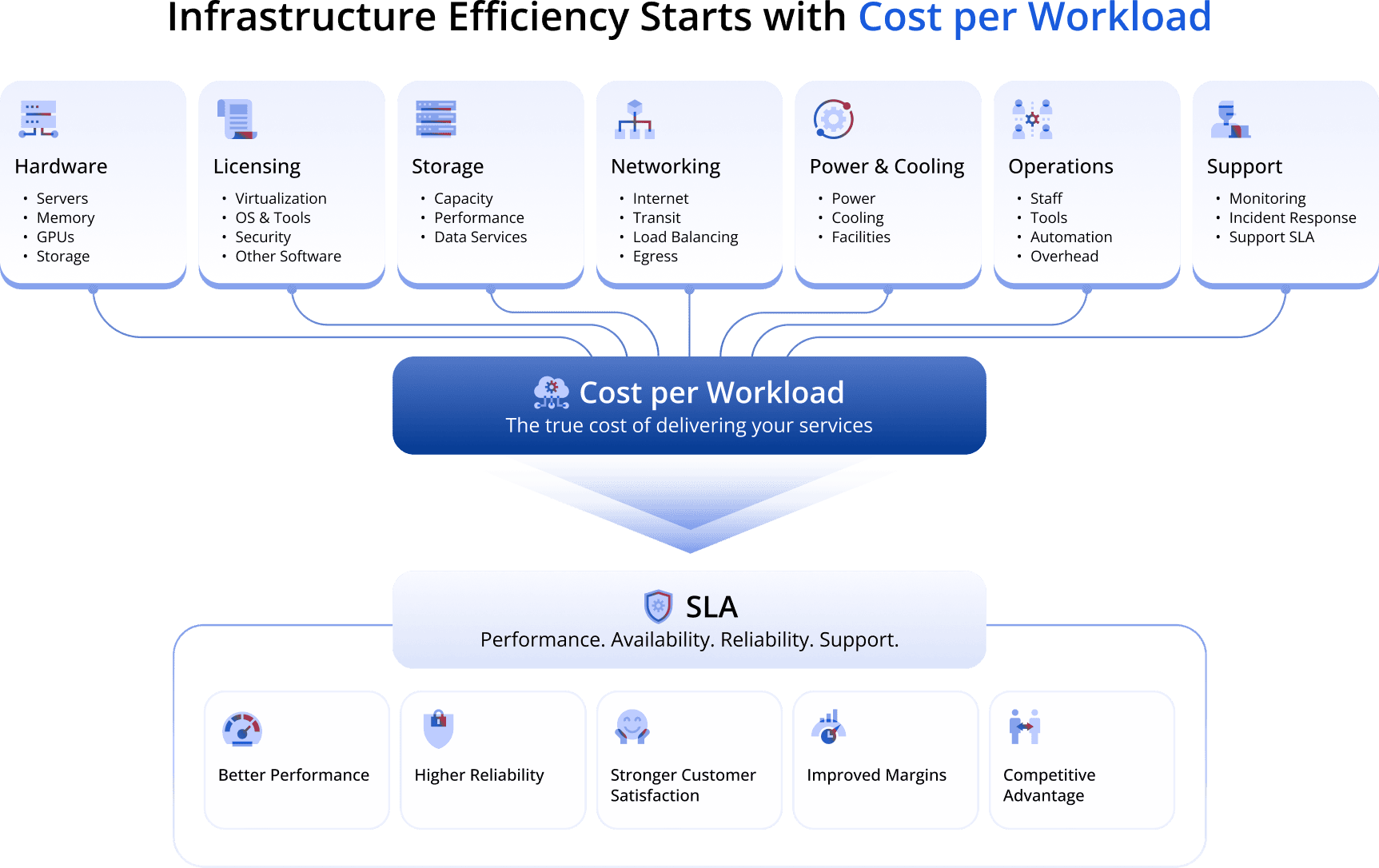
As infrastructure costs continue to increase, "cost per workload delivered" is becoming a useful framework for evaluating efficiency. Unlike traditional metrics focused solely on hardware utilization or licensing costs, this approach considers the complete economics of delivering customer-facing services.
Beyond Infrastructure Utilization
Infrastructure efficiency is not measured only by CPU, memory, or storage utilization.
Operational metrics often have an equally significant impact on the cost of delivering workloads. Examples include administrator-to-server ratio, administrator-to-VM ratio, workload deployment times, incident resolution times, and the number of infrastructure platforms that must be maintained.
Cost alone is also a misleading metric. A workload delivered at lower cost may also deliver lower performance, higher contention, or slower support response times. A virtual machine with two vCPUs does not necessarily provide the same amount of usable compute across platforms. CPU oversubscription ratios, noisy-neighbor effects, storage latency, network performance, and support commitments all influence the actual customer experience.
The relevant metric is not simply cost per workload, but cost per workload delivered at a defined SLA.
Architectural Choices and Efficiency
Infrastructure architecture plays a major role in determining workload economics.
Traditional infrastructure environments often combine separate virtualization, storage, networking, monitoring, backup, and orchestration platforms. While this approach offers flexibility, it can also increase operational complexity, encourage overprovisioning, and create management overhead.
As a result, many organizations are moving toward more integrated infrastructure models, including hyperconverged infrastructure (HCI) and software-defined platforms that consolidate multiple functions into a unified operational framework.
The goal is not merely consolidation. The real objective is to reduce operational overhead, improve resource utilization, simplify scaling, and lower long-term total cost of ownership.
This becomes particularly important for sovereign cloud initiatives. Unlike hyperscalers that benefit from massive global scale, regional cloud providers often need to achieve competitive economics within a specific country or market while maintaining local data residency, compliance, and operational control. In these environments, maximizing infrastructure efficiency is often critical to long-term profitability.
Infrastructure Efficiency Metrics Worth Tracking
Organizations evaluating infrastructure efficiency should look beyond traditional utilization metrics and monitor indicators that directly affect workload economics, including:
- Cost per virtual machine
- Cost per container
- Cost per Kubernetes cluster
- Cost per AI workload
- Storage efficiency ratios
- Power consumption per workload
- Administrator-to-server ratio
- Workload deployment times
- Mean time to resolution (MTTR)
- Resource utilization across compute and storage environments
These metrics provide a more accurate view of infrastructure performance than hardware utilization alone.
Why AI Changes the Equation
The emergence of AI workloads has made infrastructure efficiency even more important.
GPU resources are expensive, but GPUs alone do not determine the economics of AI infrastructure. Storage performance, networking efficiency, workload orchestration, and operational processes all directly impact GPU utilization and overall service profitability.
In many environments, the challenge is no longer acquiring GPUs. It ensures that the surrounding infrastructure can keep them fully utilized.
As GPU, storage, and power costs continue to rise, organizations are increasingly focused on maximizing the value extracted from every infrastructure resource. AI infrastructure economics are becoming less about acquiring the largest amount of hardware and more about achieving the highest utilization and operational efficiency from existing investments.
Measuring Infrastructure Economics
One of the challenges with infrastructure efficiency is that it often remains invisible until it is measured.
Many organizations focus on software licensing when evaluating infrastructure costs, but licensing is only one part of the equation. Utilization rates, storage efficiency, operational overhead, power consumption, hardware refresh cycles, staffing requirements, and SLA commitments often have a much greater impact on long-term economics.
This is why Total Cost of Ownership (TCO) modeling is becoming increasingly important. Effective infrastructure evaluations should account for:
- Software costs
- Hardware acquisition
- Energy consumption
- Colocation expenses
- Storage efficiency
- Staffing requirements
- Operational complexity
- Support and maintenance costs
Organizations that perform these broader analyses often discover that the greatest opportunities for savings come not from individual licensing decisions but from improving overall workload economics.
Conclusion
The next phase of cloud infrastructure optimization is unlikely to be driven by capacity growth alone.
As infrastructure costs continue to rise and customer expectations continue to increase, providers must focus on delivering more workloads with fewer resources while maintaining performance and service quality.
In that environment, infrastructure efficiency becomes more than a technical objective. It becomes a business metric.
The organizations that can achieve the lowest cost per workload delivered at a defined service level will be best positioned to protect margins, remain competitive, and build sustainable cloud and AI services for the future.
Opinions expressed by DZone contributors are their own.
Comments