Benchmarking Open-Source LLMs: LLaMA vs Mistral vs Gemma — A Practical Guide for Developers Building Private Models
Open-source LLMs like LLaMA, Mistral, and Gemma are reshaping private AI. Learn their performance, architecture, and deployment to choose the right model.
Join the DZone community and get the full member experience.
Join For FreeLarge language models (LLMs) have transitioned from research labs into the everyday workflows of companies worldwide. While tools like GPT-4 and Claude often steal the spotlight, they come with restrictions such as API rate limits, opaque model behavior, and privacy concerns.
This has led to the rise of open-source LLMs like Meta’s LLaMA, Mistral AI’s Mistral, and Google’s Gemma. These models allow developers to build and deploy powerful AI applications without relying on third-party APIs, offering transparency, flexibility, and cost control.
In this article, we will dive into a comparative analysis of these three models, exploring their architectural differences, real-world performance benchmarks, and suitability for various use cases. Whether you're a solo developer building a chatbot or an enterprise architect designing a secure AI assistant, this breakdown will help inform your decision.
Why These Models Matter
We chose LLaMA, Mistral, and Gemma for this comparison because they represent the most active, well-supported, and performant open-source models currently available.
| Model | Released By | License Type | Parameter Size | Language Support | Highlights |
|---|---|---|---|---|---|
| LLaMA 2 | Meta | Open (w/ terms) | 7B / 13B / 70B | Multilingual | Scalable, widely adopted |
| Mistral | Mistral AI | Apache 2.0 | 7B | English-focused | Fast, compact, and cost-efficient |
| Gemma | Google DeepMind | Apache 2.0 | 2B / 7B | Multilingual | Aligned for tasks, TPU/GPU ready |
All three models are production-ready, have active ecosystems, and can run with modern ML tools like Hugging Face, vLLM, and ONNX. They also support quantized formats like GGUF, making them more deployable on commodity hardware. This is crucial for organizations looking to control costs while maintaining local ownership of data pipelines.
Inside the Models: Architectural Walkthrough
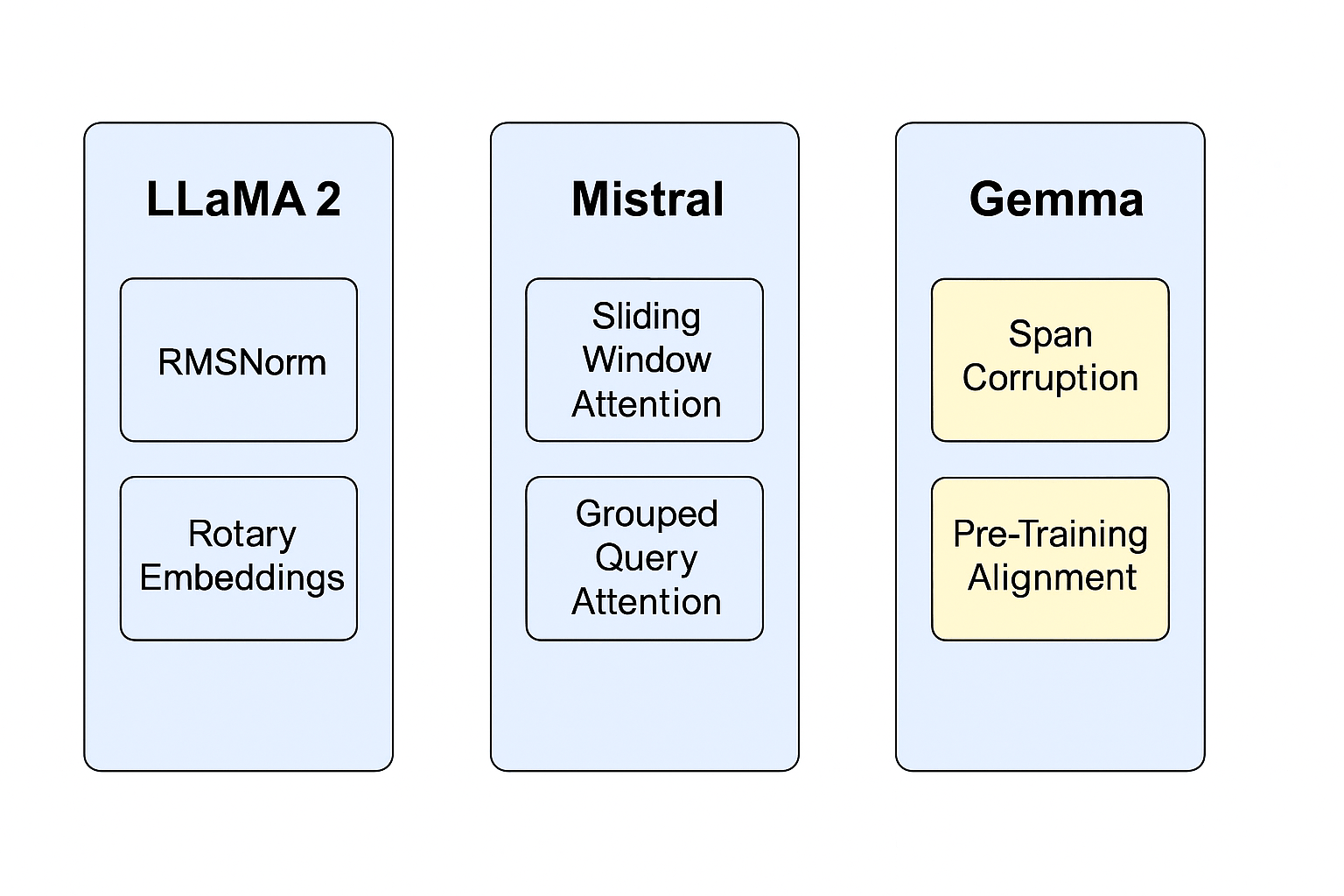
LLaMA 2
Meta’s LLaMA 2 improves on classic transformer design with:
- RMSNorm for more stable training: This normalization technique helps stabilize the training process, leading to more reliable model performance.
- Rotary Positional Embeddings (RoPE) for long sequence handling: RoPE allows the model to handle longer sequences more effectively, improving its ability to understand and generate coherent text over extended contexts.
- A training mix including code, math, and multilingual content: This diverse training data enables LLaMA 2 to perform well across a wide range of tasks and languages.
Its large-scale variants (13B and 70B) make it suitable for advanced reasoning tasks, document generation, and multilingual support. It’s particularly valuable in settings where community extensions and pretrained variations (like CodeLLaMA) are beneficial.
Mistral 7B
Mistral packs incredible performance in a small footprint:
- Sliding Window Attention reduces memory use and speeds up processing: This attention mechanism allows the model to focus on relevant parts of the input sequence, reducing memory usage and improving processing speed.
- Grouped Query Attention (GQA) increases parallelism: GQA enables the model to process multiple queries simultaneously, increasing its throughput and efficiency.
- Outperforms some 13B models despite being 7B in size: Mistral’s efficient design allows it to achieve performance comparable to larger models, making it a cost-effective choice.
Its modular and efficient design makes it highly deployable on devices with limited resources. Developers building AI agents for edge computing, like voice assistants or on-device summarizers, will appreciate Mistral’s low memory consumption and high throughput.
Gemma 7B
Gemma is engineered for instruction-following and language understanding:
- Leverages UL2-style span corruption rather than simple autoregressive training: This training approach helps the model better understand and generate coherent text by focusing on corrupted spans within the input.
- Pre-aligned and instruction-tuned for chat, search, and Q&A: Gemma is designed to follow instructions and perform well in conversational and question-answering contexts.
- Plays well with Google Cloud TPUs and Nvidia GPUs: Gemma’s architecture is optimized for these hardware platforms, making it a good choice for deployments on Google Cloud or Nvidia-based systems.
This architecture allows Gemma to excel in contexts requiring clarity, empathy, and structured output—like educational tutors, wellness advisors, or personalized search assistants.
Benchmarking Setup
We used the following test setup for fairness and reproducibility:
- GPU: NVIDIA A100 80GB
- Frameworks: Hugging Face Transformers + vLLM
- Tasks: Text Generation, Summarization, Question Answering
- Context length: 2048 tokens
- Batch size: 4
These metrics simulate mid-sized production environments, such as internal chatbots or automated content systems serving 10–50 requests per minute.
Inference Speed (tokens/sec)
| Model | Text Gen | QA | Summarization |
|---|---|---|---|
| LLaMA 2 | 29.2 | 28 | 26.5 |
| Mistral | 41.5 | 39 | 37.8 |
| Gemma | 36.0 | 35 | 34.5 |
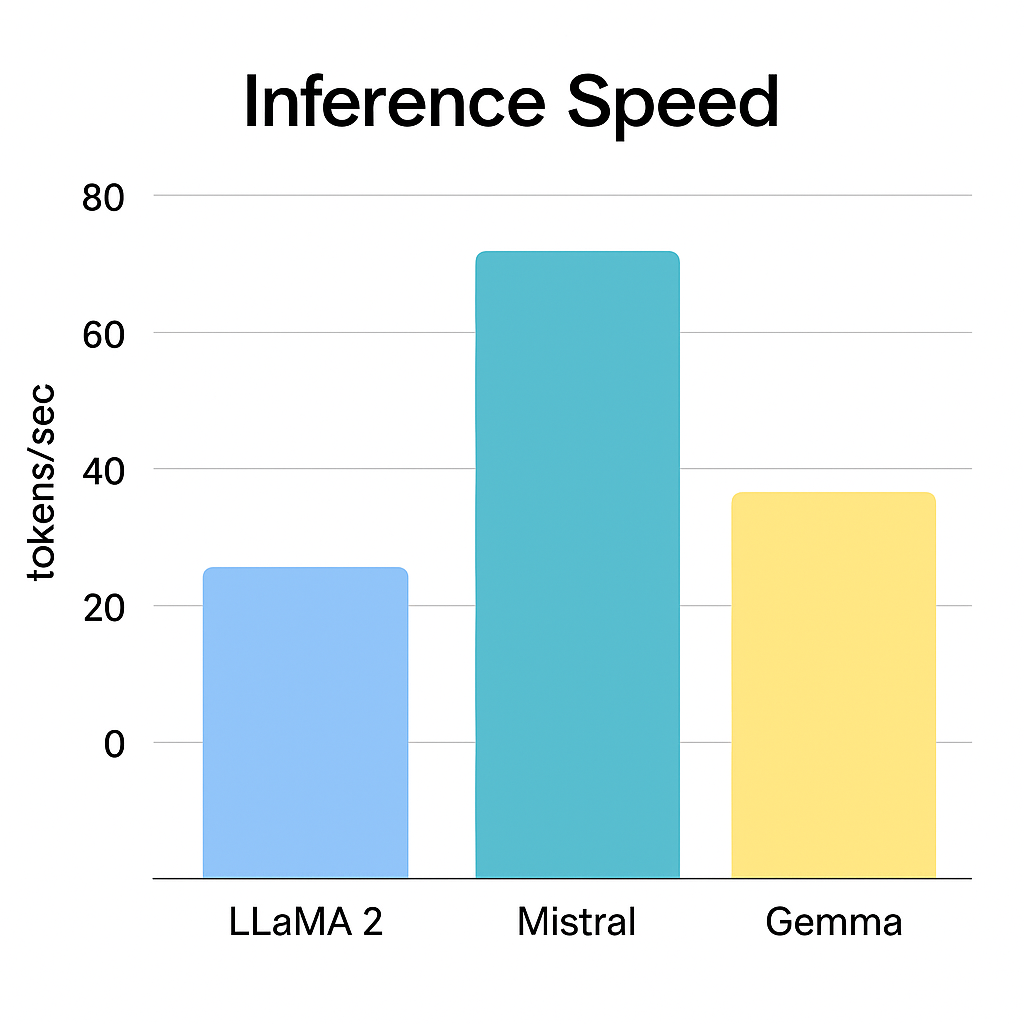
Mistral leads in speed, which is especially relevant for latency-sensitive applications like voice agents, trading assistants, or customer-facing bots with <500ms response targets.
Fine-Tuning and Customization Options
If you’re working with proprietary data, fine-tuning your model is a must. All three models support modern fine-tuning techniques like:
- LoRA (Low-rank adaptation): Allows small and fast updates to the model, making it easier to adapt to specific tasks or domains.
- QLoRA: Enables fine-tuning on consumer-grade GPUs, reducing the hardware requirements for customization.
- PEFT (Parameter-efficient fine-tuning): Hugging Face’s plug-and-play system for efficient fine-tuning, allowing domain adaptation with as few as 500–1000 training samples.
Popular enterprise use cases:
- Legal: Contract review bots that highlight risk clauses
- Healthcare: Diagnostic assistants that summarize patient records
- Retail: Product Q&A systems customized by catalog metadata
These approaches significantly lower the barrier to LLM customization and allow domain adaptation with minimal training data.
Instruction Following and Reliability
| Criteria | LLaMA 2 | Mistral | Gemma |
|---|---|---|---|
| Instruction Compliance | ✅ | ✅ | ✅✅ |
| Answer Formatting | ✅ | ✅ | ✅✅ |
| Logical Reasoning | ✅ | ✅✅ | ✅ |
| Hallucination Resistance | ✅ | ✅ | ✅✅ |
While all three perform well, Gemma’s pre-tuned alignment gives it an advantage for enterprise use cases where consistency and formatting matter. For example, a legal chatbot generating a numbered list of clauses will likely perform better with Gemma than Mistral out of the box.

Ecosystem Support and Tooling
| Feature | LLaMA 2 | Mistral | Gemma |
|---|---|---|---|
| Hugging Face | ✅ | ✅ | ✅ |
| GGUF Format | ✅ | ✅ | ✅ |
| ONNX Export | ✅ | ✅ | ❌ |
| vLLM Support | ✅ | ✅ | ✅ |
| TGI Ready | ✅ | ✅ | ✅ |
Note: ONNX support matters if you're planning to export to lightweight runtimes or mobile platforms. Gemma’s lack of mature ONNX support may limit portability — though Google may improve this over time.
Example Deployment Stack: Legal Assistant Chatbot
Let’s say you’re building a chatbot for a legal team with strict compliance needs:
- Local inference only
- Deep reasoning with citations
- Fast and accurate
Suggested stack:
- Model: Mistral 7B (fine-tuned with QLoRA)
- Serving layer: vLLM or Text Generation Inference (TGI)
- Frontend: Streamlit or LangChain-based UI
- RAG system: FAISS for document retrieval + LLM reranking
- Monitoring: Prometheus + OpenLLMetry for observability
This setup delivers low-latency, private LLM access that respects governance policies while offering tailored performance.
Which Model Is Right for You?
| Use Case | Best Fit |
|---|---|
| Real-time chatbots | Mistral 7B |
| Instruction following | Gemma 7B |
| Broad ecosystem/tools | LLaMA 2 |
| On-device deployments | Mistral 7B |
| Community support | LLaMA 2 |
TL;DR Decision Aid
- Speed-sensitive? → Go Mistral
- Precision-critical? → Go Gemma
- Tooling-first? → Go LLaMA
Each model is better suited to a particular trade-off triangle: performance, alignment, and tooling. Choose based on the pillar your use case cannot compromise on.
Final Thoughts
The open-source LLM landscape is maturing quickly. With options like LLaMA, Mistral, and Gemma, developers now have powerful alternatives to closed models. Each brings a unique mix of benefits:
- LLaMA: Best for general-purpose tasks with strong community backing
- Mistral: Perfect for latency-sensitive and cost-efficient deployments
- Gemma: Aligned and structured, great for Q&A and assistant-style agents
Ultimately, there is no universal winner, but there’s likely a clear winner for your unique context. Treat open-source LLMs as building blocks — not silver bullets — and you’ll be on a solid path.
Resources for Further Exploration
Opinions expressed by DZone contributors are their own.
Comments